







1. 从尾到头打印链表

1. 辅助数组法(直观做法)
第一遍先遍历链表,将链表数据存在vector中,第二遍逆序遍历vector,将vector插入新的vector中实现逆序,最后输出。遍历两遍, T ( n ) = O ( N ) T(n)=O(N) T(n)=O(N),两个vector, S ( n ) = O ( N ) S(n)=O(N) S(n)=O(N)
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* ListNode(int x) :
* val(x), next(NULL) {
* }
* };
*/
class Solution {
public:
vector<int> printListFromTailToHead(ListNode* head) {
vector<int> vec;
int TmpVal;
vector<int> results;
if(head==nullptr)
return vec;
else
{
while(head)
{
vec.push_back(head->val);
head = head->next;
}
for(int i=vec.size()-1; i>=0; --i)
results.push_back(vec[i]);
return results;
}
}
};
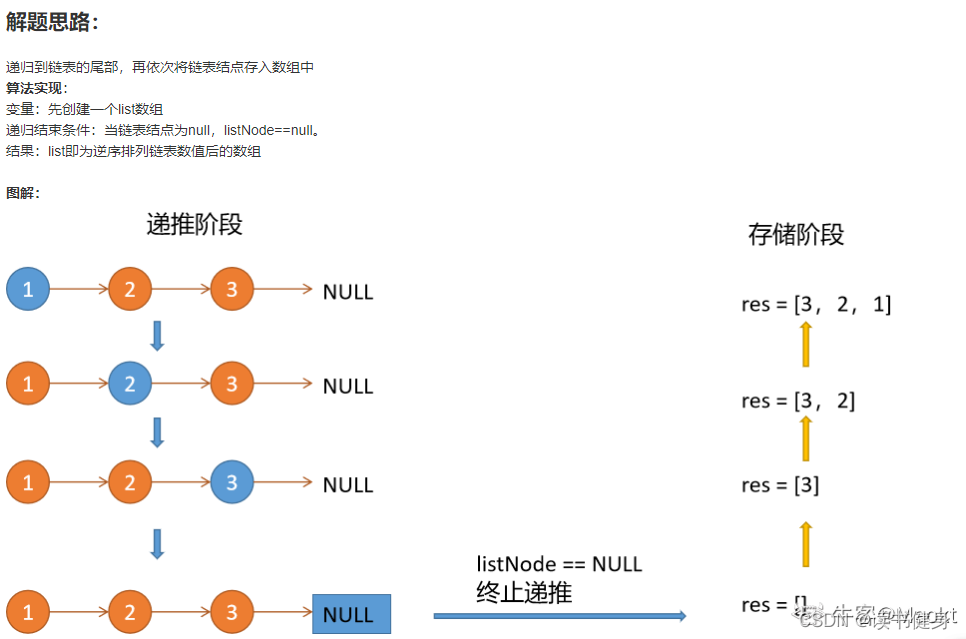
2. 使用递归
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* ListNode(int x) :
* val(x), next(NULL) {
* }
* };
*/
class Solution {
public:
// 递归遍历链表
void recursion(ListNode* head, vector<int>& res)
{
if(head)
{
//先往链表深处遍历
recursion(head->next, res);
//再填充到数组就是逆序
res.push_back(head->val);
}
}
vector<int> printListFromTailToHead(ListNode* head)
{
vector<int> res;
//递归
recursion(head, res);
return res;
}
};
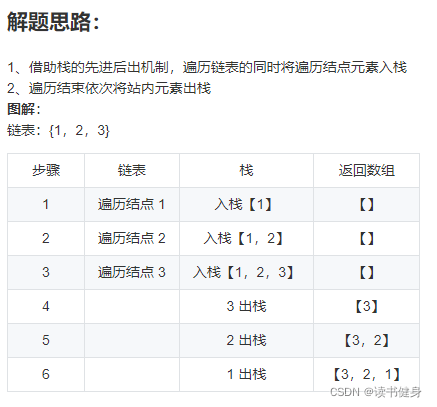
3. 使用栈(基于vector实现,好理解)
这个和两遍遍历法很像,运行的时间和空间消耗也相近,只是这里使用了栈顶指针来判断栈是否空。
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* ListNode(int x) :
* val(x), next(NULL) {
* }
* };
*/
// 使用栈实现,LIFO后入先出
//push时先递增指针,再push;
//pop时先pop再递减指针
class Solution {
public:
vector<int> printListFromTailToHead(ListNode* head) {
vector<int> results;
//1.是否为空链表
if(head==nullptr)
return results;
//2.非空链表
else
{
//2.1.建立栈
