






前言
本来不值得写这篇博客,但是运行官方demo时,出现了各种奇奇怪怪的报错,觉着有必要记录下
一、streamlit运行脚本
注意到文件web_demo_streamlit.py,通过streamlit命令能够可视化模型推理过程,运行命令
streamlit run .\basic_demo\web_demo_gradio.py
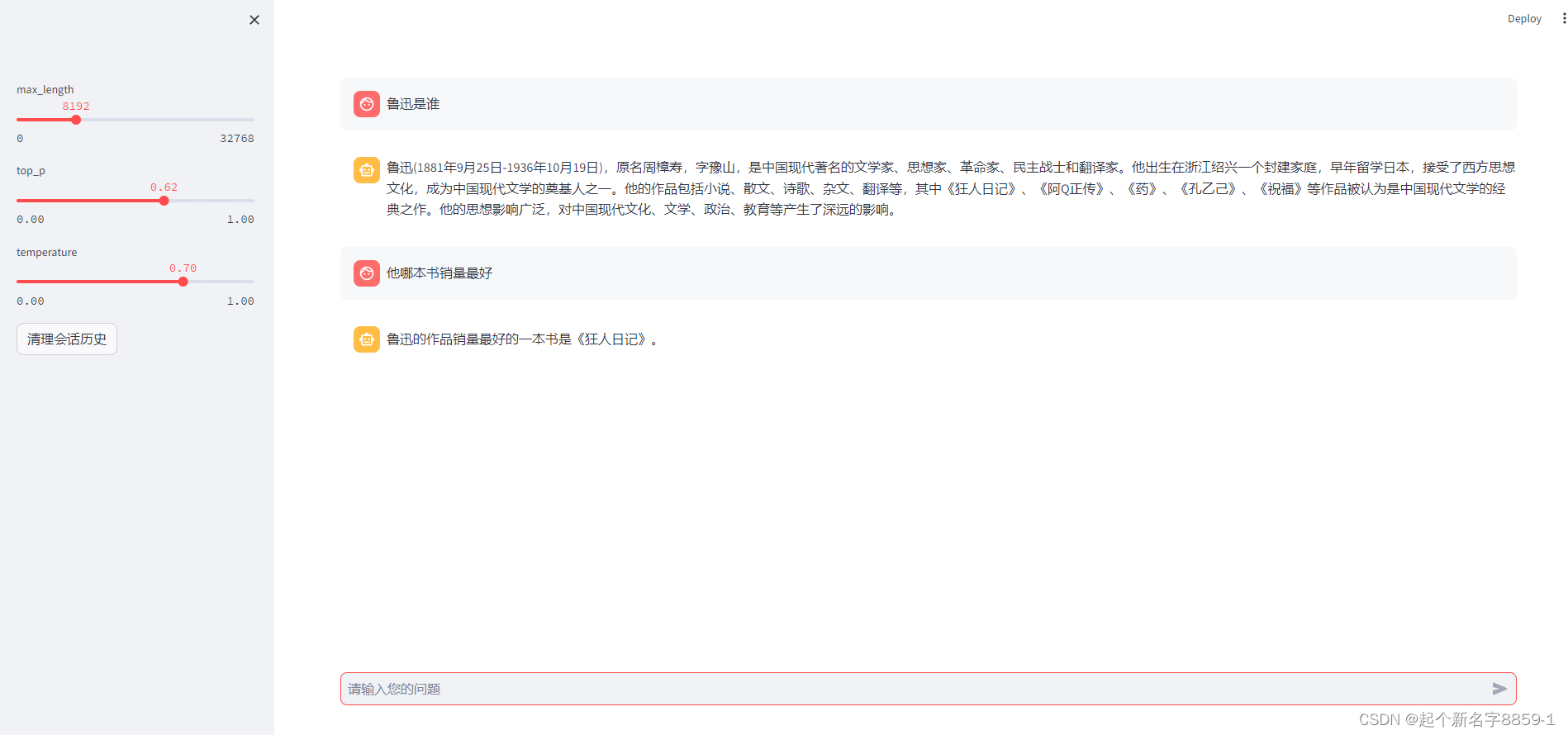
二、模型参数
max_length
- 控制文本最大生成的token数,避免产出过长文本。
top_p
- 控制输出token在最有可能的top_p范围内。假设top_p = 0.1,模型会依据累计概率,在token池中选择概率最高的10%的token作为预备输出。top_p越大,阈值放得更宽,备选token基数更多,更具多样性;反之阈值收得更窄,备选token基数更少,多样性降低。
- 举个例子,如果选去吃饭的10家店,按概率顺排:(老乡鸡、胡子大厨、…、杨国福),如果top_p=0.1,那么生成的很有可能就是老乡鸡。为什么说很可能,而不是一定,假设吃饭提议服从先来后到原则,已经选定10家店(胡子大厨、…、杨国福、大米先生),这时再有人提议吃老乡鸡,该店无法再入选了。
temperature
- 控制输出token本身的概率分布,赋予不同token生成的可能性。区别于top_p根据阈值的大小控制多样性,temperature通过调整概率分布,让一些本不太可能生成的词,也得到了生成的机会,增加了不可预测性。
- 举个例子,如果永远都是(老乡鸡、胡子大厨、…、杨国福、大米先生)这些店,选择未免太单调,缺乏了随机性和多样性,假如突然有人提议吃路边的煎饼果子,没准大伙真就考虑吃它了。
三、报错解决
问题1
- TypeError: WebSocketHandler.init() missing 2 required positional arguments: ‘application’ and ‘request’
解决方案
- 看异常栈,来自tonado库web.py文件中的super().init(),源码中注释掉该行即可。
问题2
- 官方给的样例在执行第二轮对话就开始报错
解决方案
- 其实没太搞懂demo无法开箱即用的原因,可能是依赖版本问题。反正代码逻辑比较简单,自己改了改
import os
import streamlit as st
import torch
from transformers import AutoModel, AutoTokenizer
MODEL_PATH = os.environ.get('MODEL_PATH', 'E:/Agi/chatglm-6b')
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)
st.set_page_config(
page_title="ChatGLM3-6B Streamlit Simple Demo",
page_icon=":robot:",
layout="wide"
)
@st.cache_resource
def get_model():
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)
# model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True, device_map="auto").half().eval()
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True).half().quantize(bits=4,
