










总结一下 O/S 课程里面和锁相关的内容. 本文是 6.S081 课程的相关内容总结回顾结合 Real World 的 Linux 讲解各种锁和 RCU lock free 机制原理, 前置知识是基本的操作系统知识以及部分组成原理知识:线程与并发的概念, 中断与管态用户态概念, 以及基本的并发编程锁模型如读写锁等和部分数据结构. 最好掌握的:高速缓存一致性协议,CPU 乱序执行,内存屏障。
RCU 部分涉及的论文和扩展阅读:
RCU Usage In the Linux Kernel: One Decade Later ,Paul E. McKenney,Jonathan Walpole
https://www.kernel.org/doc/Documentation/RCU/whatisRCU.txt
What is RCU, Fundamentally? [LWN.net]
自旋锁
自旋锁 spinlock,是一种通过积极浪费 CPU cycles 来做 busy-looping 来轮询抢占共享数据结构的一种锁。
共享数据结构的一致性(为什么要做锁?)
对于 shared data structure, 需要保证读写的 critical section 时具备 consistency, 特别是读的时候, 不希望读到一个不完整的数据或者数据结构的不完整的结构. 比如一个链表在多个线程的读写过程中可能会出现的混乱的指针.
单核本来就没有并行 (谁需要锁?)
先谈论 single core 的情况, 我们只需要通过关中断 就可以实现 sequential access, 具体的思想实验是如果一个结构正在被某个 thread (这里的 thread 泛指 kernel 编程里面的 process) 占用, 我们希望他处理结束之后再 context switch, 这样实际上不会出现共享访问, 也就是没有并行(对于共享结构本身就希望访问并行的序列化). 也就是 local_irq_disable() 和 preempt_disable() 就能实现了. 某个数据结构一开始是未 locked 的, 一旦 locked 了就关闭 timer interrupt, 从而保证了在本线程结束前后的数据一致性.
多核争用时自旋等待 (多核怎么做锁?)
对于 multicore 的情况, 则需要考虑更多, 对于一个数据结构, 一旦他已经被一个 core 给 lock 了, 当前运行在另一个 core 上的 thread 就需要等待锁释放, 所以需要一个循环等待的过程, 叫做自旋. 具体实现的关键部分是通过 CPU 提供的一种 swap 指令, 在 RISC-V 上这个指令是 amoswap, 其功能是执行一个原子操作的读出值和放入新值. 这样只需要把 true 旋进去, 拿出来的如果是 true, 说明本来就被锁了, 放个 true 进去不改变原始值, 如果拿出来是 false 说明当前 thread/core 拿到这个锁. 我们看 xv6 里面的实现:
void
acquire(struct spinlock *lk)
{
push_off(); // disable interrupts to avoid deadlock.
if(holding(lk))
panic("acquire");
// On RISC-V, sync_lock_test_and_set turns into an atomic swap:
// a5 = 1
// s1 = &lk->locked
// amoswap.w.aq a5, a5, (s1)
while(__sync_lock_test_and_set(&lk->locked, 1) != 0)
;
// Tell the C compiler and the processor to not move loads or stores
// past this point, to ensure that the critical section's memory
// references happen strictly after the lock is acquired.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Record info about lock acquisition for holding() and debugging.
lk->cpu = mycpu();
}其中内存屏障做的事情在编译器上很好理解就算防止编译过程的指令重排导致的持有锁状态更新和锁实际状态的不一致, 而其在 CPU 上其实就是做一个简单的清空流水线, 这一点我们在体系结构课程和 CSAPP 里面的对于简易流水线和 tomasulo 技术相关的地方学习过了. 值得提一下 spinlock 是约定不允许在 context switch (关闭中断后只有 yield() 会引发) 时候持有的, 否则会导致问题如 deadlock(当持有两个锁顺序不同时), 这一点和关中断的原因一样, 显而易见 (会导致别的共享数据结构的线程自旋无法获取到锁).