int Stack_ptr=-1;
vector<int> Stack;
//2.2.链表中所有元素入栈(先递增指针,再入栈)
while(head!=nullptr)
{
++Stack_ptr;
Stack.push_back(head->val);
head = head->next;
}
//3.所有元素出栈(先出栈,再递减指针)
while(Stack_ptr>=0)
results.push_back(Stack[Stack_ptr--]);
return results;
}
}
};
4. 使用STL中的stack(方便)
注意其中的函数:stack.empty()判断栈是否空,top()取栈顶元素的引用,pop()删除栈顶元素,但不会像python一样返回删除的值,仅仅是删除掉。
// 使用STL的stack(栈)版本,还是先遍历链表入栈,然后出栈
class Solution {
public:
vector<int> printListFromTailToHead(ListNode* head)
{
vector<int> Res;
stack<int> TmpStack;
if(head==nullptr)
return Res;
else
{
while(head)
{
TmpStack.push(head->val);
head = head->next;
}
while(!TmpStack.empty())
{
Res.push_back(TmpStack.top());
TmpStack.pop();
}
return Res;
}
}
};
5. 扩展
还有类似这种简单粗暴的,:
class Solution {
public:
vector<int> printListFromTailToHead(ListNode* head) {
vector<int> A;
while (head) {
A.push_back(head->val);
head = head->next;
}
reverse(A.begin(), A.end());
return A;
}
};
这种实际上就是交换了vector中的一半元素:
头插法(基于链表实现的堆栈也是头插法建立的):
vector<int> printListFromTailToHead(struct ListNode* head) {
vector<int> v;
while(head != NULL)
{
v.insert(v.begin(),head->val);
head = head->next;
}
return v;
}
每次都往v的头部插入,如此实现了链表的逆序。
6. 本题小结
因为链表只能正序访问,所以为了逆序访问,我们需要先遍历其数据,然后逆序输出,如何逆序输出是本题的重点。
这里可以使用 辅助数组、堆栈、递归、交换:
- vector直接使用随机访问器,通过下标来实现逆序输出,
- 而堆栈由于是LIFO(先入后出),本来就是逆序访问,所以更易理解,可以自行基于数组或者链表实现堆栈,或者使用STL中的容器适配器stack,涉及函数top(value_type)->value_type&, push(), pop()。
- 递归则更易理解,直接递归到链表的最深处,直到不能再深时开始逐渐往Res中push_back(val),就实现了逆序。
- reverse()实际上就是交换了vector中的一半元素,直接写的话就是:
for(int i=0; i<Res.size()/2;++i)
{
