










1. mask机制
Mask机制几乎贯穿了Transformer架构的始终,若不能首先将mask机制交代清楚,就难以对Transformer进行连贯的阐述。因此,决定将mask机制的介绍放在最前面,如果一开始难以理解,可以结合后文中的整体架构再回来理解mask机制。
Transformer中的mask机制可以分为两类,即“padding mask”与“真值mask(或称为subsequent mask)”,其作用各不相同。
1.1 padding mask
padding mask是由NLP这类特定任务带来的,NLP的特点为“不同的输入语句可能是不定长的”,如翻译的第一个句子为“山东队真菜”,第二个句子为“我再也不看球赛了”,那么第一个句子长度为5,第二个句子为8。这样,两个不同长度的句子就无法组成一个batch。为了解决这个问题,选择通过padding将所有句子补充为固定长度。例如将“山东队真菜”padding为“山东队真菜啊啊啊”,这样两个句子的长度均变为了8,即可组成一个batch进行批量训练。
然而,padding进去的信息并不是原句中的信息,我们在训练过程中不能提取padding进去的“啊”。因此,在点乘注意力中,需要通过padding mask掩盖住无用信息。具体示例如图1.1所示。
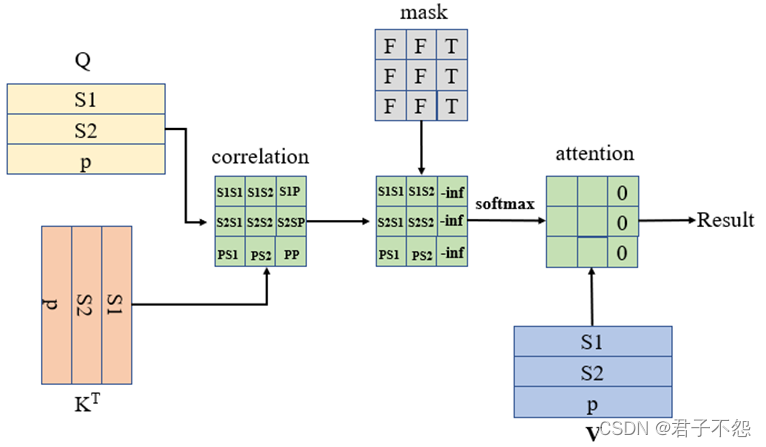
在图1.1中,s1与s2代表两个待翻译的句子,p则代表padding的信息,mask矩阵中的F (False)代表不需要mask,T (True)代表需要进行mask(即对padding信息进行掩盖)。通过mask矩阵将correlation矩阵对应位置的相关性值重置为负无穷,这样在通过softmax计算注意力矩阵时,相应位置的注意力权重则会变为0,进而通过attention对V进行信息聚合时舍去了p的信息。
由于本文是面向“Trajectory Prediction”(后文简称TP)所写,模型的输入输出均为定长,因此padding mask矩阵为全False矩阵。
1.2 真值mask
相比于LSTM,Transformer的一大特点是“并行训练”(测试时,编码器并行输入,解码器串行输出)。因此,训练过程需要考虑的一个重要问题是,如何防止编码器看到未来的真值,保证解码器在解码位置t的信息时只能依赖位置t之前的信息,这就用到了真值mask。该mask操作仅应用于Decoder Layer的“Masked Multi-Head Attention”,具体示例如图1.2所示。

图中,Start为开始解码标志符号。从图中可以看出,经过真值mask后,在预测S4时只能依赖Start的信息,预测S5时可依赖Start与S4的信息,预测S6时可依赖Start、S4以及S5的信息,达到了“防止解码器看到未来真值”的目的。其代码实现如下(附参数介绍):
'参数定义'
parser=argparse.ArgumentParser(description='Train the individual Transformer model')
parser.add_argument('--look_back',type=int,default=15,help='the length of historical moments (frames)')
parser.add_argument('--pre_len',type=int,default=25,help='the length of future moments (frames)')
parser.add_argument('--batch_size',type=int,default=512,help='the size of batch')
parser.add_argument('--input_size',type=int,default=6,help='the dimension of input')
parser.add_argument('--output_size',type=int,default=2,help='the dimension of output')
parser.add_argument('--d_k',type=int,default=64,help='the dimension of d_K')
parser.add_argument('--d_v',type=int,default=64,help='the dimension of d_V')
parser.add_argument('--d_model',type=int,default=512,help='the dimension of d_model')
parser.add_argument('--d_ff',type=int,default=2048,help='the dimension of d_ff')
parser.add_argument('--n_heads',type=int,default=8,help='the number of attention heads')
parser.add_argument('--n_layers',type=int,default=6,help='the number of Encoder layer and Decoder layers')
args=parser.parse_args()
'真值掩码'
def get_gt_mask(seq):
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequent_mask = np.triu(np.ones(attn_shape), k=1)
subsequent_mask = torch.from_numpy(subsequent_mask).byte()
return subsequent_mask
2. Input Embedding
在NLP中,Input Embedding被用来建立字典。由于本文面向“Trajectory Prediction”所写,任务本质上是回归问题,因为不需要建立字典,在该部分仅通过FC层对输入进行了扩维,代码不再单独列出。

