









6.S081-8锁 - Spinlock
文章目录
0. 简单总结
锁解决的问题:race condition。——为了并行中的正确性(共享数据一致性)
锁带来的问题:并行变串行,效率降低。
自旋锁的实现👇,acquire
// close irq
while(__sync_lock_test_and_set(&lk->locked, 1) != 0) // if lk -> locked == 0, lk -> locked = 1, break while;
; // if lk -> locked == 1, lk -> locked = 1, continue while;
// open irq
release👇
// close irq
__sync_lock_release(&lk->locked);
// open irq
1. 为什么需要锁🔒?锁的好处和坏处。
1.1 为什么使用锁,带来了什么收益?
并发中保证数据正确性。
——简单总结:为了并行性,有多核处理器,但是多个CPU访问一些共享资源(比如proc,cache_buffer),可能会导致数据不一致。为了保持并行过程中的共享数据的一致性,我们需要锁。
1.2 使用锁的代价?
我们想要通过并行来获得高性能,我们想要并行的在不同的CPU核上执行系统调用,但是如果这些系统调用使用了共享的数据,我们又需要使用锁,而锁又会使得这些系统调用串行执行,所以最后锁反过来又限制了性能。
出于正确性,我们需要使用锁,但是考虑到性能,锁又是极不好的。
2. race condition (什么是 + 怎么解决)
2.1 什么是race condition?
如果输出的结果依赖于不受控制的事件的出现顺序,那么我们便称发生了 race condition.
首先看一个例子👇(kalloc.c中的kfree)——kfree函数会将释放的page保存于freelist中。
// Free the page of physical memory pointed at by v,
// which normally should have been returned by a
// call to kalloc(). (The exception is when
// initializing the allocator; see kinit above.)
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP){
panic("kfree");
}
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
其中kfreelist定义如下👇(显然,它就是一个最简单的链表,并且通过 r->next = kmem.freelist; kmem.freelist = r;可以看出来,插入的方法是头插法。)
struct run {
struct run *next;
};
struct {
struct spinlock lock;
struct run *freelist;
} kmem;
如果我们将上面的kfree中的锁代码注释掉👇, 重新make qemu编译xv6——仍然可以成功运行,但是如果执行usertests呢?
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP){
panic("kfree");
}
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
// acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
// release(&kmem.lock);
}
——如果执行一个用户程序(带free),那么可能出现panic也可能不会,因为原来加锁的部分的操作可能还是原子的,但是也可能不是了。