tmp = Res[i];
Res[i] = Res[Res.size()-i-1];
Res[Res.size()-i-1] = tmp;
}
2. JZ24 反转链表
1. 递归方法(反向时处理)
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
//递归翻转链表,这是在反向返回的时候进行逻辑处理
class Solution {
public:
ListNode* recursion(ListNode* first, ListNode* second)
{
ListNode* RHead = nullptr;
if(second)
{
RHead = recursion(first->next, second->next);
first->next = nullptr; //先把first的指针置空,然后再second指向first,否则会出现环
second->next = first;
return RHead;
}
else
return first;
}
ListNode* ReverseList(ListNode* pHead) {
ListNode* RHead = nullptr;
if(pHead!=nullptr)
{
RHead = recursion(pHead, pHead->next);
pHead = nullptr; //头节点置空
}
return RHead;
}
};
2. 递归(正向时处理)
//递归翻转链表,这是在正向时进行逻辑处理
class Solution {
public:
ListNode* recursion(ListNode* first, ListNode* second)
{
if(second==nullptr)
return first;
else
{
ListNode* new_second = second->next;
second->next = first;
return recursion(second, new_second); //前处理时进行反转;
}
}
ListNode* ReverseList(ListNode* pHead) {
return recursion(nullptr, pHead);
}
};
只有在反向调用的时候才会出现环,因为反向时把next回指,但是按照链表的顺序还是会从左到右访问,就会出现环;但是正向处理的时候因为new_second已经和已经处理过的环无关,按照已经处理过的环进行访问,访问不到new_second,所以递归时不会出现环。
3. 头插法(效率稍低,但比递归直观)
class Solution {
public:
ListNode* ReverseList(ListNode* pHead)
{
ListNode* raw_head = pHead; //原链表头节点
ListNode* tmp_raw_head; //原链表下一个结点备份
ListNode* res_head=nullptr; //结果链表头节点
while(raw_head)
{
tmp_raw_head = raw_head->next; //原链表下一个元素备份
raw_head->next = res_head; //raw头节点指向res头节点
res_head = raw_head; //头节点更新
raw_head = tmp_raw_head; //原链表头节点更新
}
return res_head;
}
