







一、C++/C
移动语义
左值右值
左值一般是可寻址的变量,右值一般是不可寻址的字面常量或者是在表达式求值过程中创建的可寻址的无名临时对象;
凡是真正的存在内存当中,而不是寄存器当中的值就是左值,其余的都是右值
凡是取地址(&)操作可以成功的都是左值,其余都是右值
左值具有持久性,右值具有短暂性。
移动拷贝赋值
对于右值的拷贝和赋值会调用转移构造函数和转移赋值操作符。如果转移构造函数和转移拷贝操作符没有定义,那么拷贝构造函数和赋值操作符会被调用。
编译器只对右值引用才能调用转移构造函数和转移赋值函数
std::move,函数将左值引用转换为右值引用
指针传参
修改实参,指针传参仍然是拷贝,改变不了原指针的值,也就是地址,但是地址里放的东西可以改
引用传参
修改实参,可以避免拷贝,当函数无需修改实参的值使用引用传参。使用引用避免拷贝
void reset(int &i);
int i=0;
reset(i);返回值
- 不能返回局部变量的引用或者指针,就是函数的返回值是引用类型,函数的返回值是引用类型就无需拷贝
- 如果返回值是引用类型,则可以做左值
getval(s, 0) = 'A';//getval()返回类型为char &
返回拷贝的值将不会对原来的值做改变
类与对象
析构函数
1. 多态性质的基类的析构函数最好定义为虚函数,因为可能会这种情况:
基类指针指向派生类对象,调用析构函数的时候会造成“局部销毁”,因为他只会调用基类的析构函数,派生类的部分不会被销毁
继承一个带有non-virtual 析构函数的class (比如所有STL容器)不应该的
2. 析构函数中如果调用了其他函数,这个函数可能会发生异常,应该捕获异常。不然就可能会发生内存泄漏。
继承
关系的类型转换
派生类的对象拷贝、赋值、移动给基类对象,到那时只能处理基类范围内的部分
多态
如果子类和父类定义了同名成员函数,用指针调用成员函数时,到底调用那个函数要根据指针的原型来确定,而不是根据指针实际指向的对象类型确定。
基类指针或引用可以指向派生类对象,但派生类指针或引用不能指向基类对象
如果以一个基类指针指向一个派生类对象,那么经由该指针只能访问基类定义的函数
静态多态和动态多态,静态多态主要是重载,在编译的时候就已经确定;动态多态是用虚函数机制实现的,在运行期间动态绑定
虚函数
虚函数是基类希望子类将函数覆盖,定义为虚函数,使用virtual,当指针或者引用调用该虚函数将发生动态绑定,动态绑定就是根据绑定的对象类型来调用对应的函数(注意动态绑定只有通过引用或者指针调用时才会触发)。即 虚函数是为了让父类指针或引用可以调用子类的方法,不一定不能被实现,纯虚函数才是不能被实现,但子类必须有实现。
此外,子类再覆盖基类的虚函数时形参列表和返回类型都必须保持一致
构造函数和析构函数中不要掉用虚函数
纯虚函数(抽象类)
c++的类中存在纯虚函数,那么该类就变成抽象类。抽象类不能被实例化。
纯虚函数无需定义,只需要声明 `doubel net_price (int) cosnt = 0`即可
虚表
在有虚函数的类中,每一个类如果有虚函数就会有一个虚表,类的最开始部分是一个虚函数表的指针,指向一个虚函数表。当类的对象在创建时便拥有了这个指针,且这个指针的值会自动被设置为指向类的虚表。
虚表是一个指针数组,表中放了虚函数的地址,实际的虚函数在代码段(.text)中。当子类继承了父类的时候也会继承其虚函数表,当子类重写父类中虚函数时候,会将其继承到的虚函数表中的地址替换为重新写的函数地址。使用了虚函数,会增加访问内存开销,降低效率
虚函数指针的赋值发生在编译器的编译阶段,也就是说在代码的编译阶段,虚表就可以构造出来了。
接口 是特殊的抽象类,满足(1) 类中没有定义任何成员变量 (2) 类中所有成员函数都是公有且都是纯虚函数
override
覆盖,重写 。C++11的关键字,基类的虚函数指针没有被派生类覆盖(目的是希望派生类重写对应的虚函数,但由于不小心写错了参数),导致通过基类指针调用了基类的虚函数,而不是派生类对应的函数
联合体 union
联合体中的所有成员是共享一段内存的,因此每个成员的存放首地址相对于于联合体变量的基地址的偏移量为0,即所有成员的首地址都是一样的。
其大小必须满足两个条件:1)大小足够容纳最宽的成员;2)大小能被其包含的所有基本数据类型的大小所整除。
this 指针
其作用就是指向成员函数所作用的对象,所以非静态成员函数中可以直接使用 this 来代表指向该函数作用的对象的指针。
每个成员函数的第一个参数默认都有个指向对象的 this 指针,隐式参数,传入对象的地址
this指针是不能改变的
new
在堆上申请内存,返回地址,用指针来接收。new底层也是通过malloc实现的,在堆上保存。
C++ new 的用法 (总结)_xiaorenwuzyh的专栏-CSDN博客
`A *obj = new A();`是最简单的用法,这个new 的功能是 1. 分配空间, 2 调用构造函数
这两个功能也分别都是不同的new实现,他们都是new,注意辨别