如果输出的结果依赖于不受控制的事件的出现顺序,那么我们便称发生了 race condition。
详细解释race condition——上面的过程为什么会出现panic?
首先你们在脑海里应该有多个CPU核在运行,比如说CPU0在运行指令,CPU1也在运行指令,这两个CPU核都连接到同一个内存上。在前面的代码中,数据freelist位于内存中,它里面记录了2个内存page。假设两个CPU核在相同的时间调用kfree。(往当前链表kmem.kfree中插入即将释放的物理页的地址,插入位置为头部)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-POzesr9O-1660896495871)(https://raw.githubusercontent.com/LEVI-Tempset/picgo-pics-for-typora/main/imgimage-20220819111039863.png)]
kfree函数接收一个物理地址pa作为参数,freelist是个单链表,kfree中将pa作为单链表的新的head节点,并更新freelist指向pa(注,也就是将空闲的内存page加在单链表的头部)。当两个CPU都调用kfree时,CPU0想要释放一个page,CPU1也想要释放一个page,现在这两个page都需要加到freelist中。
kfree中首先将对应内存page的变量r指向了当前的freelist(也就是单链表当前的head节点)。我们假设CPU0先运行,那么CPU0会将它的变量r的next指向当前的freelist。如果CPU1在同一时间运行,它可能在CPU0运行第二条指令(kmem.freelist = r)之前运行代码。所以它也会完成相同的事情,它会将自己的变量r的next指向当前的freelist。现在两个物理page对应的变量r都指向了同一个freelist(注,也就是原来单链表的head节点)。
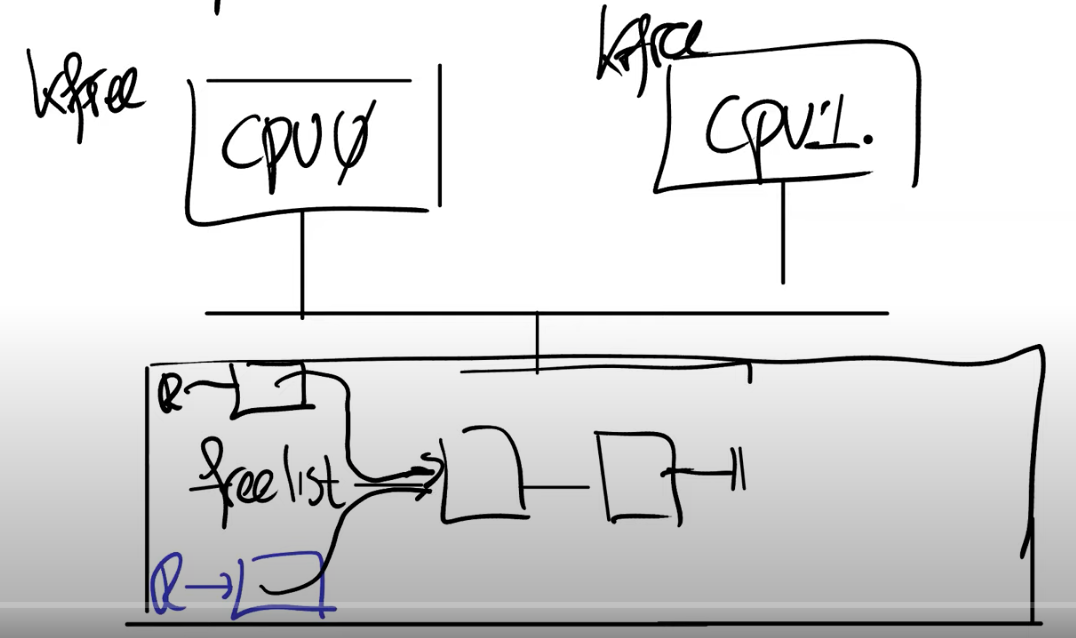
接下来,剩下的代码也会并行的执行(kmem.freelist = r),这行代码会更新freelist为r。因为我们这里只有一个内存,所以总是有一个CPU会先执行,另一个后执行。我们假设CPU0先执行,那么freelist会等于CPU0的变量r。之后CPU1再执行,它又会将freelist更新为CPU1的变量r。这样的结果是,我们丢失了CPU0对应的page。CPU0想要释放的内存page最终没有出现在freelist数据中。
这是一种具体的坏的结果,当然可能会有更多坏的结果,因为可能会有更多的CPU。例如第三个CPU可能会短暂的发现freelist等于CPU0对应的变量r,并且使用这个page,但是之后很快freelist又被CPU1更新了。所以,拥有越多的CPU,我们就可能看到比丢失page更奇怪的现象。
在代码中,用来解决这里的问题的最常见方法就是使用锁。
2.2 如何解决race condition?——什么是锁。
锁就是一个对象,就像其他在内核中的对象一样。有一个结构体叫做lock,它包含了一些字段,这些字段中维护了锁的状态。锁有非常直观的API:
- acquire,接收指向lock的指针作为参数。acquire确保了在任何时间,只会有一个进程能够成功的获取锁。
- release,也接收指向lock的指针作为参数。在同一时间尝试获取锁的其他进程需要等待,直到持有锁的进程对锁调用release。
锁的acquire和release之间的代码,通常被称为critical section。—— 通常会在这里以原子的方式执行共享数据的更新。
xv6的kernel不只有一把锁,如果两个系统调用使用了两把不同的锁,那么它们就能完全的并行运行。(比如不同的系统调用)
3. 为什么不能让代码自动加锁?
