







概要:
希尔排序(Shell's Sort)是插入排序的一种又称“缩小增量排序”,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
-
1,插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率。(这是为啥呢?点击去看看),
-
2,但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位。
基本思想:
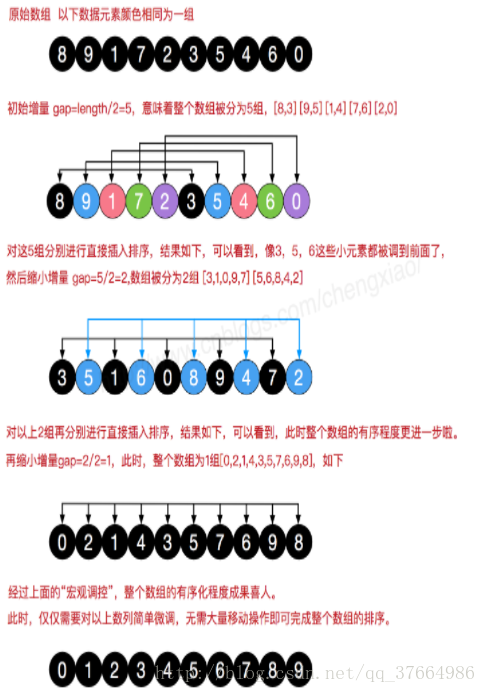
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量
为1
,即所有记录放在同一组中进行直接插入排序为止。
该方法实质上是一种分组插入方法;一般的初次取序列的一半为增量,以后每次减半,直到增量为1。
如图(声明下图实在网上找到的,他画得好):
代码:
void ShellSort2(int arr[], int n) {
int tab = n / 2;//初始增量
while (tab >= 1) {
//对每组进行分组
for (int i = 0; i < tab; i++) {
//arr[i],arr[i+tab],arr[i+2*tab].....进行插入排序
for (int j = i + tab; j < n; j += tab) {
int k;
T e = arr[j];
for (k = j; k >= tab&& e<arr[k - tab]; k -= tab)
arr[k] = arr[k - tab];
arr[k] = e;
}
}
tab /= t;
}
}
对希尔排序增量的讨论:
这里添加三个方法:generaRandomArray:生成随机数组,copyArray:复制数组,testSort:测试运行时间
//生成n个的随机数组,,每个元素的范围{RangeL,RangeR}
int * generateRandromArray(int n, int rangel, int rangeR) {
int *arr = new int[n];
srand(time(0));
for (int i = 0; i < n; i++) {
arr[i] = rand() % (rangeR - rangel + 1) + rangel+1;
}
return arr;
}
//数组赋值
int * copyArray(int arr[], int n) {
int * temp = new int[n];
for (int i = 0; i < n; i++)
temp[i] = arr[i];
return temp;
}
void testSort(string sortName, void(*sort)(int[], int n, int t), int arr[], int n, int t) {
clock_t startTime = clock();//开始时间
sort(arr, n, t);//运行函数
clock_t endTime = clock();//结束时间
cout << sortName << ":" << double(endTime - startTime) / CLOCKS_PER_SEC<<" s" << endl;//打印时间
}并把上述希尔排序的函数该为一下代码,方便更改增量:
void ShellSort2(T arr[], int n,int t) {//t表示初始增量
int tab = n / t;
while (tab >= 1) {
//对每组进行分组
for (int i = 0; i < tab; i++) {
//arr[i],arr[i+tab],arr[i+2*tab].....进行插入排序
for (int j = i + tab; j < n; j += tab) {
int k;
T e = arr[j];
for (k = j; k >= tab&& e<arr[k - tab]; k -= tab)
arr[k] = arr[k - tab];
arr[k] = e;
}
}
tab /= t;
}
}
int main() {
int n = 1000000;
int *arr = generateRandromArray(n, 0, n);//生成随机数组
int *arr1,*arr2,*arr3,*arr4,*arr5;
//复制数组
arr1 =copyArray(arr, n);
arr2 =copyArray(arr, n);
arr3 =copyArray(arr, n);
arr4 =copyArray(arr, n);
arr5 =copyArray(arr, n);
testSort("希尔排序 2 :", ShellSort2, arr, n, 2);
testSort("希尔排序 3 :", ShellSort2, arr1, n, 3);
testSort("希尔排序 4 :", ShellSort2, arr2, n, 4);
testSort("希尔排序 5 :", ShellSort2, arr3, n, 5);
testSort("希尔排序 10 :", ShellSort2, arr4, n, 10);
testSort("希尔排序100 :", ShellSort2, arr5, n, 100);
return 0;
}运行结果:
为了对比,我多运行几次,随机取三个结果。
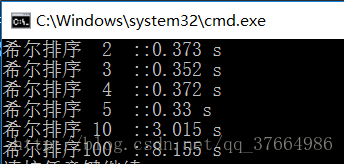
结果1:
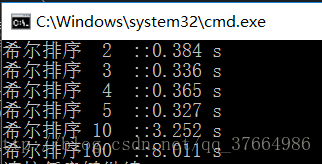
结果2:
结果3:
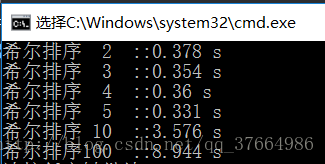
通过三次对比发现,当增量为5的时候效率是最好的。这个也说不准,反正5过后,10,100,效率就原来越低,这也说明了希尔排序是插入排序的一种“缩小增量的排序”。
希尔排序与插入排序的对比:
利用上述代码,用100000数据量(上面是1000000),把增量改变为n(就是插入排序了)与增量为5的希尔排序做对比:
代码:
int main() {
int n = 1000000;
int *arr = generateRandromArray(n, 0, n);//生成随机数组
int *arr1,*arr2,*arr3,*arr4,*arr5;
//复制数组
arr1 =copyArray(arr, n);
arr2 =copyArray(arr, n);
arr3 =copyArray(arr, n);
testSort("希尔排序 n :", ShellSort2, arr, n, n);
testSort("希尔排序 5 :", ShellSort2, arr3, n, 5);
return 0;
}
look! 多少倍,自己体会吧
总结:
好好领悟,多练习!















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