1. operator new 分配空间,全局函数,在#include<new>
// 全局 operator new
#include <new>
void * operator new(std::size_t size) throw(std::bad_alloc) {
if (size == 0)
size = 1;
void* p;
while ((p = ::malloc(size)) == 0) { //采用 malloc 分配空间
std::new_handler nh = std::get_new_handler();
if (nh)
nh();
else
throw std::bad_alloc();
}
return p;
}2. placement new 在一个 已经分配好的空间上,调用构造函数
#include <new>
void *buf = // 在这里为buf分配内存
class *pc = new (buf) Class();
//栈内存也可以使用placement new
class A {int a;}
int buf[sizeof(A)]; //在栈上,分配一个数组
A *obj = new(buf) A(); //在这个数组上构造一个 对象 A。C++内存管理
-
栈:是分配给函数局部变量的存储单元,函数结束后,该变量的存储单元自动释放,效率高,分配的空间有限。向上生长
-
堆:由malloc创建,由free释放的动态内存单元。如果用户不释放该内存,程序结束时,系统会自动回收。堆通常存在栈的下方(低地址方向),在某些时候,堆也可能没有固定统一的存储区域。堆一般比栈大很多,可以有几十至数百兆字节的容量。向下生长。
-
(自由存储区:由new创建,由delete释放的动态内存单元,其实就是堆?(不确定)。)逻辑概念
-
全局(静态)存储区:全局变量和静态变量占一块内存空间。
-
常量存储区:存储常量,内容不允许更改。
局部变量的声明只是规定了变量的类型和名字,并没由申请存储空间。
段错误发生的可能原因:访问非法内存地址的时候,例如使用野指针、修改字符串常量
内存泄漏
1. 堆内存泄漏 (Heap leak)。对内存指的是程序运行中根据需要分配通过malloc,realloc new等从堆中分配的一块内存,再是完成后必须通过调用对应的 free或者delete 删掉。如果程序的设计的错误导致这部分内存没有被释放,那么此后这块内存将不会被使用,就会产生Heap Leak.
2. 系统资源泄露(Resource Leak)。主要指程序使用系统分配的资源比如 Bitmap,handle ,SOCKET等没有使用相应的函数释放掉,导致系统资源的浪费,严重可导致系统效能降低,系统运行不稳定。
3. 没有将基类的析构函数定义为虚函数。当基类指针指向子类对象时,如果基类的析构函数不是virtual,那么子类的析构函数将不会被调用,子类的资源没有正确是释放,因此造成内存泄露。
字节对齐
-
数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在 offset 为0的地方,以后每个数据成员存储的起始位置要从该成员大小或者成员的子成员大小(只要该成员有子成员,比如说是数组,结构体等)的整数倍开始(比如int在32位机为4字节,则要从4的整数倍地址开始存储。
-
结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储。(struct a里存有struct b,b里有char,int ,double等元素,那b应该从8的整数倍开始存储。)
-
struct sizeof的结果,必须是其内部最大成员的整数倍,不足的要补齐。
static 关键字
- 静态变量位于静态存储区;未经初始化的全局静态变量会被自动初始化为0;
- 局部静态变量的作用域仍为局部作用域,当定义它的函数或者语句块结束的时候,作用域结束。但是当局部静态变量离开作用域后,并没有销毁,而是仍然驻留在内存当中,只不过我们不能再对它进行访问,直到该函数再次被调用,并且值不变
- 类静态成员 实现多个对象之间的数据共享,此变量/函数就没有了this指针了,必须通过类名才能访问
- 全局静态变量 加了static关键字的全局变量只能在本文件中使用,可隐藏变量
静态成员函数不能使用this指针(this指针指向当前对象)并且不能被定义为const
使用类的静态成员:①作用域运算符 `::` ②对象或指针或引用 ③成员函数可以直接使用,不通过①②
非静态成员函数可以任意地访问静态成员函数和静态数据成员,静态成员函数不能访问非静态成员函数和非静态数据成员,但可以传参访问
static的作用
1、作用域隐藏。当一个工程有多个文件的时候,用static修饰的函数或变量只能够在本文件中可见,文件外不可见。
2、全局生命周期。用static修饰的变量或函数生命周期是全局的。被static修饰的变量存储在静态数据区。
3、static修饰的变量默认初始化为0.