3. Positional Encoding
作为一并行输入的架构,Transformer失去了RNN结构的“天然优势”,它不能像LSTM或GRU那种通过循环递归的工作方式对区序列中不同元素的位置,其模型具有“对称性”,简单来说就是f (x1,x2) = f (x2,x1)。然而,NLP具有语义上的前后依赖关系,而TP具有时序上的依赖关系,因此不管对于NLP还是TP来说,Transformer的对称性显然是不合理的。为了解决这个问题,Transformer的原文“Attention Is All You Need”提出通过位置编码赋予输入位置信息,编码方式如图3.1。

其中,pos为单词处于一句话中的位置,i为该单词的编码向量中元素的位置。

如图3.2,假设一句话有三个字,每个字根据其在字典中的位置映射为3维向量。那么,图中被框起来的0.7的位置,其pos=0(因为“不”字在这句话中的索引为0),i=2(因为0.7在“不”字的向量中的索引为2),以此类推可得到任意位置的位置编码。实现代码如下:
def PositionEmbedding(n_position, d_model):
PE=torch.zeros((n_position,d_model))
for i in range(d_model): PE[:,i]=i # 赋予列值
for pos in range(n_position):
PE[pos,0::2]=np.sin(pos/np.power(1000, PE[pos,0::2]/d_model)) # pos行的偶数列
PE[pos,1::2]=np.cos(pos/np.power(1000,(2*(PE[pos,1::2]//2))/d_model )) #pos行的奇数列
PE=PE.unsqueeze(0).expand(args.batch_size,PE.shape[0],PE.shape[1]) #按照batch_size进行位置信息复制
return PE位置编码矩阵的可视化结果如图3.3所示。

4. Multi-Head Attention (with Add& Norm)
在Transformer中,用到Multi-Head Attention的部分共有三处,其区别仅在于他们的输入以及掩码矩阵不同,而网络结构是完全相同的。

4.1 ScaledDotProductAttention
多头注意力机制中,其核心为尺度点乘注意力,尺度点乘注意力的公式如图4.1所示。

在尺度点乘注意力中,通过除d_k对相关矩阵中的数值进行尺度变换,防止个别值过大而进入softmax函数的饱和区,使得softmax后的注意力值集中分布在0附近或1附近。尺度点乘注意力的代码实现如下,需要注意的是,在代码实现中,要注意mask的作用,因为mask在网络结构图中是看不到的,容易遗忘。
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self,q_n,k_n,v_n,attn_mask):
scores = torch.matmul(q_n,k_n.transpose(-1, -2)) / np.sqrt(args.d_k) # scores : [batch_size x n_heads x S × S]
scores.masked_fill_(attn_mask, -1e9)# 把True的地方(即mask的位置)填入极小的值,使得在softmax后注意力几乎为0
attn = nn.Softmax(dim=-1)(scores) #[batch_size × n_heads × S × S]
context = torch.matmul(attn,v_n) #[batch_size,n_heads,S,S]*[batch_size,n_heads,S,d_v]=[batch_size,n_heads,S,d_k]
return context, attn
4.2 MultiHeadAttention
为了实现信息在不同特征空间的映射以提取更加丰富的表征,Transformer采用了多头注意力机制,公式如图4.2所示。