关中断实现性能保障 (怎么推动尽快释放锁?)
spinlock, 他的 overhead 有内存屏障导致的清空流水线浪费一个流水线长度, 然后主要就是循环等待的不断 CAS 的过程, 还有一个就算这个 amoswap 涉及多核 CPU 的 cache coherence MESI 的东西. 当然这个单核时使用 spinlock 最简单的就算一个退化过程, 不需要单独编写 (Linux 里面对单核 CPU 和多核的方案当然不一样). 他的性能则是由关抢占来保证的, 关中断后能够使需要锁的操作快速运行完, 防止拿到锁后 context switch 出去导致别的线程/核心需要等该核心轮转.
补充一个要点,我后来才注意到 Linux spinlock 的实现:spinlock 持有 lock 之后关了 preempt 不关 interrupt。但是对于某些情况,有一个 irqsave 版本会关。irqsave 版本涉及的要点是:process 和 中断都想获取一个资源的时候,就要 avoid deadlock。
应用层自旋锁
虽然本文主要是讲 Linux 内核中的锁,但是无妨再讲讲应用层的锁的方案。
应用层自旋锁性能捉急 (锁的性能怎么样?)
spinlock 也无法很好地用于应用层, 这是从语言 runtime 角度上看的, 他无法提供一个操作系统关中断的方法, 也就是没有上述代码这种模式中的 push_off() 部分, 回想编写 spinlock 的过程, 我们依据关中断实现序列化, 多核循环等待并且规定 context switch 时不能持有锁来避免死锁. 一些库实现了应用态的 spinlock, 但是没有关中断的操作, 这样的 spinlock 和上述的 spinlock 就不一样了,
我们具体分析就是, 单核和多核下都可以通过 timer interrupt 来避免死锁, 但是由于没有关中断, 从而无法保证需要持有锁的任务会快速完成 (而这个是性能的关键). 即内核态 spinlock 让一些核空转等待,并督促持有核推进当前任务,而应用层 spinlock 只有空转等待,没有督促效应,持锁核很有可能三心二意执行中途其他任务导致等待核持续空转。
应用层自旋锁如何把控性能 (怎么做应用层的锁?)
改进用户态 spinlock 可以参考 nginx 的 ngx_spinlock, 他通过用 ngx_cpu_pause() 来告知处理器优化 spin-wait loop 性能和单核下 ngx_sched_yield() 快速切换 (本段已经说了应用层的 spinlock 和 O/S 层的机制不一样, 所以允许 context switch)。
这里详细讲解一下 nginx 的方案: 首先是 intel 的 PAUSE 指令, 就是spin-wait loop 由于有很多的 hazard 的 load 和 store (至于 CAS 指令是原子的为什么会导致 load 和 store 这一点想一下流水线本质执行的是精简指令就能理解, 具体不深究), 容易使处理器的流水线指令重排机制认为出现 memory order violation, 所以要保证安全就要频繁地清空流水线, pause 能避免大量循环后再 context switch。
但是我们知道现代处理器用了巨量寄存器来进行提前计算,即 tomasulo 是不进行清空的, 我们通过最后指令 retire 之前进行 reorder, 而这个 reorder 本质上是一些逻辑电路在做, 也要占用 CPU cycles, Intel 说会引发 25 倍性能损失, 所以这个 PAUSE 直接让 CPU 执行一些 NOP 类似的效果(好像用 NOP 效果更好), 也就不需要 reorder 的这部分 overhead 了. Intel 还说 busy loop 会导致 CPU 发热功耗增高, 这个涉及具体的 CPU 实现. 第二点是 yield, 也就是提前 yield, 这一点则很好思想实验, 就是提前 timer interrupt 了而已. 博客园知识库还有一篇文章分析了 C runtime 的 spinlock 的改进, 主要是汇编代码, 值得一看 自旋锁spinlock剖析与改进_知识库_博客园 (cnblogs.com).
阻塞锁
我们在体系结构课程中对总线的学习就已经体会到了轮询的用处,但是对一些外设而言,持续地监听他是需要暂停 CPU 的,同样地对于软件而言共享资源长时间的使用轮询来说并不是一个好的分配方案,一种良好的机制就是模仿硬件的中断的做法,实现阻塞的等待支援,等 owner 用完了再通知我起床。
睡眠锁把轮询型转向通知型 (如何去掉循环浪费CPU?)
spinlock 讲到这里了, 所以 busy-wait-loop 就很浪费 CPU cycles, 不止是应用层, kernel 里也一样. 对于长阻塞操作, 我们可以做 sleeplock, sleeplock 具备 sleep() 和 wakeup(), 很明显是需要 O/S 支持的, 所以就是内核下的. 其具体实现很容易思想实验, 我们必须在内核进程 PCB 建立一个 condition 的字段用来存储进程睡在谁上面, 然后就是 sleep syscall trap 进来 RUNNING 变 SLEEP 了. 针对多核对 sleep lock 的问题, 所以 sleeplock 本身以及 process controll block 本身都要受到 spinlock 的保护.
