







目的:检查有没有不能服务于数据挖掘的数据。
分类:缺失值分析、异常值分析、一致性分析
缺失值分析
定义:一整个字段或者一个字段中某一部分信息的缺失
原因:数据拿不到;收集的时候粗心大意;对于特定对象来说该值本就不该存在
影响:影响很大
如何处理与分析:简单的统计分析;对缺失值进行删除、插补或不处理
异常值分析
定义:是否有不合常理的数据
影响:影响极大,忽视十分危险
分析方法:
简单统计量分析
对样本进行一个描述性统计。最常用的是看最大值最小值,看合不合理。
3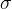 原则
原则
数据符合正态分布才能用。超过3事件发生的概率极小,可以判定为异常。(不懂的话请见b站《宋浩概率论与数理统计》)
箱型图分析(四分位点分析)
一些概念:

四分位数间距IQR:上四分位数-下四分位数
如何分析:在[下四分位数-1.5IQR,上四分位数+1.5IQR]这个区间之外的数为异常值
代码实现
(这个代码我用的是我的绝对路径)
# 代码3-1 使用describe()方法即可查看数据的基本情况
import pandas as pd#引用pandas库,用pd代表pandas库,使用pandas库的方法只要用pd.的形式就可以
catering_sale = 'D:\DataMiningCode\chapter3\demo\data\catering_sale.xls' # 餐饮数据
#catering_sale是这个文件的名称,直接写出这个文件的地址就可以表示这个文件,要注意最后要加上这个文件的名称和后缀,而且文件的地址
#分为绝对地址和相对地址(具体可以参见绝对路径与相对路径)
data = pd.read_excel(catering_sale, index_col = u'日期') # 读取数据,指定“日期”列为索引列
#这里用到了pandas库的read_excel方法,这个函数里面放文件名和索引列,并用data指向这个结果
print(data.describe())#先使用pd方法讲文件读出来,再将读出来的文件使用describe方法得到的结果如下:
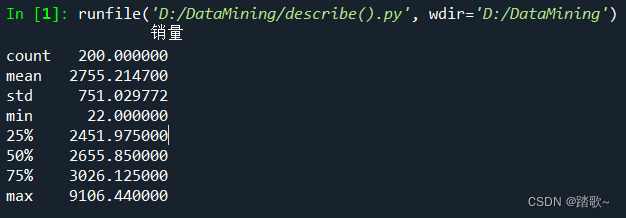
这些得到了 一些基本信息:count是这个表里面非空的数的个数;mean是平均值;std是这个表的非空数的标准差;min是最小值;25%是下四分位点;50%是中位数;75%是上四分位点;max是最大值。
依据这些基本信息,结合箱型图的原理可以得到IQR为75%-25%,然后用上四分位数加上1.5倍这个数、下四分位数减去1.5倍这个数,从而得到一个区间,在这个区间外的就是异常值(但是可以通过人工调整)。
在我运行的过程中出现了此错误:

解决办法为:
# 代码3-2 餐饮销额数据异常值检测
#这个代码使用箱型图函数筛选出异常值
#主要分为三个部分:准备引用、使用箱型图算法、处理展现异常值
#准备引用阶段
import pandas as pd#引用pandas库,用pd代表pandas库,使用pandas库的方法只要用pd.的形式就可以
catering_sale = 'D:\DataMiningCode\chapter3\demo\data\catering_sale.xls' # 餐饮数据
#catering_sale是这个文件的名称,直接写出这个文件的地址就可以表示这个文件,要注意最后要加上这个文件的名称和后缀,而且文件的地址
#分为绝对地址和相对地址(具体可以参见绝对路径与相对路径)
data = pd.read_excel(catering_sale, index_col = u'日期') # 读取数据,指定“日期”列为索引列
#这里用到了pandas库的read_excel方法,这个函数里面放文件名和索引列,并用data指向这个结果
#使用箱型图算法阶段,就是直接使用boxplot直接对读取的表进行箱型图的算法,直接生成箱型图
import matplotlib.pyplot as plt # 导入图像库
#一下两行代码是固定的你不必知道是什么意思,就是中文图像展示调整的固定语句
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure() # 建立图像
p = data.boxplot(return_type='dict') # 画箱线图,直接使用DataFrame的boxplot方法
#处理展现异常值阶段,这个地方难度过于的大,需要具体情况具体调整
#以下的三行代码应该是固定的调整代码
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() # 从小到大排序,该方法直接改变原对象
'''
用annotate添加注释
其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制
以下参数都是经过调试的,需要具体问题具体调试。
'''
for i in range(len(x)):#主要的调整代码,具体的参数是一点点试出来的
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() # 展示箱线图代码的运行截图如下:
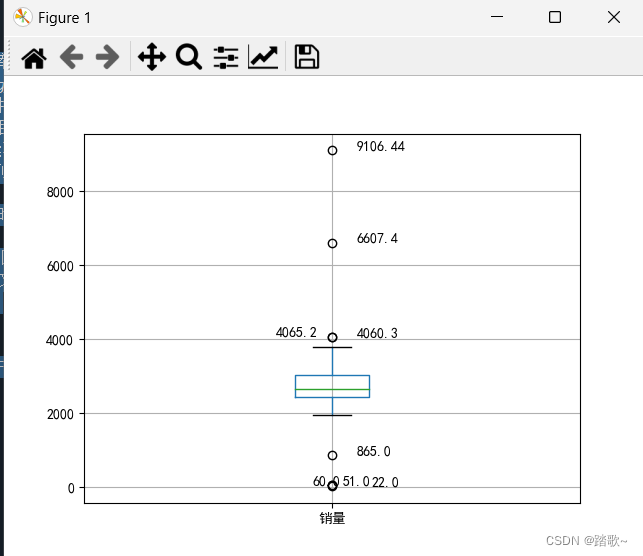
一致性分析
简单来讲就是对同一个对象不能有多个不相同的描述.
















 1499
1499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