其基本思想为,将inputs输入给8组不同的(W_q, W_k, W_v) 得到8组不同(Q, K,V),进而得到8组不同的结果 (head1,head2,,,,,head8),然后将8组head信息拼接并降维后继续向下传递。然而,在代码层面,大家普遍采取了另一种方式:将inputs平均切片为成8组,将八组信息经过同一组(W_q, W_k, W_v) 得到8组不同(Q, K,V),进而得到8组不同的结果 (head1,head2,,,,,head8),然后将8组head信息拼接并降维后继续向下传递。至于为这么这样,我们后面再讨论,该部分的实现代码如下:
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(args.d_model, args.d_k * args.n_heads)
self.W_K = nn.Linear(args.d_model, args.d_k * args.n_heads)
self.W_V = nn.Linear(args.d_model, args.d_v * args.n_heads)
self.linear = nn.Linear(args.n_heads * args.d_v, args.d_model)
self.layer_norm = nn.LayerNorm(args.d_model)
def forward(self,Q_inputs,K_inputs,V_inputs,attn_mask):
# 记录残差与batch_size大小
residual,batch_size=Q_inputs,Q_inputs.shape[0]
# 把输入映射成Q,K,V
Q,K,V=self.W_Q(Q_inputs),self.W_K(K_inputs),self.W_V(V_inputs)
# 通过reshape对Q、K、V按注意力头的数目切分
#[B,S,d_model] - [B,S,n_heads,d_k] -[B,n_heads,S,d_k]
q_n=Q.reshape(batch_size,-1,args.n_heads,args.d_k).transpose(1,2)
k_n=K.reshape(batch_size, -1, args.n_heads, args.d_k).transpose(1,2)
v_n=V.reshape(batch_size, -1, args.n_heads, args.d_v).transpose(1,2)
# 对传过来的掩码进行扩展n_heads维,使得每一个注意力头都有掩码
attn_mask=attn_mask.unsqueeze(1).repeat(1, args.n_heads, 1, 1)
# 获取点乘注意力的极端结果及注意力矩阵,contex维度为[B,n_heads,S,d_k],转为[B,S,n_heads,d_k],再多头拼接转为[B,S,n_heads*d_k]
contex,atten=ScaledDotProductAttention()(q_n,k_n,v_n,attn_mask)
contex=contex.transpose(1,2).reshape(batch_size,-1,args.n_heads*args.d_k)
#通过线性成将n_heads*d_k维降低为原来的d_model维,再通过参加相加与LayerNorm即可输出
#输出维度[B,S,d_model], atten维度[B,n_heads,S,S]
Multi_out=self.layer_norm(self.linear(contex)+residual)
return Multi_out,atten5. FeedForward (with Add& Norm)
前馈网络成结构简单,即将输入信息进行升维后再降维,其网络结构如图5.

其代码实现如下:
class FeedForward(nn.Module):
def __init__(self):
super(FeedForward, self).__init__()
self.Linear1 = nn.Linear(in_features=args.d_model,out_features=args.d_ff)
self.Linear2 = nn.Linear(in_features=args.d_ff,out_features=args.d_model)
self.layer_norm = nn.LayerNorm(args.d_model)
def forward(self,Multi_out):
residual = Multi_out # [B,S,d_model]
out= nn.ReLU()(self.Linear1(Multi_out)) #[B,S,d_ff]
out= self.Linear2(out) # [B,S,d_model]
Ffd_out=self.layer_norm(out + residual)
return Ffd_out6. Encoder Layer &Decoder Layer
有了上述模块,我们即可按照图6所示的Transformer结构搭建一个编码器&解码器层(注:本文未将“Input Embedding”与“Positional Encoding”视为编解码器的一部分)。

编码器层的实现如下:
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.ffn =FeedForward()
def forward(self,enc_inputs, enc_self_attn_mask):
#经过多头注意力层
Multi_out,attn = self.enc_self_attn(enc_inputs,enc_inputs, enc_inputs, enc_self_attn_mask) #
# 经过前馈网络
Ffd_out = self.ffn(Multi_out) # enc_outputs: [batch_size x len_q x d_model]
return Ffd_out, attn解码器层实现如下:
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention() #第一层有mask的多头注意力
self.dec_enc_attn = MultiHeadAttention() #第二层没有mask的多头注意力
self.ffn = FeedForward()
def forward(self,dec_inputs, enc_outputs, dec_self_mask, dec_enc_mask):
# 经过带掩码的多头注意力层:此时的掩码防止解码器看到未来时刻的真值。该层的Q_inputs、K_inputs以及V_inputs均为编码器输入
Milti1_out,dec_self_attn = self.dec_self_attn(dec_inputs,dec_inputs,dec_inputs,dec_self_mask)
# 经过不带掩码的多头注意力层
dec_outputs, dec_enc_attn = self.dec_enc_attn(Milti1_out,enc_outputs, enc_outputs,dec_enc_mask)
# 经过前馈网络
dec_outputs = self.ffn(dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn7. Transformer整体架构
为了提取更加精细化的特征以实现更好的模型性能,原文使用了多层编解码器,因此本文代码也参照此方式,通过stack多层 Encoder Layer和Decoder Layer构建Encoder与Decoder,进而搭建完整的Transformer架构。其整体架构如图7所示。