然后我们要明确的是 sleeplock 的 sleep syscall 本身是可以被 preempt 或者其他东西 interrupt 的, 毕竟都在 process 的 kernel space 下了, 不会引发一致性问题, 当然涉及 PCB 和 sleeplock 本身的信息是被 spinlock 锁了的.
sleeplock 是不能在 trap handler 里面用的, 这是因为我们知道 PCB 具备 context, contex 要么是其 kernel space 的要么是 user space 的, 而 trap 的 vector 是在 trampoline 里面 map 来跳转的, handler 要实现调用 sched 还原 context, 其本身是 kernel 的 temp code, 并不具备 context, 更不用说支援多次中断了. 所以也不能使用 sleeplock, 因为 wakeup 一个 process 并不能返回到 handler 的某个 context 里.
// Atomically release lock and sleep on chan.
// Reacquires lock when awakened.
void
sleep(void *chan, struct spinlock *lk)
{
struct proc *p = myproc();
// Must acquire p->lock in order to
// change p->state and then call sched.
// Once we hold p->lock, we can be
// guaranteed that we won't miss any wakeup
// (wakeup locks p->lock),
// so it's okay to release lk.
if(lk != &p->lock){ //DOC: sleeplock0
acquire(&p->lock); //DOC: sleeplock1
release(lk);
}
// Go to sleep.
p->chan = chan;
p->state = SLEEPING;
sched();
// Tidy up.
p->chan = 0;
// Reacquire original lock.
if(lk != &p->lock){
release(&p->lock);
acquire(lk);
}
}
void
acquiresleep(struct sleeplock *lk)
{
acquire(&lk->lk);
while (lk->locked) {
sleep(lk, &lk->lk);
}
lk->locked = 1;
lk->pid = myproc()->pid;
release(&lk->lk);
}
void
releasesleep(struct sleeplock *lk)
{
acquire(&lk->lk);
lk->locked = 0;
lk->pid = 0;
wakeup(lk);
release(&lk->lk);
}Linux 中的 sleeplock —— semaphore (Real Word 分析)
xv6 的 sleeplock 在 linux 内核中是叫做 mutex, 早期只有一个 semaphore (具体两者有一些差异, 主要是互斥数量吧) linux 的 mutex 实现十分的复杂, 涉及多种分类讨论的机制, 如果具体学习很复杂没有 xv6 这个简单. 所以只能看一下 Linux semaphore 的源码了. 因为涉及一个分类讨论的做法,所以回来补充了 mutex 的分析,讲完 semaphore 就讲 mutex。
void __down(struct semaphore* sem)
{
struct task_struct* tsk = current;
DECLARE_WAITQUEUE(wait, tsk); //定义一个"队列项", 等待者是当前进程
tsk->state = TASK_UNINTERRUPTIBLE;
add_wait_queue_exclusive(&sem->wait,
&wait); //把当前进程添加到该信号量的wait queue里.
spin_lock_irq(&semaphore_lock); //抓取"大锁"
sem->sleepers++;
for (;;) {
int sleepers = sem->sleepers;
/*
* Add "everybody else" into it. They aren't
* playing, because we own the spinlock.
*/
if (!atomic_add_negative(sleepers - 1, &sem->count)) { //临睡前最后一次尝试
sem->sleepers = 0;
break;
}
sem->sleepers = 1; /* us - see -1 above */
spin_unlock_irq(&semaphore_lock);
schedule(); //睡眠
tsk->state = TASK_UNINTERRUPTIBLE;
spin_lock_irq(&semaphore_lock);
}
spin_unlock_irq(&semaphore_lock);
remove_wait_queue(&sem->wait, &wait); //取得信号量后, 退出该信号量的等待队列
tsk->state = TASK_RUNNING;
wake_up(&sem->wait);
}可以看到进行了多次尝试, 最后在 schedule() 处进入了睡眠. 一旦恢复 RUNNABLE 并被 schedule 之后, 将会返回到 for 循环下一个迭代中获取锁, 这一点和 xv6 中 acquire 中一个 while 里面 sleep 是一样的代码结构, 当然 wakeup 之后并不一定能获取锁, 很有可能重新进入 sleep, 看谁抢的快了.
