








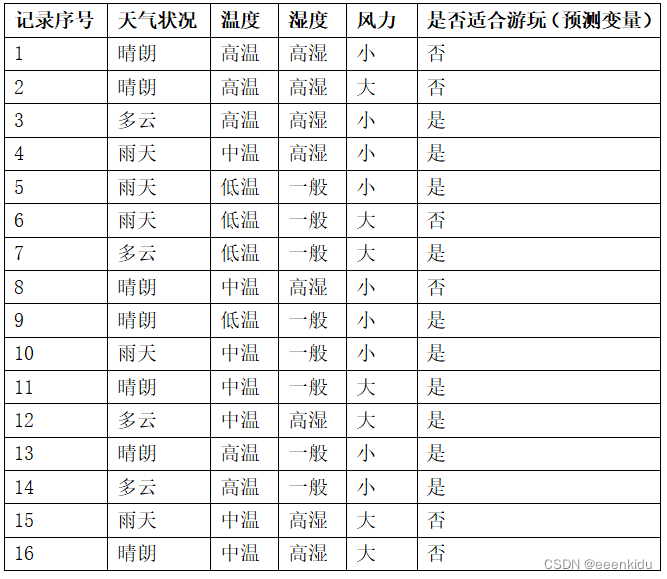
天气数据集
该数据集,已有的天气状况、温度、湿度还有风力信息,预测是否适合出去游玩。在算法设计中可以把天气状况、温度、湿度还有风力信息作为算法的输入,是否适合游玩作为输出结果。
代码实现
导入包
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from collections import defaultdict
import collections
import math
import pickle
import operator
定义属性、划分数据集
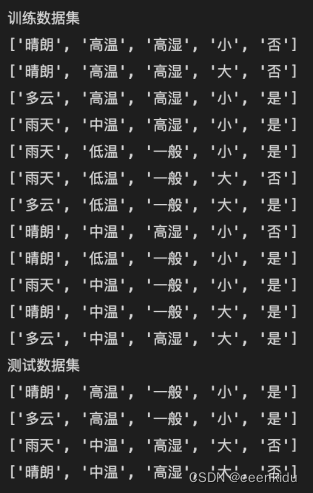
将1-12条作为训练数据集,13-16作为测试数据集
#定义属性值
outlook = ["晴朗", "多云","雨天"]
Temperature = ["高温", "中温","低温"]
Humidity = ["高湿","一般"]
Wind = ["大", "小"]
PlayTennis=["是","否"]
Play = []
Play.append(outlook)
Play.append(Temperature)
Play.append(Humidity)
Play.append(Wind)
Play.append(PlayTennis)
#数据集
data = [ ["晴朗","高温","高湿","小","否"],
["晴朗","高温","高湿","大","否"],
["多云","高温","高湿","小","是"],
["雨天","中温","高湿","小","是"],
["雨天","低温","一般","小","是"],
["雨天","低温","一般","大","否"],
["多云","低温","一般","大","是"],
["晴朗","中温","高湿","小","否"],
["晴朗","低温","一般","小","是"],
["雨天","中温","一般","小","是"],
["晴朗","中温","一般","大","是"],
["多云","中温","高湿","大","是"],
["晴朗","高温","一般","小","是"],
["多云", "高温", "一般", "小", "是"],
["雨天","中温","高湿","大","否"],
["晴朗","中温","高湿","大","否"]
]
length = len(data)
#划分数据集,将1-12条作为训练数据集,13-16作为测试数据集
train = data[:12]
train_length = len(train)
print("训练数据集")
for i in range(train_length):
print(train[i])
test= data[12:]
test_length = len(test)
print("测试数据集")
for i in range(test_length):
print(test[i])
朴素贝叶斯算法实现
- 提取数据集数据(见上)
- 分析处理数据集数据 (见上)
- 计算概率(先验概率、条件概率、联合概率)
- 根据贝叶斯公式计算预测概率
其中处理不同数据类型(伯努利,多项式,连续型)和0概率情况,还用到了: 概率密度函数、拉普拉斯平滑
def count_PlayTennis_total(data):
count = defaultdict(int)
for i in range(train_length):
count[data[i][4]]+=1
return count
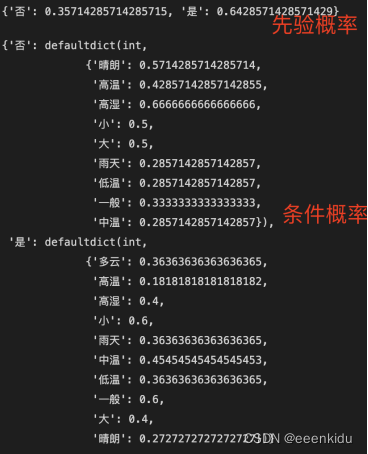
#先验概率
def cal_base_rates(data):
y = count_PlayTennis_total(data)
cal_base_rates = {}
for label in y.keys():
priori_prob = (y[label]+1) / (len(train)+2)
cal_base_rates[label] = priori_prob
return cal_base_rates
print(cal_base_rates(train))
def count_sj(attr, Play):
for i in range(len(Play)):
if attr in Play[i]:
return len(Play[i])
#似然概率p(x|y) 也叫条件概率
def likelihold_prob(data):
#计算各个特征值在已知结果下的概率(likelihood probabilities)
y = count_PlayTennis_total(data)
likelihold = {}
for i,c in y.items():
#创建一个临时的字典,临时存储各个特征值的概率
attr_prob = defaultdict(int)
for j in range(train_length):
if data[j][4]==i:
for attr in range(4):
attr_prob[data[j][attr]]+=1
for keys,values in attr_prob.items():
sj = count_sj(keys, Play)
attr_prob[keys]=(values+1)/(c+sj)
likelihold[i] = attr_prob
return likelihold
LikeHold = likelihold_prob(train)
def Test(data,test):
y = count_PlayTennis_total(data)
likehold = likelihold_prob(data)
playtennis = cal_base_rates(data)
RATE = defaultdict(int)
print(test)
for i, _ in y.items():
rates=1
for j in range(4):
attr = test[j]
rates *= likehold[i][attr]
rates=rates * playtennis[i]
RATE[i] = rates
print("预测结果: " )
print(RATE)
return sorted(RATE,key=lambda x:RATE[x])[-1]
#先验概率
cal_base_rates(train)
# 条件概率
likelihold_prob(train)
结果预测
Test(train,test[0][:4])