4、static修饰的变量或函数是属于类的,所有对象只有一份拷贝。
没初始化的未定义的全局变量存储在 .bss 区,这个区域不会占用可执行文件的空间(一般只存储这个区域的长度),但是却会占用内存空间。这些变量没有定义,因此可执行文件中不需要存储它们的值,在程序启动过程中,它们的值会被初始化成 0 ,存储在内存中。
extern关键字
用来指示变量或函数的定义在别的文件中,使用 extern 可以在多个源文件中共享某个变量,例如这里的例子。
声明:当编译器被告知变量存在时,就声明了一个变量;此时它不会为变量分配存储空间`int a;`
定义:编译器为变量分配存储空间时被定义
模版
模版实例化,模版函数是调用的时候才会去实例化
强制转换 cast
向上转换也可以应用于对象之间
- const_cast 常量指针被转化成非常量的指针,并且仍然指向原来的对象;常量引用被转换成非常量的引用,并且仍然指向原来的对象
- dynamic_cast 只能用于含有虚函数的类,用于类层次间的向上和向下转化(指针和引用)
-
static_cast 用于各种隐式转换,比如非const转const,void*转指针等, static_cast能用于多态向上转化(子类向基类的转换),如果向下转能成功但是不安全,结果未知
对象初始化
第一种方式是显式的调用构造函数。(在栈上分配内存)
A a = A();
A a = A(1);
另一种方式是隐式的调用构造函数,格式更紧凑。(在栈上分配内存)
A a; // 等价于 A a = A();
A a(1); // 等价于 A a = A(1);
构造函数还可以与new一起使用。(在堆中动态分配内存)
A *a = new A(); // 记得要 delete a;
A *a = new A(1); // 记得要 delete a;智能指针
智能指针是一个类,当超出了类的作用域,会自动调用析构函数,析构函数会自动释放资源。所以智能指针的作用原理就是在函数结束时自动释放内存空间,不需要手动释放内存空间。
unique_ptr
保证同一时间内只有一个智能指针可以指向该对象
shared_ptr
实现共享式拥有概念。多个智能指针可以指向相同对象,该对象和其相关资源会在“最后一个引用被销毁”时候释放。它使用计数机制来表明资源被几个指针共享。
weak_ptr
指向一个 shared_ptr 管理的对象,解决shared_ptr相互引用时的死锁问题
i++ 和 ++i
//++i
int& int::operator++(){
*this += 1;
return *this;
}
//i++
const int int::operator++(int){
int old = *this;
++(*this);
return old;
}vector
vector初始化
-
vector<int> ilist1;vector为空, size为0,没有分配内存空间 -
vector<int> ilist3(ilist.begin()+2,ilist.end()-1); -
vector<int> ilist = {1};vector<int> ilist2(ilist); -
vector<int> ilist5(7,3);初始化一个长度为7,初始值都为3的vecor
vector拷贝
temlist.assign(list.begin(), list.end()); 原数组不变
temlist.swap(list); 原数组空了
二、STL容器
关联容器
底层均是红黑树实现RB Tree
hashtable
通过把关键码值映射到表中一个位置来访问记录,哈希函数和冲突解决
冲突解决的办法:线性探测、二次探测、开链
开链
为每个 Hash 值建立一个单链表,当发生冲突时,将记录插入到链表中
三、网络
五层模型
物理层、数据连路层、网络层、传输层、应用层
所有套接字默认是阻塞IO
文件描述符读就绪条件
-
socket通信对方关闭连接,socket读操作返回0
-
监听socket有新的连接
-
socket内核接受缓冲区字节数> 低水位标记
-
socket有未知错误
TCP
可靠性:编号、确认机制、校验和、重传