Linux 中的 spinlock + sleeplock —— mutex(Real Word 分析)
Linux 的 mutex 则是基本原理和 semaphore 差不多(一个是如其名只能让 0 和 1 的公用即 mutex 互斥,一个则是 Dijkstra 信号量),实现上复杂一些(增加了多路径优化)。
我们将在后面讲 Java 的锁的实现时候看到,对于不同的情况 spinlock 和 阻塞的 sleeplock 的性能效果也不同。尽管是在内核里用锁没有 trap 的开销但仍然由 schedule() 导致的 contex switch,这也是 mutex 的另一个优化点,在具体谈论怎么做时,我们给出一个内核开发锁选用的建议:

图片来自 Linux 内核开发一书。我暂时不了解为什么 semaphore 没有采用这个类似 Java 的缝合优化方案,也许他采用了我没有具体读懂 semaphore 的代码?如果你知道具体情况欢迎评论。以下再给出 Linux kernel 3.3 版本中的 mutex 源码 里获取锁的代码的一个小片段:
 尽管我没有具体截图,但是观看这段注释相信就能想到这接下来的代码是什么了,他甚至不用像 Java 那样先试着 spin 10 次再 sleep,而是直接判断一个锁正在 SMP 机的另一个核上进程持有并运行者,就直接 spin 等待而不是 sleep。当然会有一个疑问,我们的 sleeplock 设计上是 preemp_on 的,不过这一点思想实验也可以解决,只需要在 spin 的循环里面判断 owner switch 出去的话我就 break 从而顺延到普通的 sleeplock 上。所以为什么下文提到的 Java 不采用这种方案呢?可能和虚拟机的多核多线程本质是由操作系统内核调度的有关,尽管可能是一对一的线程模型,但是 Java 并不能了解被调度运行的线程是否真实运行在 CPU 核心上也无法获取 owner 线程是否 Running 的,所以这也是 Java 的线程状态没有 Running 只有 Runnable 的原因吧。
尽管我没有具体截图,但是观看这段注释相信就能想到这接下来的代码是什么了,他甚至不用像 Java 那样先试着 spin 10 次再 sleep,而是直接判断一个锁正在 SMP 机的另一个核上进程持有并运行者,就直接 spin 等待而不是 sleep。当然会有一个疑问,我们的 sleeplock 设计上是 preemp_on 的,不过这一点思想实验也可以解决,只需要在 spin 的循环里面判断 owner switch 出去的话我就 break 从而顺延到普通的 sleeplock 上。所以为什么下文提到的 Java 不采用这种方案呢?可能和虚拟机的多核多线程本质是由操作系统内核调度的有关,尽管可能是一对一的线程模型,但是 Java 并不能了解被调度运行的线程是否真实运行在 CPU 核心上也无法获取 owner 线程是否 Running 的,所以这也是 Java 的线程状态没有 Running 只有 Runnable 的原因吧。
应用层阻塞锁
sleeplock 提供系统调用提高应用层锁性能 (如何让应用层也去掉轮询?)
于是再看到应用层的, 即用户态下可以实现 spinlock, 那么是否可以实现 sleeplock 呢? 答案是否定的, 我们无法在应用层下实现一个需要涉及 PCB 操作的功能. 但是可以在内核下实现 futex 供应用层使用.
linux 下 c runtime 的 pthread_mutex 获取锁分为两阶段,第一阶段在用户态采用spinlock锁总线的方式获取一次锁,如果成功立即返回;否则进入第二阶段,调用系统的futex锁去sleep,当锁可用后被唤醒,继续竞争锁。
这样实现的好处是对于大部分情况, 不需要进入到 kernel space, 直接在 runtime 的 user space 就完成了. 对于确实需要等待的, trap 进 kernel sleep. 主要的 overhead 只是 trap 而已. futex 是给 user program 做 syscall 的这个和 pthread 的用户态 mutex 不一样.