代码实现如下:
'编码器'
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.Enc_layers = nn.ModuleList([EncoderLayer() for _ in range(args.n_layers)])
def forward(self, enc_inputs): # enc_inputs : [batch_size x source_len]
#enc_outputs = self.src_emb(enc_inputs) + self.pos_emb #嵌入+位置编码:将每一个词嵌入为512维度,输出为[batch,seq_len,d_model]
# 轨迹预测中输入为定长,不需要用pad_mask,生成全False掩码,不mask任何一个输入
enc_self_attn_mask = torch.gt(torch.zeros((args.batch_size,args.look_back,args.look_back)),0) #序列pad掩码
enc_self_attns = []
for layer in self.Enc_layers: #经过多层编码器层
enc_inputs, enc_self_attn = layer(enc_inputs,enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
enc_outputs=enc_inputs #取最后一层Encoder layer的输出作为整个Encoder的输出
return enc_outputs, enc_self_attns
'解码器'
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.layers = nn.ModuleList([DecoderLayer() for _ in range(args.n_layers)])
def forward(self,dec_inputs,enc_outputs): # dec_inputs : [batch_size x target_len]
# dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(torch.LongTensor([[5,1,2,3,4]]))
# 第一层掩码(pad掩码+真值掩码):因为输出也为定长,pad掩码全为flase
dec_self_pad_mask=torch.gt(torch.zeros((args.batch_size,args.pre_len,args.pre_len)),0) #序列pad掩码
dec_self_gt_mask = get_gt_mask(dec_inputs) #获取真值掩码
dec_self_mask= torch.gt((dec_self_pad_mask+ dec_self_gt_mask), 0) #第一层掩码
# 第二层掩码:对来自Encoder的(K,V)pad掩码,由于是定长,依然全为flase
dec_enc_mask =torch.gt(torch.zeros((args.batch_size,args.pre_len,args.look_back)),0)
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
dec_inputs, dec_self_attn, dec_enc_attn = layer(dec_inputs, enc_outputs, dec_self_mask, dec_enc_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
dec_outputs=dec_inputs #最后一层Decoder layer的输出为整个Decoder的输出
return dec_outputs, dec_self_attns, dec_enc_attns
'Transformer整体结构'
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.enc_emb=nn.Linear(args.input_size,args.d_model)
self.dec_emb = nn.Linear(args.output_size, args.d_model)
self.Relu=nn.ReLU()
self.encoder = Encoder()
self.decoder = Decoder()
self.projection = nn.Linear(args.d_model,args.output_size, bias=False)
def forward(self, enc_inputs, dec_inputs):
enc_inputs=self.Relu(self.enc_emb(enc_inputs))+PositionEmbedding(args.look_back,args.d_model) #对输入进行维度扩展+位置编码
dec_inputs=self.Relu(self.dec_emb(dec_inputs))+PositionEmbedding(args.pre_len,args.d_model) # 对输出进行维度扩展+位置编码
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_outputs)
pre = self.projection(dec_outputs)
return pre, enc_self_attns, dec_self_attns, dec_enc_attns
8. 开放性讨论
8.1 Multi-Head Attention 问题
正如4.2中所述,原文中完整的inputs经过八组不同的(W_q, W_k, W_v)及点乘注意力后得到八组不同的head,而代码实现层却将平均切分后的、不完整的inputs经过同一组(W_q, W_k, W_v)得到不同的head。显然,这样的操作可以极大减少模型参数量,加快模型运算,但这种方式是否导致每一组进入(W_q, W_k, W_v)的信息均是不完整的,从而影响模型性能。
8.2 mask问题
在Transformer架构中,,Encoder是由多个Encoder Layer组成的。inputs在经过第一层Encoder Layer的时候已经通过padding mask丢弃了padding的无用信息,这时候第一层的输出已经没有无用信息了,但后面的第几层Encoder Layer依然按照第一层一样进行了mask,这样会不会损失有用信息呢?这个问题再Decoder中同样存在。
针对上述问题,我也请教了国内不同顶尖高校的一些领域内做的非常出色的博士,他们认为,大家大可按照自己的理解进行网络结构的搭建,模型的性能不会因为一些实现中的“细枝末节”而产生大的波动,重要的是idea。














 996
996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









