









 本文介绍人脸识别中常用数据集,如MS1M-ArcFace、LFW等,并详细讲解基于MXNet的图像数据预处理流程,包括图像裁剪、校正及.rec文件制作。
本文介绍人脸识别中常用数据集,如MS1M-ArcFace、LFW等,并详细讲解基于MXNet的图像数据预处理流程,包括图像裁剪、校正及.rec文件制作。
一、前言
这部分主要讲训练数据的制作。一是我们直接采用作者提供好的数据集,二就是制作我们自己所需要的数据集。
目录地址:insightface人脸识别代码记录(总)(基于MXNet)
二、主要内容
1、首先,我们来提供作者的数据集。
这是作者提供的地址:https://github.com/deepinsight/insightface/wiki/Dataset-Zoo
比较推荐的是MS1M-ArcFace (85K ids/5.8M images) [5,7]
下面简单介绍下常用的人脸识别数据集:
MS-Celeb-1M
MS1M数据集包含有大约10万个人的脸(大约有1千万张人脸),但是数据集中包含有很多的“噪声”。Arcface论文作者对MS1M做了数据清洗,最终作者清洗得到的干净的数据包含有8.5万个人的脸(包含有380万张人脸)。
LFW
全名是Labeled Faces in the Wild.这个数据集是人脸评估一定会用到的一个数据集,包含了来自1680的13000张人脸图,数据是从网上搜索来的。基本都是正脸。这个数据集也是最简单的,基本主流算法都能跑到99%以上,貌似有6对label错了,所以最高正确率应该是99.9%左右。这个都跑不到99%的话别的数据集表现效果会更差。一般来说这个数据集是用来做人脸识别验证的。
CelebFaces
总共包含10177个人的202599张图片,也是从搜索引擎上爬过来的,噪声不算多,适合作为训练集。同时这个数据对人脸有一些二元标签,比如是否微笑,是否戴帽子等。
CASIA-WebFace
该数据集是从IMBb网站上搜集来的,含10K个人的500K张图片。同时做了相似度聚类来去掉一部分噪声。CAISA-WebFace的数据集源和IMDb-Face是一样的,不过因为数据清洗的原因,会比IMDb-Face少一些图片。噪声不算特别多,适合作为训练数据。
MegaFace
MegaFace数据集包含有69万个人的脸(包含大约有100万张人脸),所有数据由华盛顿大学从Flickr上组织收集。MegaFace是第一个在百万规模级别的面部识别算法的测试基准,这个项目旨在研究当数据库规模提升数个量级时,现有的脸部识别系统能否维持可靠的准确率。MegaFace是目前最为权威、最热门的评价人脸识别性能,特别是海量人脸识别检索性能的基准参照之一。
CFP
CFP(Celebrities in Frontal Profile )数据集是美国名人的人脸数据集,其中包含有500个人物对象,有他们的10张正面照以及4张形象照,因此在作为人物比对验证的时候,作者选用了最有挑战的正面照与形象照作为验证集(CFP,Frontal-Profile,CFP-FP )。
AgeDB
AgeDB(Age Database )数据集包含有440个人的脸(包含有12240张人脸),但其中包含有不同人的不同年龄阶段的照片,最小从3岁到最大101岁时期的照片,每个对象的平均年龄范围为49年。作者采用和LFW一样的对比验证方式。
2、接下来,介绍如何制作自己的数据集。
MXNet读取数据有两种方式:
①直接读取原图像,即采用.lst文件和原图像方式
②采用MXNet特有的数据读取方式,RecordIO文件,即.rec文件
这里我们采用第二种方式,基于.rec文件文件。这种方式优点是读取速度快,数据文件稳定。
首先,人脸的裁剪和校正。
因为之前我学习的是Retinaface,所以采用此人脸检测模型。下面结合代码进行记录。下面align.py是我参考insightface下deploy/face_model.py和src/common/face_preprocess.py整合起来的代码。具体一些细节在代码记录。
align.py:
import cv2
import os
import numpy as np
from skimage import transform as trans
from PIL import Image
#test_fddb.py这个脚本,见我的整理的项目地址。位于insightface人脸识别代码记录(总)(基于MXNet)中。
from test_fddb import detect
#这里是一个简单的由路径读取图片的方法
def read_image(img_path, **kwargs):
mode = kwargs.get('mode', 'rgb')
layout = kwargs.get('layout', 'HWC')
if mode=='gray':
img = cv2.imread(img_path, cv2.CV_LOAD_IMAGE_GRAYSCALE)
else:
img = cv2.imread(img_path, cv2.CV_LOAD_IMAGE_COLOR)
if mode=='rgb':
#print('to rgb')
img = img[...,::-1]
if layout=='CHW':
img = np.transpose(img, (2,0,1))
return img
#这个方法是核心。就是根据检测
def preprocess(img, bbox_list=None, landmark_list=None, **kwargs):
#这是存放校正后图像的一个列表
warped_list = list()
#一张图片上可能存在多个人脸,即有多个bbox和关键点信息,需要分别进行裁剪和校正