应用层我们可以看 pthread 库下的 mutex 实现原理, 当然这里还涉及 pthread 的实现, 具体就不说了. 主要看这个模式, 是怎么的思想方法. 可以看到死循环里面如果没有拿到锁, 就会通过调用 suspend 来调用 futex 的 syscall trap 进去从而 sleep.
// 阻塞式获取互斥变量
int __pthread_mutex_lock(pthread_mutex_t * mutex)
{
pthread_t self;
while(1) {
acquire(&mutex->m_spinlock);
switch(mutex->m_kind) {
case PTHREAD_MUTEX_FAST_NP:
if (mutex->m_count == 0) {
mutex->m_count = 1;
release(&mutex->m_spinlock);
return 0;
}
self = thread_self();
break;
case PTHREAD_MUTEX_RECURSIVE_NP:
self = thread_self();
// 等于0或者本线程已经获得过该互斥锁,则可以重复获得,m_count累加
if (mutex->m_count == 0 || mutex->m_owner == self) {
mutex->m_count++;
// 标记该互斥锁已经被本线程获取
mutex->m_owner = self;
release(&mutex->m_spinlock);
return 0;
}
break;
default:
return EINVAL;
}
/* Suspend ourselves, then try again */
// 获取失败,需要阻塞,把当前线程插入该互斥锁的等待队列
enqueue(&mutex->m_waiting, self);
release(&mutex->m_spinlock);
// 挂起等待唤醒
suspend(self); /* This is not a cancellation point */
}
}
然而我们实际上应用层用到 涉及 syscall 的sleeplock 的性能是不好的,这是因为这里涉及到 context switch,context switch 不可避免的耗费大量 CPU cycles 去执行 trapframe 保存恢复和 trap handler 的指令上去,而且自从 Meltdown 的 paper 出来后,Linux 也把原来的共享的 pagetable 换成了 KPTI(isolation),从而 syscall 进入的 kernel space context switch 必须连带 flush TLB... (Intel 更新了流水线先检查权限再 load 可能就不用 KPTI 了,不过 AMD 本来就没有 Meltdown 漏洞),而 flush TLB 浪费的 cycles 可不能算少了。所以 C++ 11 搞的 atomic 当然性能比 mutex 不知道高到哪里去,人家那是纯粹 runtime 提供的 user space 的 CPU atomic instruction 而已。
那么如果没有了 context switch,是不是就全部用 sleeplock 才是最优解呢?好像的确是这样的。虽然讲的是 O/S, 不妨 Java 其实也是 O/S 吧,Java 里面有管程(jvm 对象头)能用来记录锁信息(Thread 睡在哪个锁上),所以很适合实现 sleeplock,事实上,synchronized 关键字),ReentrantLock 都是用这种 sleeplock 方案,会把自己挂起,不过其实 sleep 和 wakeup 这两件事都是很花时间的,如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。。。。所以为了通用,Java 搞一个缝合方案:如果自旋超过了限定次数(默认是10次)没有成功获得锁,就应当挂起线程(进入睡眠锁)。
读写锁
自旋锁做的读写锁 (什么是读者写者模型?)
然后我们讲到锁的应用部分, 主要在 kernel 里面有一个常见的情况, 就是很多 read 和部分 write 的情况, 这个也很好想明白, 单是内核那一堆内存里的 buf、cache 就够多这种应用场景了. 我们知道有 reader-writer lock, 他主要是基于 spinlock 的, 当然, 这是由于kernel 里面对内存上的 shared data structure 读写上并不需要太多的时间, 所以 spinlock 来序列化访问是解决并发冲突的一个好用的方法了, 我们知道睡眠锁也是有循环的(醒来后锁又不可用了)不过他适合那种长时间阻塞的共享资源,我们要实现读者写者模型里面读者和读者是没有冲突的,这样 sleeplock 也会退化为 spinlock(就一个 CAS 而已),所以理论上读写之间其实也能做成 sleeplock,读读之间则沿用 spin 就行了。读写锁是高效的的与普通锁相比. 读写锁有三种状态:读模式下加速(共享)、写模式下加锁(独占)以及不加锁。kernel 的 rwlock 只是封装了这个状态限定的 spinlock, 具体实现是用一个字段而已, 很简单. 我们需要分析的是他的缺点从而引入今天学习的 RCU.