};
4. 使用栈
这个不是 O ( 1 ) O(1) O(1)的空间复杂度,但确实也好理解。
//栈处理:先把所有链表入栈,然后再出栈,构成新链表(这样还是O(1)的空间复杂度吗?)
class Solution {
public:
ListNode* ReverseList(ListNode* pHead)
{
stack<ListNode*> Stack;
ListNode* ResHead = nullptr;
ListNode* TmpNode;
// 入栈
while(pHead)
{
Stack.push(pHead);
pHead = pHead->next;
}
if(!Stack.empty())
{
ResHead = Stack.top();
TmpNode = ResHead;
Stack.pop();
// 出栈
while(!Stack.empty())
{
TmpNode->next = Stack.top();
TmpNode = Stack.top();
Stack.pop();
}
TmpNode->next = nullptr; //避免构成环
}
return ResHead;
}
};
5. O(1)解法
管理两个指针,first和second,使second指向first,但在指向之前要保存second->next,直到second==nullptr。另外处理空结点和单节点的情况。
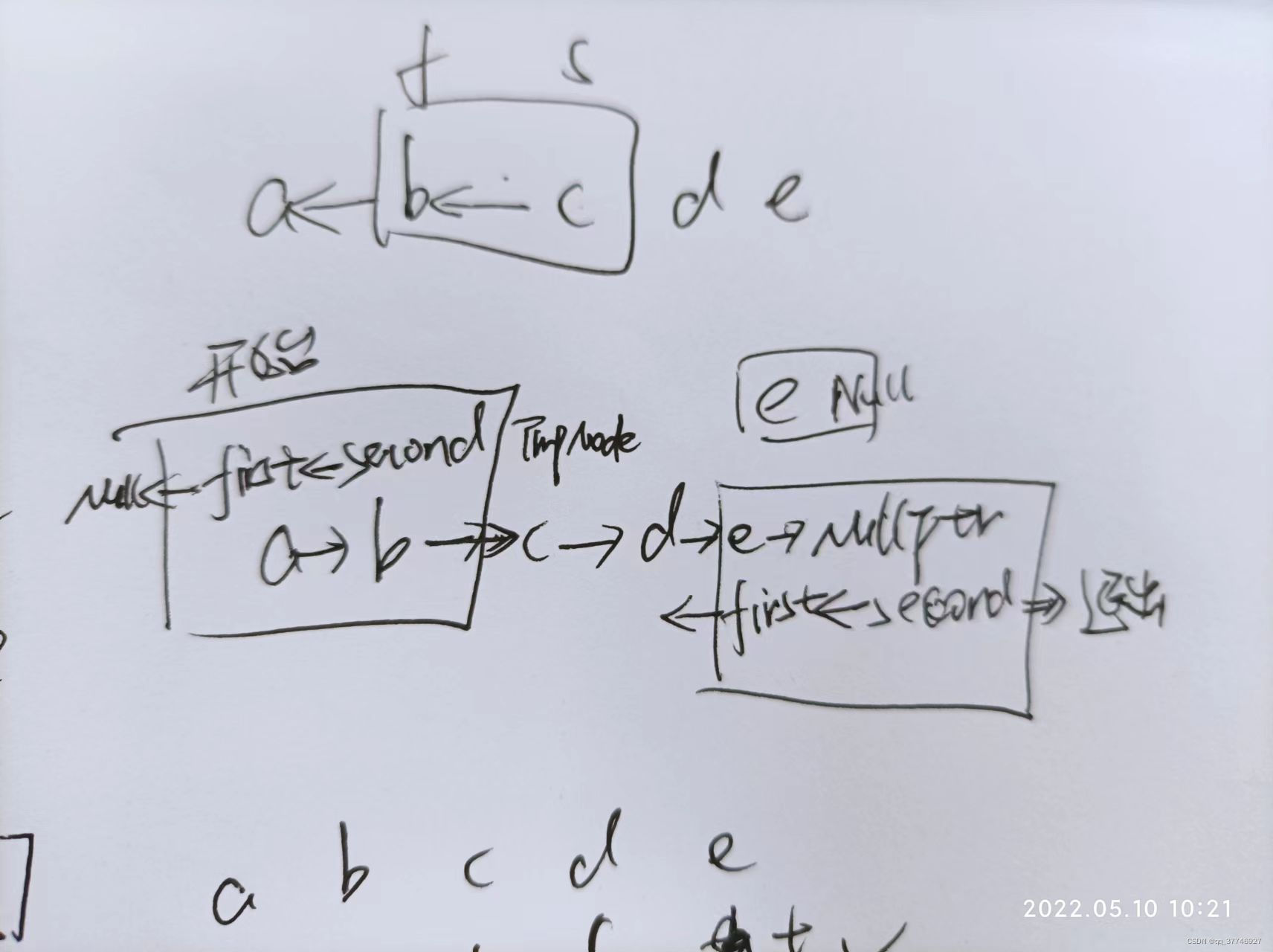
//递归
class Solution {
public:
ListNode* ReverseList(ListNode* pHead)
{
//处理
if(pHead==nullptr || pHead->next==nullptr) return pHead;
ListNode* First = pHead;
ListNode* Second = First->next;
while(Second)
{
if(First==pHead) First->next = nullptr;
ListNode* TmpNode = Second->next;
Second->next = First;
First = Second;
Second = TmpNode;
}
return First;
}
};
6. 本题小结
本题推荐使用栈,但不是O(1)空间复杂度,分别将链表入栈,然后出栈,即完成反向操作。
O(1)的空间复杂度建议使用头插法,分别将raw的头结点指向res,然后更新rres和aw。
- 递归的模板
终止条件,递归调用,逻辑处理。(条递逻) - 头插法:复指更更(1.复制下一个要插入的结点,2.新插入的节点指向被插入的链表的头节点,3.更新被插入链表的头节点,4.用1的结点更新待插入结点)
- 有关链表的反向操作,使用栈都比较直观简单。
3. JZ25 合并两个排序的链表
1. 自己的遍历链表合并法
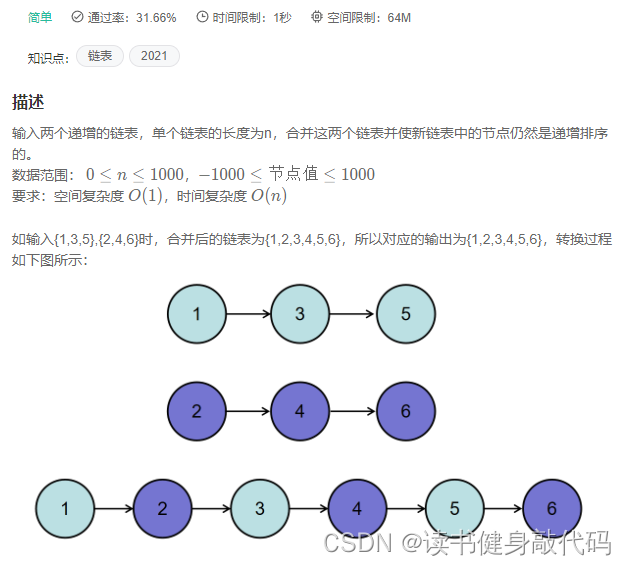
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
//思路:O(1)的空间复杂度,就是不开辟新的存储空间进行合并,2往1中插,遍历两个链表,比较大小,找插入点,插入。
class Solution {
public:
ListNode* Merge(ListNode* pHead1, ListNode* pHead2) {