TCP KeepAlive 的基本原理是,隔一段时间给连接对端发送一个探测包,如果收到对方回应的 ACK,则认为连接还是存活的,在超过一定重试次数之后还是没有收到对方的回应,则丢弃该 TCP 连接。但是连接的存活不一定代表服务的可用,当一个服务器 CPU 进程服务器占用达到 100%,已经卡死不能响应请求了,此时 TCP KeepAlive 依然会认为连接是存活的,这种情况会在应用层实现自己的心跳功能
应用程序判断对方是否关闭连接 read 返回 0
客户端通过connetct()主动和服务器建立连接,发送三次握手的第一个SYN同步报文,如果收到服务器的SYN同步确认报文,connetct()成功返回,进入ESTABLISHED状态。失败原因可能有两个:
-
服务器端口不存在,或者端口被处于
timewait状态的连接占用,服务器返回RST报文 -
没有收到服务器的确认
timewait的存在的原因:
-
保证连接正确关闭
-
保证迟来的TCP报文丢弃
RST报文段 是 访问不存在端口、异常终止连接、处理半打开连接
HTTP
HTTP 请求报文结构:
HTTP 报文大致可分为请求行、请求头、空行、请求主体四部分。通常,前几部分是必有的,最后的请求体不是必有的,每个部分结尾都用空行来作为结束标志。
HTTP 响应报文结构:
状态行、请求头、空行、请求主体。状态行(status line)通过提供一个状态码来说明所请求的资源情况
IO复用
同时监听多个文件描述符,直到有文件描述符上有事件发生返回。
select 没有将fd和事件绑定,需要提供可读、可写、异常三种类型的事件,仅仅是一个文件描述符集合(fd_set),内核会对fd_set进行修改,下次调用需要重置
poll poll_fd将文件描述符和事件绑定在一起,无需重置
epoll 用一个额外的文件描述符在内核中维护一个事件表。应用程序索引就绪文件描述符的复杂度为O(1)
select 和poll都是使用轮询,eppll_wait使用回调

四、数据结构
AVL Tree 和RB Tree 都是平衡二叉搜索树
红黑树
-
根结点是黑
-
红节点的儿子必须是黑
-
任意节点到NULL的任何路径包含的黑节点数量一样
五、操作系统
LRU cache 最近最久未使用
双向链表 + hash表 (双向链表保存cache的具体内容,hash表索引key和链表节点,通过key找到节点)
进程和线程
线程
cpu调度的最小单位,同一程序内共享内存地址的一组,还可以共享打开文件 etc
从内核的角度来说并没有线程这个概念,在linux中是共享资源的一种手段,没有特定的调度算法和数据机构来实现线程
线程间通信
线程间的通信目的主要是用于线程同步
- 锁
- 信号量
- 信号
- wait notify
死锁
- 同一个进程申请同一个锁。看到同一个进程多次acquire同一个锁,就会触发一个panic
- 多个锁 deadly embrace。 对锁排序
虚拟内存
实现进程间的隔离性。地址空间,每个进程包括内核和用户进程都运行在自己的地址空间(0-x)
页表 提供虚拟地址到物理地址的映射
下图是xv6的内核地址空间和物理内存的映射图
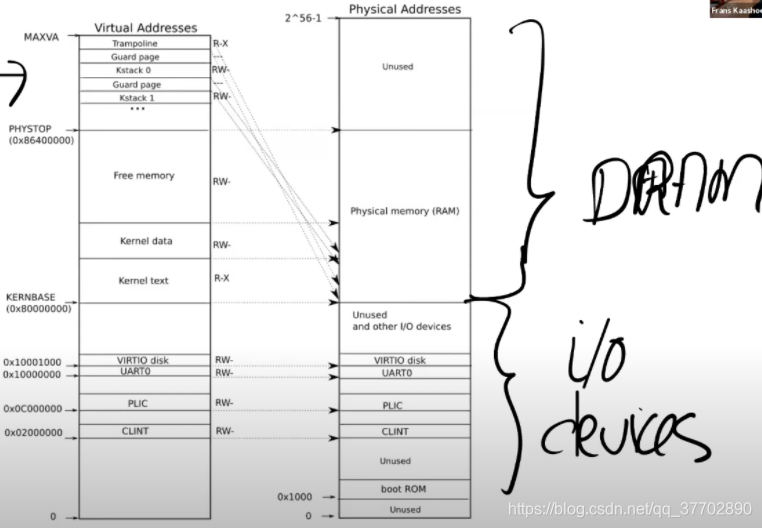
当你对主板上电,主板做的第一件事情就是运行存储在boot ROM中的代码,当boot完成之后,会跳转到地址0x80000000,启动操作系统。
0x0200000到0x10001000这些都是和设备的映射,直接与设备进行交互。0x80000000以上的物理地址对应DRAM芯片
用户进程使用的就是 Free memory 对应的Physcial memory中的物理地址。
下图为用户进程地址空间

在xv6中,kernel中的main函数调用kvminit初始化内核页表,在kvminit中将设备、kernel text、kernel data、Free merory 调用kvmmap进行映射
kvminithart设置satp寄存器保存内核一级页表(物理)地址,然后开启paging 。在开启之前代码中使用的都是物理地址。
walk函数根据一个va得到指向对应的三级页表的pte的指针
supervisor mode 权限