Test(train,test[1][:4])

Test(train,test[2][:4])

Test(train,test[3][:4])

决策树算法实现
- 特征选择:分别计算特征分类后的类别,然后选择合适的类别,然后选择合适的类别
- 构建决策树
1)从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征。
2)由该特征的不同取值建立子节点,再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止;
3)最后得到一个决策树。
#计算信息熵
def cal_entropy(dataset):
length = len(dataset)
entropy = 0
count = {}
for i in dataset:
label = i[-1]
count[label] = count.get(label, 0) + 1
for key in count:
p = count[key] / length
entropy = entropy - p * math.log(p, 2)
return entropy
#划分数据集
def splitDataSet(dataSet, axis, value):
childDataSet = []
for i in dataSet:
if i[axis] == value:
childList = i[:axis]
childList.extend(i[axis + 1:])
childDataSet.append(childList)
# print(childDataSet)
return childDataSet
#选择最好的特征
def chooseFeature(dataset):
old_entropy = cal_entropy(dataset)
character = -1
for i in range(len(dataset[0]) - 1):
newEntropy = 0
featureList = [word[i] for word in dataset]
value = set(featureList)
for j in value:
childDataSet = splitDataSet(dataset, i, j)
newEntropy += len(childDataSet) / len(dataset) * cal_entropy(childDataSet)
if (newEntropy < old_entropy):
character = i
old_entropy = newEntropy
return character
#当遍历完所有特征时,用于选取当前数据集中最多的一个类别代表该类别
def most(classList):
classCount = {}
for i in range(len(classList)):
classCount[i] = classCount.get(i, 0) + 1
sortCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# print(sortCount)
return sortCount[0][0]
#构造决策树
def createDT(dataSet, labels):
# print(dataSet)
tempLabels=labels[:]
classList = [word[-1] for word in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return most(dataSet)
character = chooseFeature(dataSet)
node = tempLabels[character]
myTree = {node: {}}
del (tempLabels[character])
featureList = [word[character] for word in dataSet]
value = set(featureList)
for i in value:
newLabels = tempLabels
myTree[node][i] = createDT(splitDataSet(dataSet, character, i), newLabels)
return myTree
#分类
def classify(dTree, labels, testData):
node = list(dTree.keys())[0]
condition = dTree[node]
labelIndex = labels.index(node)
classLabel=None
print(testData)
for key in condition:
if testData[labelIndex] == key:
if type(condition[key]).__name__ == 'dict':
# print("预测结果: " )
classLabel=classify(condition[key], labels, testData)
else:
print("预测结果: " )
classLabel = condition[key]
return classLabel
#用于将构建好的决策树保存,方便下次使用
def stroeTree(myTree,filename):
f=open(filename,'wb')
pickle.dump(myTree,f)
f.close()
#载入保存的决策树
def loadTree(filename):
f=open(filename,'rb')
return pickle.load(f)
labels = ['天气状况','温度','湿度','风力','是否适合游玩(预测变量)']
myTree=createDT(train, labels )
stroeTree(myTree,'1')
myTree=loadTree('1')
print(myTree)

结果预测
classify(myTree,labels,test[0][:4])

classify(myTree,labels,test[1][:4])

classify(myTree,labels,test[2][:4])

classify(myTree,labels,test[3][:4])

















 1915
1915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