ListNode* P1(pHead1);
ListNode* P2(pHead2);
ListNode* TmpP1(nullptr);
ListNode* TmpP2(nullptr);
ListNode* Res(nullptr);
ListNode* LastP1(nullptr);
ListNode* NextP2(nullptr);
if(P1==nullptr)
return P2;
if(P2==nullptr)
return P1;
else //两个链表非空
{
Res = P1;
while(P2)
{
if(P2->val >= P1->val) //P2更大,尾插
{
//寻找P1中的尾插点
while(P2->val >= P1->val)
{
LastP1 = P1;
P1 = P1->next;
//如果P1到尾部还是比P2小,那么直接把P2及之后所有的链表插在P1最后一个结点
if(P1==nullptr)
{
LastP1->next = P2;
return Res;
}
}
//找到了尾插点,跳出循环
//尾插
NextP2 = P2->next;
LastP1->next = P2;
P2->next = P1;
P1 = P2;
P2 = NextP2;
}
else //P2更小,头插,只可能是在P1的头节点
{
NextP2 = P2->next;
P2->next = P1;
P1 = P2;
Res = P1;
P2 = NextP2;
}
}
return Res;
}
}
};

2. 使用栈(头插法)
不符合
O
(
1
)
O(1)
O(1)的空间复杂度,但避免了复杂的指针操作,好理解,结果也还行。
但后来想想没有必要用栈,直接用一个辅助数组比较大小,然后按顺序插入即可。
//思路:使用栈,将两个链表入栈,然后同时先后出栈,新建链表,在出栈时比较大小,做头插,大的插入,再出,再比较,如此循环
class Solution {
public:
ListNode* Merge(ListNode* pHead1, ListNode* pHead2) {
stack<ListNode*> sta1,sta2;
ListNode* P1(pHead1);
ListNode* P2(pHead2);
ListNode* Res(nullptr);
ListNode* TmpP1(nullptr);
ListNode* TmpP2(nullptr);
if(P1==nullptr)
return P2;
if(P2==nullptr)
return P1;
// 入栈
while(P1)
{
sta1.push(P1);
P1 = P1->next;
}
while(P2)
{
sta2.push(P2);
P2 = P2->next;
}
//出栈
//当两栈同时不空时进行出栈比较
while(!sta1.empty() && !sta2.empty())
{
TmpP1 = sta1.top();
TmpP2 = sta2.top();
//P2大,插
if(TmpP2->val >= TmpP1->val)
{
TmpP2->next = Res;
Res = TmpP2;
sta2.pop();
//如果某一个栈空了就直接跳出比较的循环,直接将另一个栈元素全部插入
if(sta2.empty())
break;
TmpP2 = sta2.top();
}
//P1大,插
else
{
TmpP1->next = Res;