给出一种 rwlock 的伪代码:

我们可以分析问题, 这是想回想一个 multicore CPU 的实现, 首先可以考虑读写并发时必须串行化操作,这一点就是 spinlock 的特色,然后由于多读者时不用串行化,这就让读写锁的性能提升的,唯一的串行化仅发生在 CAS 处。
读写锁读者性能剖析 (为什么还要改进?)
那么我们为什么要做 RCU 呢?这是因为实际上的读写锁性能并没有那么好!! 我们必须 dive deep 看,考虑最坏情况 4 个线程都同时请求读锁的时候,会发生什么。下图为搞笑示意图。
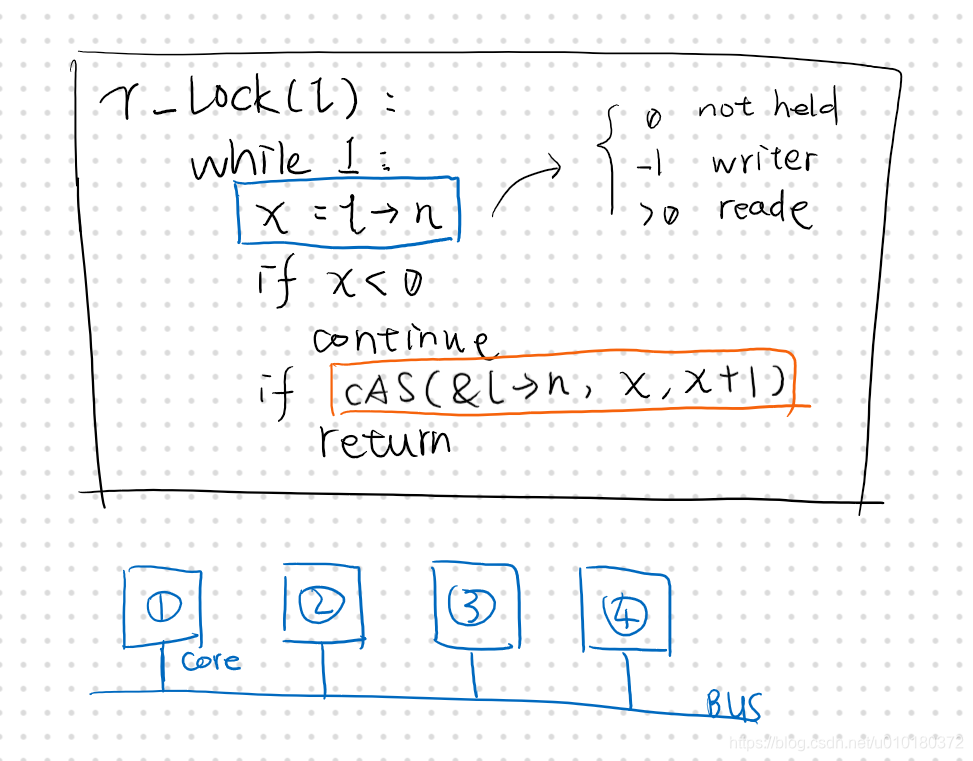
某个时刻,4个线程同时请求执行 CAS 指令(Compare And Swap 本身就是为了保证对信号量的修改必须是串行的具备一致性的),假如此时 Core 1 CAS 成功,则其他的 cores 都会失败并回到蓝色地方重新读取信号量的值。所以理论上我们这里 T(n) = O(n方),因为每次同时 CAS 后剩下的 cores 都要回去重新读一遍。
这有什么?而且对于并发错开时间的 CAS 不应该就成功了吗?不过是区区读变量?然而我们必须意识到这里的信号量是共享的,意味着其由于 CAS 强制串行更新信号量的时候,CPU 访存无法享受光速寄存器以及极速的 L1 Cache 待遇,当 Core 1 修改了他时,他就标记为脏而进入 Cache Coherence 的 MESI 协议流程去了,而此流程将消耗许多 CPU cycles,因此这个 O(n方) 是切实的消耗,其实对于 rw 并发也是如此。
可以体会到, 造成多核读写锁 heavy overhead 的一个重要原因就是哪个 x 的读入, 即 O/S 课线程同步类题目的 semaphore 读写那个共享变量导致的循环 CAS 判断开销. 当然这个理论上最好情况的 O(n方) 已经比原来我们分析 spinlock 里前置串行所有读的 busy-wait-loop 纯粹的多次浪费的 CAS 好很多了….