读写控制寄存器,例如satp、sepc、stvec
可以使用PTE_U为0的paeg
supervisor mode中并不能读写任意物理地址,也需要通过page table来访问内存
用户空间和内核空间的切换 trap
-
程序执行系统调用
-
程序出现了类似page fault、运算时除以0的错误 异常错误
-
一个设备触发了中断使得当前程序运行需要响应内核设备驱动
-
保护用户寄存器、pc
-
切换mode
-
修改
satp,指向内核页表 -
切换堆栈,因为要调用内核的c函数
那系统调用举例:
-
ecall指令会进入supervisor mode,将pc保存在spec寄存器里(ecall指令的(虚拟)地址),stvec寄存器的值拷贝到pc,跳转到trampoline page(stvec指向trap代码起始地址)。但页表还是用户页表,没有包含任何内核部分的地址映射,这里既没有对于kernel data的映射,也没有对于kernel指令的映射,ecall指令不会改变页表和用户寄存器。 -
进入trampoline page,这个page包含了内核的trap处理代码,执行
uservec。-
XV6内核在每个user page table映射了trapframe page,并且trampoline代码在用户空间和内核空间都映射到了同一个地址,可以用来保存用户寄存器的32个空槽位;trapframe page的(虚拟)地址保存在了
sscratch寄存器中。保存用户寄存器到trampoline page中 -
加载内核栈指针kernel_sp
-
加载
usertrap函数地址,这是内核代码 -
加载内核页表到
satp -
跳到
usertrap
-
-
usertrap修改stvec寄存器,将trap代码地址修改的kerneltrap-
保存
spec到trapfram page中,因为可能发生:程序还在内核中执行时,切换到另一个进程,并进入到那个程序的用户空间,然后那个进程可能再调用一个系统调用进而导致SEPC寄存器的内容被覆盖 -
对上一步保存的用户程序计数器加4
-
调用
syscall函数和usertrapret
-
-
usertrapret函数,来设置在返回到用户空间之前内核要做的工作-
往trapframe page 中 存储内核页表的指针、当前用户进程的kernel stack栈指针kernel_sp、usertrap函数的指针。下一次从用户空间转换到内核空间时可以用到这些数据
-
从tp寄存器中读取当前的CPU核编号,并存储在trapframe中,这样trampoline代码才能恢复这个数字,因为用户代码可能会修改这个数字
-
把
usertrap函数中设置的epc 拷贝到sepc寄存器里 因为只有trampoline中代码是同时在用户和内核空间中映射 -
计算userret地址并跳转userret汇编代码,userret接受两个参数保存在a0和a1中,一个是TRAPFRAME,另一个是用户一级页表地址
-
-
userret恢复·satp为用户根页表,恢复之前进程的用户寄存器,交换sscratch和a0,a0保存的是trapframe地址,sscratch保存的系统调用的返回值。最后sret-
切换回user mode
-
SEPC寄存器的数值会被拷贝到PC寄存器(程序计数器)
-
重新打开中断
-
自旋锁
硬件原子指令 amoswap addr r1 r2 atomic memory swap 。这个指令将addr的值放到临时变量tmp中,在把r1写到addr中,最后把tmp写到r2中。
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
uint n;
uint nts;
};
acquire()函数获取锁,函数就是不断查看locked变量是否是0,如果是0置1返回。但是可能会引起竞争,因为可能两个进程会同时看到locked == 0
核心语句 __sync_lock_test_and_set(&lk->locked, 1) != 0 这个函数是C标准库实现的一个原子操作。对应刚才那个指令
// Acquire the lock.