Res = TmpP1;
sta1.pop();
//如果某一个栈空了就直接跳出比较的循环,直接将另一个栈元素全部插入
if(sta1.empty())
break;
TmpP1 = sta1.top();
}
}
// sta2空了
if(sta2.empty())
{
while(!sta1.empty())
{
TmpP1 = sta1.top();
TmpP1->next = Res;
Res = TmpP1;
sta1.pop();
}
}
//sta1空了
else
{
while(!sta2.empty())
{
TmpP2 = sta2.top();
TmpP2->next = Res;
Res = TmpP2;
sta2.pop();
}
}
return Res;
}
};

3. 比较尾插法(最简洁,定义虚拟节点,推荐)
这个不是开辟新的内存,本身还是对指针进行操作,满足空间O(1),定义虚拟节点非常省事。
//思路:比较尾插法。定义虚拟节点,方便保存结果。同时遍历两个链表,对元素进行比较,小的插入res。
class Solution {
public:
ListNode* Merge(ListNode* pHead1, ListNode* pHead2) {
ListNode* res = new ListNode(-1); //定义虚拟节点
ListNode* resptr = res; //定义结果尾指针
while(pHead1 && pHead2)
{
//P2小,插入P2
if(pHead1->val >= pHead2->val)
{
resptr->next = pHead2;
pHead2 = pHead2->next;
}
//P1小
else
{
resptr->next = pHead1;
pHead1 = pHead1->next;
}
resptr = resptr->next;
}
if(pHead1==nullptr)
resptr->next = pHead2;
else
resptr->next = pHead1;
return res->next;
}
};
4. 本题小结
本题推荐方法3。
自己的思路是往链表1中插,所以就把思路局限在了寻找插入点,但实际上由于是指针操作,不必要非得从“往链表1中插入”这个角度来思考。因为链表本身是升序,故遍历两个链表,取出头节点比较,把小的查到结果链表中即可,定义虚拟头节点作为res结点更方便,返回res->next即可。
4. JZ52 两个链表的第一个公共结点
1. 我的set和别人的map
set用的find方法,返回迭代器,非.end()迭代器就代表找到了
map是将value_type设为1,有if(map[key])则就知道key在不在了。
总体来讲还是比较简单的。
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
//使用map<ListNode *, ListNode *->next>来存储此节点和其next结点的地址,从前往后,如果next地址匹配上,就说明是第一个公共节点
class Solution {
public:
ListNode* FindFirstCommonNode( ListNode* pHead1, ListNode* pHead2) {
set<ListNode*> set1;
//遍历list1,存入map1
while(pHead1)
{
set1.insert(pHead1);
