









Python介绍、 Unix & Linux & Window & Mac 平台安装更新 Python3 及VSCode下Python环境配置配置
python基础知识及数据分析工具安装及简单使用(Numpy/Scipy/Matplotlib/Pandas/StatsModels/Scikit-Learn/Keras/Gensim))
数据探索(数据清洗)①——数据质量分析(对数据中的缺失值、异常值和一致性进行分析)
数据探索(数据清洗)②—Python对数据中的缺失值、异常值和一致性进行处理
数据探索(数据集成、数据变换、数据规约)③—Python对数据规范化、数据离散化、属性构造、主成分分析 降维
数据探索(数据特征分析)④—Python分布分析、对比分析、统计量分析、期性分析、贡献度分析、相关性分析
挖掘建模①—分类与预测
挖掘建模②—Python实现预测
挖掘建模③—聚类分析(包括相关性分析、雷达图等)及python实现
挖掘建模④—关联规则及Apriori算法案例与python实现
挖掘建模⑤—因子分析与python实现
数据探索(数据清洗)①—数据质量分析(对数据中的缺失值、异常值和一致性进行分析)
数据质量分析
数据质量分析是数据预处理的前提,是数据挖掘分析结论有效性和准确性的基础,其主要任务是检查原始数据中是否存在脏数据,脏数据一般是指不符合要求,以及不能直接进行相应分析的数据,在常见的数据挖掘工作中,脏数据包括:
- 缺失值
- 异常值
- 不一致的值
-
- 重复数据及含有特殊符号(如#、¥、*)的数据
数据预处理
在数据挖掘的过程中,数据预处理占到了整个过程的60%。
数据预处理的主要任务包括数据清洗,数据集成,数据变换和数据规约。处理过程如图所示:

数据清洗主要是删除原始数据集中的无关数据、重复数据,平滑噪声数据,处理缺失值、异常值等。
缺失值
缺失值产生的原因
- 有些信息暂时无法获取,或者获取信息的代价太大。
- 有些信息是被遗漏的。可能是因为输入时认为不重要、忘记填写或对数据理解错误等一些人为因素而遗漏,也可能是由于数据采集设备的故障、存储介质的故障、传输媒体的故障等机械原因而丢失。
- 属性值不存在。在某些情况下,缺失值并不意味着数据有错误,对一些对象来说属性值是不存在的,如一个未婚者的配偶姓名、一个儿童的固定收入状况等。
缺失值的影响
- 数据挖掘建模将丢失大量的有用信息
- 数据挖掘模型所表现出的不确定性更加显著,模型中蕴涵的确定性成分更难把握
- 包含空值的数据会使挖掘建模过程陷入混乱,导致不可靠的输出
对缺失值做简单统计分析
- 统计缺失值的变量个数
- 统计每个变量的未缺失数
- 统计变量的缺失数及缺失率
缺失值处理
处理缺失值的方法可分为三类:删除记录、数据插补和不处理。其中常用的数据插补方法。

插值方法有Hermite插值、分段插值、样条插值法,而最主要的有拉格朗日插值法和牛顿插值法。
拉格朗日插值法

牛顿插值法

异常值
- 异常值分析是检验数据是否有录入错误以及含有不合常理的数据。忽视异常值的存在是十分危险的,不加剔除地把异常值包括进数据的计算分析过程中,对结果会带来不良影响;重视异常值的出现,分析其产生的原因,常常成为发现问题进而改进决策的契机。
- 异常值是指样本中的个别值,其数值明显偏离其余的观测值。异常值也称为离群点,异常值的分析也称为离群点的分析。
- 异常值分析方法主要有:简单统计量分析、3σ 原则、箱型图分析。
异常值分析方法
描述性统计
可以先做一个描述性统计,进而查看哪些数据是不合理的。需要的统计量主要是最大值和最小值,判断这个变量中的数据是不是超出了合理的范围,如身高的最大值为5米,则该变量的数据存在异常。
3σ 原则
如果数据服从正态分布,在3 原则下,异常值被定义为一组测定值中与平均值的偏差超过三倍标准差的值。在正态分布的假设下,距离平均值 3 之外的值出现的概率为
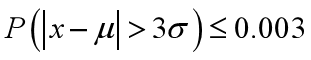
属于极个别的小概率事件。

箱型图分析
箱形图依据实际数据绘制,不需要事先假定数据服从特定的分布形式,没有对数据作任何限制性要求,它只是真实直观地表现数据分布的本来面貌;另一方面,箱形图判断异常值的标准以四分位数和四分位距为基础,四分位数具有一定的鲁棒性:多达25%的数据可以变得任意远而不会很大地扰动四分位数,所以异常值不能对这个标准施加影响,箱形图识别异常值的结果比较客观。由此可见,箱形图在识别异常值方面有一定的优越性。

异常值处理

一致性
数据不一致性是指数据的矛盾性、不相容性。直接对不一致的数据进行挖掘,可能会产生与实际相违背的挖掘结果。
在数据挖掘过程中,不一致数据的产生主要发生在数据集成的过程中,可能是由于被挖掘数据是来自于从不同的数据源、重复存放的数据未能进行一致性地更新造成的,比如两张表中都存储了用户的地址,在用户的地址发生改变时,如果只更新了一张表中的数据,那么这两张表中就有了不一致的数据。
















 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