内核中的 RCU 机制
RCU 功能特色 (解决什么问题?)
所以我们需要搞一些东西来提高性能. 这个叫做 RCU, read + copy update, 他的锁设计必须是和 data structure 一起合作的. 我们先做思想实验,上面我们的问题在于,对于信号量本身是一个共享变量去控制对一个共享数据结构的访问本身必须串行化一部分操作,并且引发了平方的访问和 Cache 同步问题。如果我们能改掉这个问题,那么不仅多读性能提高,是不是我们顺便也可以解决读写的问题,甚至支援读写并发!回想一开始我们举例的链表,很容易就能想到 copy on write的思路。不过 RCU 没有这么暴力的复制一个结构,而是把这个思路运用到局部中。
根据 paper, RCU 解决的问题是三个:
- 支援 concurrent reading 和 updating, 没有之前 rwlock 的 write 时候强 mutex.
- deterministic complexity 出于对某些软件工程上的需求. (我猜想可能是一些实时应用)
- performance on both computation and storage. 就是小 complexity 咯.
RCU 实现——以 rculist 链表 为例 (怎么做 RCU ?)
下面给出论文的 RCU 伪代码原语.

RCU 实现关键点1 结构性更新
update data not in place, 链表例子, 我们不修改内容,而修改结构,如图这样分三步并且保留原有结构体的部分就能保证 reader 读到的数据都是完整的, 没有 mixture 状态. 我们对链表操作的时候,先创建 copy,然后让对 copy 的访问和对原件的访问具有数据结构上的一致性,最后再更新。我们必须理解(其实这个思路在文件系统的 log 实现断电一致性上类似)不同线程(或者进程)对于这个链表的访问必定是要么在步骤 3 完成前,要么在步骤三完成后,具体来说,就算到了最底层的 RISC 指令上,访问 l -> next 的时候,next 要么是已经被修改指向 copy 了,要么是指向原来的 E2,不会出现野指针的情况。
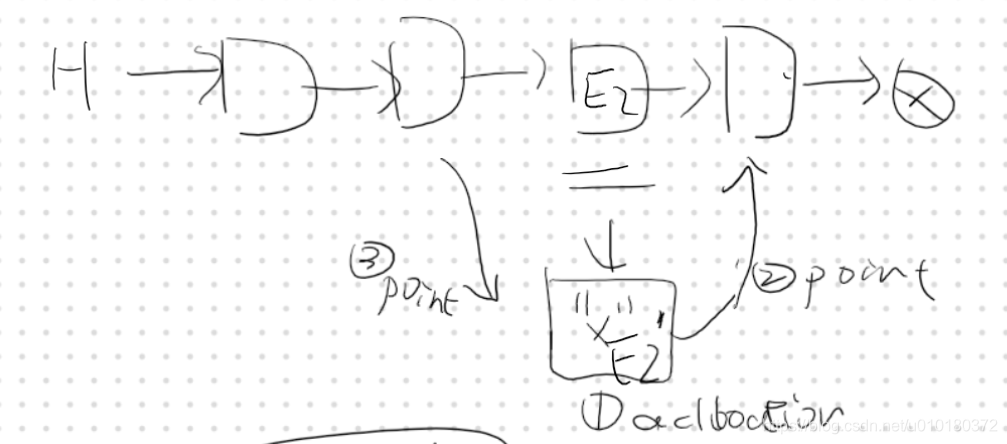
这个关键点导致 RCU 对数据结构有要求, 比如双向链表就用不了 RCU 了. 对树也不错. 这个 head 指针的概念在版本控制软件里也很常见.