pHead1 = pHead1->next;
}
while(pHead2)
{
auto find_result = set1.find(pHead2);
if(find_result!=set1.end()) //如果找到,则证明是第一个公共节点
{
return *find_result;
}
else
pHead2 = pHead2->next;
}
return nullptr;
}
};
// //用map做的,时间复杂度O(nlog(n))
// class Solution {
// public:
// ListNode* FindFirstCommonNode( ListNode *pHead1, ListNode *pHead2) {
// map<ListNode*, int> m;
// ListNode *p = pHead1;
// while(p != NULL) {
// m[p] = 1;
// p = p->next;
// }
// p = pHead2;
// while(p != NULL) {
// if(m[p]) {
// return p;
// }
// p = p->next;
// }
// return NULL;
// }
// };
2. 本题小结
灵活使用map和set,主要是map的访问能看有没有元素,下面的力扣的count方法看键存不存在,而值是我们要的下标,这里的map只用了存不存在的属性;而set主要就用.find(x)方法查找对应的key存不存在。

map的查找时间复杂度为O(1)。

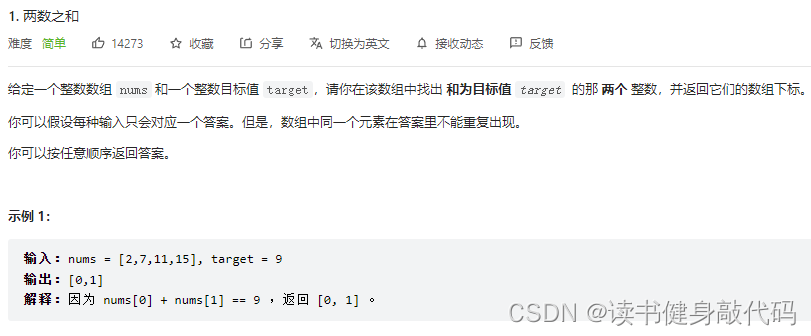
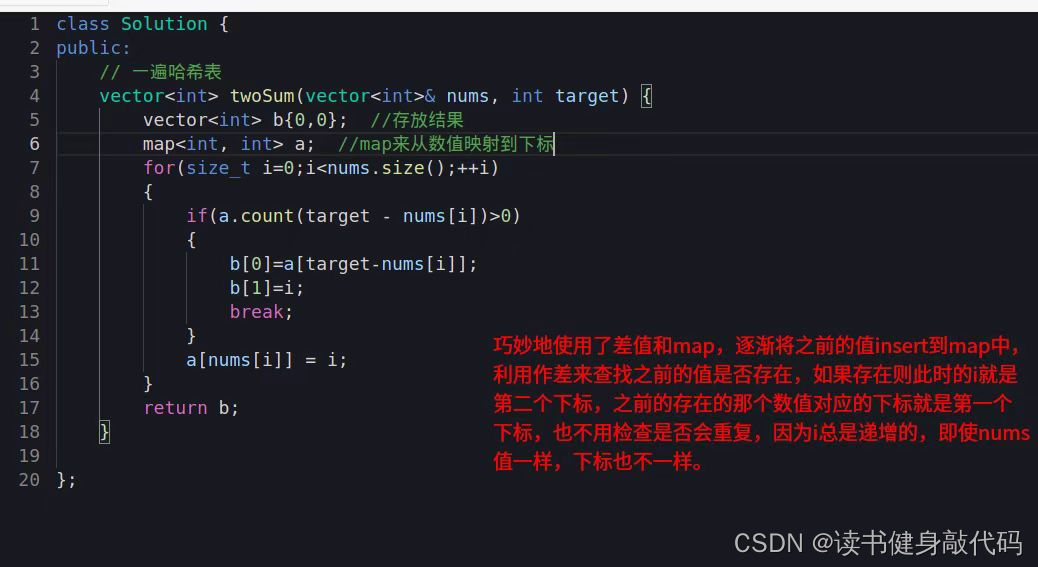
拓展. leetcode_T1
5. JZ23 链表中环的入口结点
1. set / map方法
时间复杂度有些高。
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};
*/
//set方法,时间复杂度O(N^2),遍历链表,依次查找在已有的set中是否找到新节点的地址,若没有,则将新节点的地址插入set中。
class Solution {
public:
ListNode* EntryNodeOfLoop(ListNode* pHead) {
set<ListNode*> PtrSet;
ListNode* Res(nullptr);
while(pHead)
{
if(PtrSet.find(pHead)!=PtrSet.end())
return pHead;
PtrSet.insert(pHead);
pHead = pHead->next;
}
return nullptr;
}
};
map方法
//map方法
class Solution {
public:
ListNode* EntryNodeOfLoop(ListNode* pHead) {
map<ListNode*, bool> PtrMap;
ListNode* Res(nullptr);
while(pHead)
{
if(PtrMap[pHead])
return pHead;
PtrMap[pHead] = true;
pHead = pHead->next;
}
return nullptr;
}
};
2.拓展:BM6 判断链表中是否有环
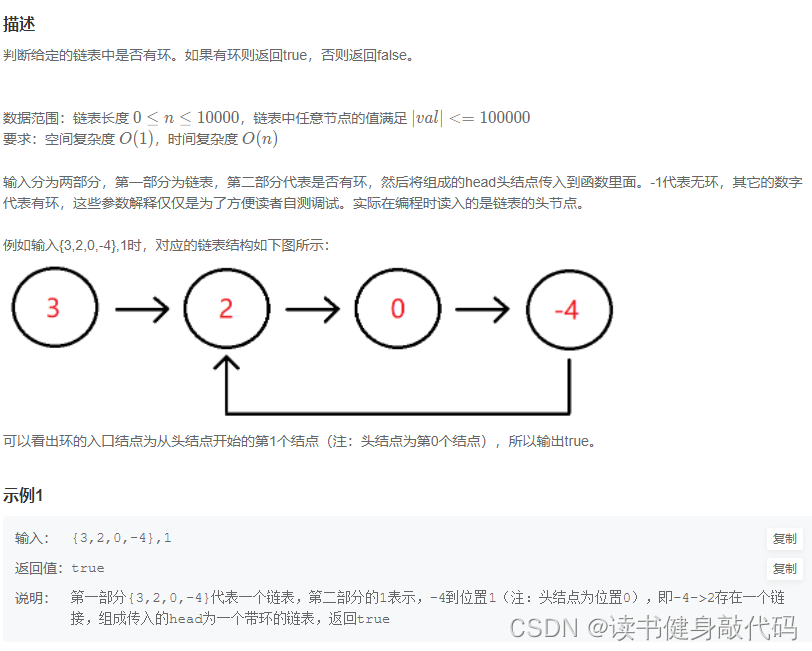