// Loops (spins) until the lock is acquired.
void acquire(struct spinlock *lk)
{
push_off(); // disable interrupts to avoid deadlock.
if(holding(lk))
panic("acquire");
__sync_fetch_and_add(&(lk->n), 1);
// On RISC-V, sync_lock_test_and_set turns into an atomic swap:
// a5 = 1
// s1 = &lk->locked
// amoswap.w.aq a5, a5, (s1)
while(__sync_lock_test_and_set(&lk->locked, 1) != 0) {
__sync_fetch_and_add(&lk->nts, 1);
}
// Tell the C compiler and the processor to not move loads or stores
// past this point, to ensure that the critical section's memory
// references happen strictly after the lock is acquired.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Record info about lock acquisition for holding() and debugging.
lk->cpu = mycpu();
}
release 释放锁 也同样用了amoswap即__sync_lock_release(&lk->locked); 是原子操作
// Release the lock.
void release(struct spinlock *lk)
{
if(!holding(lk))
panic("release");
lk->cpu = 0;
// Tell the C compiler and the CPU to not move loads or stores
// past this point, to ensure that all the stores in the critical
// section are visible to other CPUs before the lock is released,
// and that loads in the critical section occur strictly before
// the lock is released.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Release the lock, equivalent to lk->locked = 0.
// This code doesn't use a C assignment, since the C standard
// implies that an assignment might be implemented with
// multiple store instructions.
// On RISC-V, sync_lock_release turns into an atomic swap:
// s1 = &lk->locked
// amoswap.w zero, zero, (s1)
__sync_lock_release(&lk->locked);
pop_off();
}
线程调度
出让CPU涉及到很多步骤,我们需要将进程的状态从RUNNING改成RUNABLE,我们需要将进程的寄存器保存在context对象中,并且我们还需要停止使用当前进程的栈。所以这里至少有三个步骤,而这三个步骤需要花费一些时间。所以锁的第一个工作就是在这三个步骤完成之前,阻止任何一个其他核的调度器线程看到当前进程。锁这里确保了三个步骤的原子性。从CPU核的角度来说,三个步骤要么全发生,要么全不发生。
线程切换的过程
-
一个进程出于某种原因想要进入休眠状态,比如说出让CPU或者等待数据,它会先获取自己的锁;
-
之后进程将自己的状态从RUNNING设置为RUNNABLE;
-
之后进程调用
swtch函数,其实是调用sched函数在sched函数中再调用的swtch函数; -
swtch函数将当前的线程切换到调度器线程; -
调度器线程之前也调用了
swtch函数,现在恢复执行会从自己的swtch函数返回; -
返回之后,调度器线程会释放刚刚出让了CPU的进程的锁
禁止在调用swtch时持有除进程自身锁(注,也就是p->lock)以外的其他锁
sleep
两个参数,一个tx_channel, 需要一个锁使用作为参数传入
释放作为第二个参数传入的锁,这样中断处理程序才能获取锁
xv6的设计是某个cpu获取锁将会禁用中断发生
如果中断处理程序使用了自旋锁,则 CPU 绝不能在启用中断的情况下保持该锁,因为可能会发生死锁
释放锁的时候会打开中断
因为释放锁会打开中断,防止在释放锁和在修改进程SLEEPING这个间隙wakeup被调用唤醒进程,所以获取即将进入SLEEPING状态的进程的锁。
void sleep(void *chan, struct spinlock *lk) {
struct proc *p = myproc();
// Must acquire p->lock in order to
// change p->state and then call sched.