RCU 实现关键点2 内存屏障
内存屏障, 我们必须保证上述三部的顺序问题. 这一点很重要. 具体的 barrier 放在哪里我也不是很清楚(视频这里本来讲的有点模糊, prof Robert 没有解答为什么要用 barrier 的一个学生问题,也许是链表这个例子不会出现编译器重排也能跑的优化或者投机执行后错误,我具体网络学习后发现这里其实是涉及到多核的 Cache 问题). 我们了解底层是 speculative execution ,out-of-order 的,编译器重排指令很好禁止。对于 CPU 的话内存屏障则涉及 Cache coherence,这里其实是硬件的妥协,我们知道多核一个 CPU 对变量 Cache 出现读写修改后,就告知其他 Core read Invalidate 不可读的信号请求清空该 Cache 块,然后本 Core Cache 写内存,一旦其他 CPU 再读,就能读到新的值了。
然而 CPU 执行运算是光速的,而处理指令和进行数据传送则慢一点,所以又要搞一个 Store buffer 异步等待等具体我们不用深究,请看下一句话,那么问题就在于,如果有这种情况:无效信号已经确认了大家都没有涉及更新的 Cache line 了,此时本 Core 要进行写存更新内存,而其他 Core 在写存瞬间又进行了读取,又把内存加载进 Cache 了,从而导致非一致性问题。具体结果就是,对于多线程应用,CPU无能为力,应用程序必须手动添加内存屏障。具体内容是涉及 flush store buffer 和 cpu stalling。这里当然涉及性能的比较,Is it worth it?不过答案好像是是。
RCU 实现关键点3 Commit 提交同步点
一些读写的规则保证能抢占 commit :1. 读者不能在读 RCU 的时候进行 context switch (推动他完成本次读,而不是没轻没重地去干别的事情)。2. 我们需要提交 update 当且仅当所有的 read 结束, 抢占进来, free 掉所有的正在被 read 的过气的历史数据结构的某个部分, 当然阻塞 updater 也不对, 所以有 callback 版本的 call_rcu .
具体怎么样如判断 read 结束呢? 论文里面讨论的最简单的一种方法是通过调整线程调度器,使得写入线程简短的在操作系统的每个CPU核上都运行一下,这个过程中每个CPU核必然完成了一次 context switch。上面的原语中的 run_on 意思就是等一个 context switch 周期. 因为数据读取者不能在context switch的时候持有数据的引用,所以经过这个过程,数据写入者可以确保没有数据读取者还在持有数据。这部分内容就和 GC 很像了, 由于 GC 语言一般具备追踪数据是否被使用,实际上我们可以在 GC 语言上实现这样的 free 操作, 但是 kernel 是否适用 GC 之前 Lecture 中我们又谈论过了(教授们完全使用 Golang 实现 Unix Kernel 并对 nginx redis 评估). 当然我们也有 asynchronous 的方案,通过 call_rcu 托管数据结构的 old piece 给 kernel 或者什么 thread,然后注册一个 callback freeing function(请记住 RCU 是一种涉及内核态的机制,但他需要自定义数据结构,比如 Linux kernel 可能有个 RCU 链表 RCU 数,call_rcu 能统一管理)给 kernel 去完成这个检测 context switch 的内容。
具体一些课程的详细内容复习其他也可以参考大佬翻译的上课课程内容完全稿.
RCU 性能分析 (什么时候用 RCU ?)
RCU 数据读取非常的快。唯一额外的工作就是在rcu_read_lock和rcu_read_unlock里面设置好不要触发context switch,并且在 rcu_dereference中设置 memory barrier,这些可能会消耗几十个CPU cycle,但是相比锁来说代价要小的多。
对于数据写入者,性能会糟糕一点。首先锁的获取锁和释放锁是一个。还有一个可能非常耗时的synchronize_rcu函数调用。实际上在synchronize_rcu内部会出让CPU,所以代码在这不会通过消耗CPU来实现等待,但是它可能会消耗大量时间来等待其他所有的CPU核完成context switch。所以基于数据写入时的多种原因,和数据读取时的工作量,数据写入者需要消耗更多的时间完成操作。如果数据读取区域很短(注,这样就可以很快可以恢复context switch),并且数据写入并没有很多,那么数据写入慢一些也没关系。所以当人们将RCU应用到内核中时,必须要做一些性能测试来确认使用RCU是否能带来好处,因为这取决于实际的工作负载。Linux 中大量使用了 RCU 数据结构。
总结
略(挖个坑)















 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