for bbox,landmark in zip(bbox_list,landmark_list):
if isinstance(img, str):
img = read_image(img,bbox, **kwargs)
M = None
image_size = []
#对裁剪后图像大小的控制112*112
str_image_size = kwargs.get('image_size', '')
if len(str_image_size)>0:
image_size = [int(x) for x in str_image_size.split(',')]
if len(image_size)==1:
image_size = [image_size[0], image_size[0]]
assert len(image_size)==2
assert image_size[0]==112
assert image_size[0]==112 or image_size[1]==96
#src存放着标准关键点信息所在的位置
if landmark is not None:
assert len(image_size)==2
src = np.array([
[30.2946, 51.6963],
[65.5318, 51.5014],
[48.0252, 71.7366],
[33.5493, 92.3655],
[62.7299, 92.2041] ], dtype=np.float32 )
#这里这个+8么太明白是什么原理...(有知道的小伙伴希望可以评论留言)
if image_size[1]==112:
src[:,0] += 8.0
dst = landmark.astype(np.float32)
#创建相似变换矩阵
tform = trans.SimilarityTransform()
#根据标准关键landmark和所得到的landmark来计算得到变换矩阵
tform.estimate(dst, src)
#提供给后面仿射变换函数使用。因为仿射变换只涉及旋转和平移,所以只需要矩阵中的前两个参数
#dst(x,y)=src(M11x+M12x+M13,M21x+M22y+M23)
M = tform.params[0:2,:]
#这个是变换矩阵不存在的情况下,暂时不做讨论
if M is None:
if bbox is None: #use center crop
det = np.zeros(4, dtype=np.int32)
det[0] = int(img.shape[1]*0.0625)
det[1] = int(img.shape[0]*0.0625)
det[2] = img.shape[1] - det[0]
det[3] = img.shape[0] - det[1]
else:
det = bbox
margin = kwargs.get('margin', 44)
bb = np.zeros(4, dtype=np.int32)
bb[0] = np.maximum(det[0]-margin/2, 0)
bb[1] = np.maximum(det[1]-margin/2, 0)
bb[2] = np.minimum(det[2]+margin/2, img.shape[1])
bb[3] = np.minimum(det[3]+margin/2, img.shape[0])
ret = img[bb[1]:bb[3],bb[0]:bb[2],:]
if len(image_size)>0:
ret = cv2.resize(ret, (image_size[1], image_size[0]))
return ret
else: #do align using landmark
assert len(image_size)==2
#然后调用opencv中的放射变换得到校正后的人脸
warped = cv2.warpAffine(img,M,(image_size[1],image_size[0]), borderValue = 0.0)
warped_list.append(warped)
return warped_list
def Align(img_path):
#调用retinaface中的人脸检测器,得到bbox和landmark坐标信息
_ret = detect(img_path)
#因为上述得到的一个list,list[0]存放了人脸的信息,list[1]是其所在路径
ret = _ret[0]
#将人脸置信度抽取出来,进行一个筛选。因为在检测器中进行过sort,得到的
#置信度高的人脸位于前面,所以当出现第一个小于阈值的情况,后面便均小于。
scores = ret[:,4]
index = list()
for i in range(len(scores)):
if scores[i]>0.5:
index.append(i)
else:
break
bbox = ret[index,0:4]
points_ = ret[index,5:15]
points = points_.copy()
#因为得到的landmark是(x1,y1,x2,y2....)这种形式,需要变换成(x1,x2,...y1,y2....)这种形式
points[index,0:5:1] = points_[index,0::2]
points[index,5:10:1] = points_[index,1::2]
if bbox.shape[0]==0:
return None
#将上述得到的bbox和landmark信息分别存放到如下list