// Once we hold p->lock, we can be
// guaranteed that we won't miss any wakeup
// (wakeup locks p->lock),
// so it's okay to release lk.
if(lk != &p->lock){ //DOC: sleeplock0
acquire(&p->lock); //DOC: sleeplock1
release(lk);
}
// Go to sleep.
p->chan = chan;
p->state = SLEEPING;
sched();
// Tidy up.
p->chan = 0;
// Reacquire original lock.
if(lk != &p->lock){
release(&p->lock);
acquire(lk);
}
}
-
调用sleep时需要持有condition lock,这样sleep函数才能知道相应的锁。
-
sleep函数只有在获取到进程的锁p->lock之后,才能释放condition lock。
-
wakeup需要同时持有两个锁才能查看进程。(这个意思是在
uartintr中)

修复了lost wakeup问题
wakeup
查看整个进程表单,对于每个进程首先加锁,这点很重要。之后查看进程的状态,如果进程当前是SLEEPING并且进程的channel与wakeup传入的channel相同,将进程的状态设置为RUNNABLE。最后再释放进程的锁。
void wakeup(void *chan) {
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == SLEEPING && p->chan == chan) {
p->state = RUNNABLE;
}
release(&p->lock);
}
}
exit
设置进程状态为ZOMBIE,并将该进程拥有的子进程的父进程设置为init进程
资源释放是在父进程的wait中完成
进程退出不是exit单独完成,需要和wait配套完成。在Unix中,对于每一个退出的进程,都需要有一个对应的wait系统调用
通常情况下,一个进程exit,它的父进程正在wait。
wait
如果一个进程exit了,并且它的父进程调用了wait系统调用,父进程的wait会返回。wait函数的返回表明当前进程的一个子进程退出了
for循环一直扫描进程表单,找到父进程是自己且状态是ZOMBIE的进程。这些进程已经在exit中几乎要执行完了。之后由父进程调用的freeproc释放进程资源
父进程释放完资源,子进程的状态设为UNUSED
kill
扫描进程表单,找到目标进程。将进程的proc结构体中killed标志位置1。如果进程正在SLEEPING状态,将其设置为RUNNABLE。这里并没有停止进程的运行
而目标进程运行到内核代码中能安全停止运行的位置时,会检查自己的killed标志位,如果设置为1,目标进程会自愿的执行exit系统调用。
被kill的进程如果在用户空间,那么下一次它执行系统调用它就会退出,又或者目标进程正在执行用户代码,当时下一次定时器中断或者其他中断触发了,进程才会退出。所以从一个进程调用kill,到另一个进程真正退出,中间可能有很明显的延时
对于SLEEPING状态的进程如果kill了会被直接唤醒,包装了sleep的循环会检查进程的killed标志位,最后再调用exit。例如下面的代码
// pipe.c int piperead(struct pipe *pi, uint64 addr, int n)
while(pi->nread == pi->nwrite && pi->writeopen){ //DOC: pipe-empty
if(myproc()->killed){
release(&pi->lock);
return -1;
}
sleep(&pi->nread, &pi->lock); //DOC: piperead-sleep
}
Mysql
事务
- acid
- 事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行
- 脏读、幻读、不可重复读
实现事务:日志、锁、MVCC
- 事务的原子性是通过 undo log 来实现的
- 事务的持久性性是通过 redo log 来实现的
- 事务的隔离性是通过 (读写锁+MVCC)来实现的
隔离级别
存储引擎 MySQL 索引结构 - rickiyang - 博客园
数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行增删改查。 插件式存储引擎
InnoDB
mysql的默认引擎,支持事务安全表(提交、回滚和崩溃恢复能力)(ACID),支持行锁定和外键,在主内存中缓存数据和索引而维持它自己的缓冲池
数据都是存储在磁盘的数据页中
MyISAM
有较高的插入、查询速度,但不支持事务。
MyISAM 使用 B+ 树作为索引存储结构,叶子节点 data 域存放的是数据的物理地址,即索引结构和真正的数据结构其实是分开存储的。
B+树
- B+ 树的非叶子节点不保存数据,只有索引,所以查询次数都是一致的,查询效率较稳定
- 节点的子树数和关键字数相同(B 树是关键字数比子树数少一);
- 所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针(节点的关键字表示的是子树中的最大数,在子树中同样含有这个数据),且叶子结点本身依关键字的大小自小而大的顺序链接。 (而 B 树的叶子节点并没有包括全部需要查找的信息);
- 所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而 B 树的非终节点也包含需要查找的有效信息)。
- 叶子节点之间通过指针连接















 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