锁应该与操作而不是数据关联,所以自动加锁在某些场景下会出问题。
举例:假设我们有一个对于rename的调用,这个调用会将文件从一个目录移到另一个目录,我们现在将文件d1/x移到文件d2/y。
如果我们按照前面说的,对数据结构自动加锁。现在我们有两个目录对象,一个是d1,另一个是d2,那么我们会先对d1加锁,删除x,之后再释放对于d1的锁;之后我们会对d2加锁,增加y,之后再释放d2的锁。这是我们在使用自动加锁之后的一个假设的场景。
在这个例子中,我们会有错误的结果,那么为什么这是一个有问题的场景呢?为什么这个场景不能正常工作?
在我们完成了第一步,也就是删除了d1下的x文件,但是还没有执行第二步,也就是创建d2下的y文件时。其他的进程会看到什么样的结果?是的,其他的进程会看到文件完全不存在。这明显是个错误的结果,因为文件还存在只是被重命名了,文件在任何一个时间点都是应该存在的。但是如果我们按照上面的方式实现锁的话,那么在某个时间点,文件看起来就是不存在的。
所以这里正确的解决方法是,我们在重命名的一开始就对d1和d2加锁,之后删除x再添加y,最后再释放对于d1和d2的锁。
4. 锁的作用和死锁
锁的3个主要作用:
-
锁可以避免丢失更新。如果你回想我们之前在kalloc.c中的例子,丢失更新是指我们丢失了对于某个内存page在kfree函数中的更新。如果没有锁,在出现race condition的时候,内存page不会被加到freelist中。但是加上锁之后,我们就不会丢失这里的更新。
-
锁可以打包多个操作,使它们具有原子性。我们之前介绍了加锁解锁之间的区域是critical section,在critical section的所有操作会都会作为一个原子操作执行。
-
锁可以维护共享数据结构的不变性。共享数据结构如果不被任何进程修改的话是会保持不变的。如果某个进程acquire了锁并且做了一些更新操作,共享数据的不变性暂时会被破坏,但是在release锁之后,数据的不变性又恢复了。你们可以回想一下之前在kfree函数中的freelist数据,所有的free page都在一个单链表上。但是在kfree函数中,这个单链表的head节点会更新。freelist并不太复杂,对于一些更复杂的数据结构可能会更好的帮助你理解锁的作用。
最简单的死锁例子:
aquire(&e);
...
aquire(&e); // 第一个锁release之后才能执行,但是不继续执行的话又走不到第一个release
...
release(&e);
release(&e);
如果有多个锁,如何避免死锁?——对锁进行排序。所有的操作都必须以相同的顺序获取锁。
举例:当有多个锁的时候,场景会更加有趣。假设现在我们有两个CPU,一个是CPU1,另一个是CPU2。CPU1执行rename将文件d1/x移到d2/y,CPU2执行rename将文件d2/a移到d1/b。这里CPU1将文件从d1移到d2,CPU2正好相反将文件从d2移到d1。我们假设我们按照参数的顺序来acquire锁,那么CPU1会先获取d1的锁,如果程序是真正的并行运行,CPU2同时也会获取d2的锁。之后CPU1需要获取d2的锁,这里不能成功,因为CPU2现在持有锁,所以CPU1会停在这个位置等待d2的锁释放。而另一个CPU2,接下来会获取d1的锁,它也不能成功,因为CPU1现在持有锁。这也是死锁的一个例子,有时候这种场景也被称为deadly embrace。这里的死锁就没那么容易探测了。
不过在设计一个操作系统的时候,定义一个全局的锁的顺序会有些问题。如果一个模块m1中方法g调用了另一个模块m2中的方法f,那么m1中的方法g需要知道m2的方法f使用了哪些锁。因为如果m2使用了一些锁,那么m1的方法g必须集合f和g中的锁,并形成一个全局的锁的排序。这意味着在m2中的锁必须对m1可见,这样m1才能以恰当的方法调用m2。