device="cuda").cuda().eval()
return tokenizer, model
# 加载Chatglm3的model和tokenizer
tokenizer, model = get_model()
if "history" not in st.session_state:
st.session_state.history = []
if "past_key_values" not in st.session_state:
st.session_state.past_key_values = None
max_length = st.sidebar.slider("max_length", 0, 32768, 8192, step=1)
top_p = st.sidebar.slider("top_p", 0.0, 1.0, 0.8, step=0.01)
temperature = st.sidebar.slider("temperature", 0.0, 1.0, 0.6, step=0.01)
buttonClean = st.sidebar.button("清理会话历史", key="clean")
if buttonClean:
st.session_state.history = []
st.session_state.past_key_values = None
if torch.cuda.is_available():
torch.cuda.empty_cache()
st.rerun()
for message in st.session_state.history:
for i, content in enumerate(message):
if i == 0:
with st.chat_message(name="user", avatar="user"):
st.markdown(content)
else:
with st.chat_message(name="assistant", avatar="assistant"):
st.markdown(content)
with st.chat_message(name="user", avatar="user"):
input_placeholder = st.empty()
with st.chat_message(name="assistant", avatar="assistant"):
message_placeholder = st.empty()
prompt_text = st.chat_input("请输入您的问题")
if prompt_text:
input_placeholder.markdown(prompt_text)
history = st.session_state.history
line = ''
for response, history in model.stream_chat(
tokenizer,
prompt_text,
history,
max_length=max_length,
top_p=top_p,
temperature=temperature,
return_past_key_values=True,
):
message_placeholder.markdown(response)
line = response
st.session_state.history.append((prompt_text, line))















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