points_list = list()
bbox_list = list()
for i in range(len(index)):
point = points[i,:].reshape((2,5)).T
bbox_ = bbox[i]
points_list.append(point)
bbox_list.append(bbox_)
#points = points.reshape((len(index),2,5)).transpose(0,2,1)
face_img = cv2.imread(img_path)
#调用此方法,得到裁剪和校正过的人脸
nimg_list = preprocess(face_img, bbox_list, points_list, image_size='112,112')
#一张图片存在多张人脸,分别裁剪校正
aligned_list = list()
for _,nimg in enumerate(nimg_list):
nimg = cv2.cvtColor(nimg, cv2.COLOR_BGR2RGB)
aligned = np.transpose(nimg, (2,0,1))
aligned_list.append(aligned)
return aligned_list
if __name__ == "__main__":
# path = './data/widerface/train/images/7--Cheering/7_Cheering_Cheering_7_321.jpg' #单人脸
# path1 = './data/widerface/train/images/4--Dancing/4_Dancing_Dancing_4_317.jpg' #多人脸
path = 'F:\Project\insightface-master\deploy\img'
#os.walk()返回三个参数:
# ①root,所在路径,即输入path
# ②dirs,所在路径下的文件夹
# ③files,所在路径下的文件
for root, dirs, files in os.walk(path):
for dir in dirs:
img_root = os.path.join(root, dir)
images = os.listdir(img_root)
for image in images:
path = os.path.join(img_root,image)
print(path)
out_list = Align(path)
for i,out in enumerate(out_list):
new_image = np.transpose(out, (1, 2, 0))[:, :, ::-1]
out = Image.fromarray(new_image)
out = out.resize((112, 112))
out = np.asarray(out)
#对所得到的人脸进行和原所在文件夹和命名的区别
if not os.path.exists(os.path.join(root,'_'+dir)):
os.mkdir(os.path.join(root,'_'+dir))
#采用原图像名字和i命名,i表示这张图片中的第几个人脸
cv2.imwrite(os.path.join(root,'_'+dir,str(image[0:-4])+'_'+str(i)+'.jpg'),out)
print('over!')
# cv2.imshow("out",out)
# cv2.waitKey()
以下是效果图:

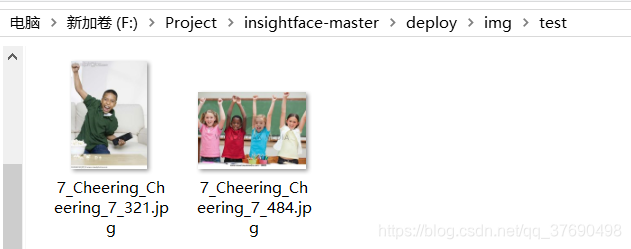

然后,制作.rec文件。
我们来到https://github.com/apache/incubator-mxnet/blob/master/tools/im2rec.py下载得到im2rec.py脚本。
首先制作.lst文件,输入以下命令:
python im2rec.py /data/train data/train --list --recursive
①第一个/data/train,这个路径是prefix的意思,代表会在data目录下生成一个train.lst的文件。
②第二个/data/train,是路径root的意思,代表图片所在路径。
③--list 代表生成lst文件的操作。因为默认生成RecordIO文件。
④-- recursive代表迭代搜索给定的目录因为此目录下可能存在多个类别的文件夹。
接着,输入以下命令,得到.rec文件:
python im2rec2.py --num-thread 4 data/train.lst data/train
①--num-thread用于设置线程数,加快生成.rec文件
② data/train.lst代表生成的.lst文件所在的位置
③ data/train代表原图像所在的位置
最后生成的.rec文件会默认保存在和.lst文件相同的目录下,同时会生成一个.idx的文件,对数据做随机排序有关。
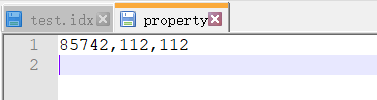
最后,我们制作property配置文件。
直接创建一个名为property的文件,没有后缀
写xxx,112,112代表ID数量,尺寸,尺寸。
例:
三、结尾
到这里就结束了。对MXNet的数据准备有了一些了解,同时学习了几个常用的人脸识别的数据集。上述一些数据集的介绍,来自于一些其他博主的博客作为记录,所以想在这里写下,下面附上参考链接。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