但是这样又违背了代码抽象的原则。在完美的情况下,代码抽象要求m1完全不知道m2是如何实现的。但是不幸的是,具体实现中,m2内部的锁需要泄露给m1,这样m1才能完成全局锁排序。所以当你设计一些更大的系统时,锁使得代码的模块化更加的复杂了。
锁的开发流程:
如果你想获得更高的性能,你需要拆分数据结构和锁。如果你只有一个big kernel lock,那么操作系统只能被一个CPU运行。如果你想要性能随着CPU的数量增加而增加,你需要将数据结构和锁进行拆分。
那怎么拆分呢?通常不会很简单,有的时候还有些困难。比如说,你是否应该为每个目录关联不同的锁?你是否应该为每个inode关联不同的锁?你是否应该为每个进程关联不同的锁?或者是否有更好的方式来拆分数据结构呢?如果你重新设计了加锁的规则,你需要确保不破坏内核一直尝试维护的数据不变性。
如果你拆分了锁,你可能需要重写代码。如果你为了获得更好的性能,重构了部分内核或者程序,将数据结构进行拆分并引入了更多的锁,这涉及到很多工作,你需要确保你能够继续维持数据的不变性,你需要重写代码。通常来说这里有很多的工作,并且并不容易。
所以这里就有矛盾点了。我们想要获得更好的性能,那么我们需要有更多的锁,但是这又引入了大量的工作。
通常来说,开发的流程是:
- 先以coarse-grained lock(注,也就是大锁)开始。
- 再对程序进行测试,来看一下程序是否能使用多核。
- 如果可以的话,那么工作就结束了,你对于锁的设计足够好了;如果不可以的话,那意味着锁存在竞争,多个进程会尝试获取同一个锁,因此它们将会序列化的执行,性能也上不去,之后你就需要重构程序。
在这个流程中,测试的过程比较重要。有可能模块使用了coarse-grained lock,但是它并没有经常被并行的调用,那么其实就没有必要重构程序,因为重构程序设计到大量的工作,并且也会使得代码变得复杂。所以如果不是必要的话,还是不要进行重构。
5. Spin lock的实现
自旋锁的结构:xv6-riscv/kernel/spinlock.h👇
// Mutual exclusion lock.
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
};
实现锁的主要难点在于锁的acquire接口,在acquire里面有一个死循环,循环中判断锁对象的locked字段是否为0,如果为0那表明当前锁没有持有者,当前对于acquire的调用可以获取锁。之后我们通过设置锁对象的locked字段为1来获取锁。最后返回。👇(理论上的写法)
void acquire(struct spinlock *lk) {
while (1) {
if (lk -> locked == 0) { // 这里可能会出错(两个进程同时lk->locked == 0, 然后同时lk -> locked = 1
lk -> locked = 1; // 👆锁的特性就被违背了
return;
}
}
}
如果锁的locked字段不为0,那么当前对于acquire的调用就不能获取锁,程序会一直spin。也就是说,程序在循环中不停的重复执行,直到锁的持有者调用了release并将锁对象的locked设置为0。
上面的写法有什么问题?
两个进程可能同时读到锁的lk -> locked == 0。👆,如何解决?👇
使用特殊的硬件指令,这个特殊的硬件指令会保证一次test-and-set操作的原子性。在RISC-V上,这个特殊的指令就是amoswap(atomic memory swap)。这个指令接收3个参数,分别是address,寄存器r1,寄存器r2。这条指令会先锁定住address,将address中的数据保存在一个临时变量中(tmp),之后将r1中的数据写入到地址中,之后再将保存在临时变量中的数据写入到r2中,最后再对于地址解锁。
来看一下真正的acquire()👇
// Acquire the lock.
// Loops (spins) until the lock is acquired.
void
acquire(struct spinlock *lk)
{
push_off(); // disable interrupts to avoid deadlock.
if(holding(lk))
panic("acquire");
// On RISC-V, sync_lock_test_and_set turns into an atomic swap:
// a5 = 1
// s1 = &lk->locked
// amoswap.w.aq a5, a5, (s1)
while(__sync_lock_test_and_set(&lk->locked, 1) != 0)
;
// Tell the C compiler and the processor to not move loads or stores
// past this point, to ensure that the critical section's memory
// references happen strictly after the lock is acquired.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Record info about lock acquisition for holding() and debugging.
lk->cpu = mycpu();
}
-
如果锁没有被持有,那么锁对象的locked字段会是0,如果locked字段等于0,我们调用test-and-set将1写入locked字段,并且返回locked字段之前的数值0。如果返回0,那么意味着没有人持有锁,循环结束。
-
如果locked字段之前是1,那么这里的流程是,先将之前的1读出,然后写入一个新的1,但是这不会改变任何数据,因为locked之前已经是1了。之后__sync_lock_test_and_set会返回1,表明锁之前已经被人持有了,这样的话,判断语句不成立,程序会持续循环(spin),直到锁的locked字段被设置回0。
release操作也同理👇(同样是使用__sync_lock_test_and_set,只不过写入的是0)
// Release the lock.
void
release(struct spinlock *lk)
{
if(!holding(lk))
panic("release");
lk->cpu = 0;
// Tell the C compiler and the CPU to not move loads or stores
// past this point, to ensure that all the stores in the critical
// section are visible to other CPUs before the lock is released,
// and that loads in the critical section occur strictly before
// the lock is released.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Release the lock, equivalent to lk->locked = 0.
// This code doesn't use a C assignment, since the C standard
// implies that an assignment might be implemented with
// multiple store instructions.
// On RISC-V, sync_lock_release turns into an atomic swap:
// s1 = &lk->locked
// amoswap.w zero, zero, (s1)
__sync_lock_release(&lk->locked);
pop_off();
}
为什么release函数中不直接使用一个store指令将锁的locked字段写为0?有人想回答一下为什么吗?
因为其他的处理器可能会向locked字段写入1,或者写入0。。。
对于很多人包括我自己来说,**经常会认为一个store指令是一个原子操作,但实际并不总是这样,这取决于具体的实现。**例如,对于CPU内的缓存,每一个cache line的大小可能大于一个整数,那么store指令实际的过程将会是:**首先会加载cache line,之后再更新cache line。所以对于store指令来说,里面包含了两个微指令。**这样的话就有可能得到错误的结果。所以为了避免理解硬件实现的所有细节,例如整数操作不是原子的,或者向一个64bit的内存值写数据是不是原子的,我们直接使用一个RISC-V提供的确保原子性的指令来将locked字段写为0。
为什么uart加锁的时候,首先关闭中断?
spinlock需要处理两类并发,一类是不同CPU之间的并发,一类是相同CPU上中断和普通程序之间的并发。
设想:如果我们在处理过程中acquire的锁,但是没有关中断,这时候可能来一个中断,继续是uart的操作,那么就会出现第二次加锁 —— 会引起panic。
6.简单总结
锁解决的问题:race condition。——为了并行中的正确性(共享数据一致性)
锁带来的问题:并行变串行,效率降低。
自旋锁的实现👇,acquire
// close irq
while(__sync_lock_test_and_set(&lk->locked, 1) != 0) // if lk -> locked == 0, lk -> locked = 1, break while;
; // if lk -> locked == 1, lk -> locked = 1, continue while;
// open irq
release👇
// close irq
__sync_lock_release(&lk->locked);
// open irq















 795
795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