使用set的方法每次都要在set中找,效率有点低,引入双指针法

对比下面两段代码,对条件先进行判断的效率会更高:
- 先对快指针即将到达的结点进行判断:
class Solution {
public:
bool hasCycle(ListNode *head) {
ListNode * fast(head);
ListNode * slow(head);
while(fast && fast->next)
{
fast = fast->next->next;
slow = slow->next;
if(fast==slow)
return true;
}
return false;
}
};
- 只对快指针本身进行判断,移到那个地方再判断是否为空。
这种方法每次多了一个判断,所以效率稍微低一些,属于细节问题。
class Solution {
public:
bool hasCycle(ListNode *head) {
ListNode * fast(head);
ListNode * slow(head);
while(fast)
{
fast = fast->next;
if(fast==nullptr)
return false;
fast = fast->next;
slow = slow->next;
if(fast==slow)
return true;
}
return false;
}
};
3. 双指针法
本题官方解析
有了双指针的基础,再来看这道题,这道题在有环的基础上要求找出环的入口结点,分析如下:
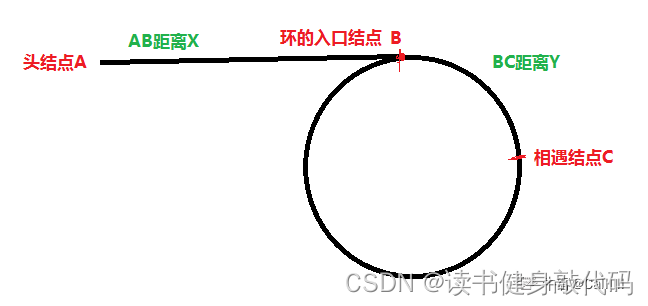
参考官方解释和评论区大佬的理解

自己来推导一遍:
如上图所示,设
A
B
=
a
,
B
C
=
b
,
C
B
=
c
AB=a,BC=b,CB=c
AB=a,BC=b,CB=c,设环长度为r,则
r
=
b
+
c
r=b+c
r=b+c,第一遍快慢指针时,由于
s
t
e
p
f
a
s
t
=
2
,
s
t
e
p
s
l
o
w
=
1
step_{fast}=2,step_{slow}=1
stepfast=2,stepslow=1,快指针步长是慢指针的两倍,记距离为d,所以在相同循环次数下,
d
f
=
2
d
s
d_f=2d_s
df=2ds,设第一次相遇时快指针已转了
n
n
n圈,慢指针转了
m
m
m圈,于是有
d
f
=
a
+
n
(
b
+
c
)
+
b
d_f = a+n(b+c)+b
df=a+n(b+c)+b
d
s
=
a
+
m
(
b
+
c
)
+
b
d_s=a+m(b+c)+b
ds=a+m(b+c)+b
根据
d
f
=
2
d
s
d_f=2d_s
df=2ds,
a
+
n
(
b
+
c
)
+
b
=
2
∗
[
a
+
m
(
b
+
c
)
+
b
]
a+n(b+c)+b=2 * [a+m(b+c)+b]
a+n(b+c)+b=2∗[a+m(b+c)+b]
化简得
a
+
b
=
(
n
−
2
m
)
r
a+b=(n-2m)r
a+b=(n−2m)r
移项
a
=
(
n
−
2
m
)
r
−
b
a=(n-2m)r-b
a=(n−2m)r−b
凑
r
r
r得
a
=
(
n
−
2
m
)
r
−
b
−
c
+
c
=
(
n
−
2
m
−
1
)
r
+
c
a=(n-2m)r-b-c+c=(n-2m-1)r+c
a=(n−2m)r−b−c+c=(n−2m−1)r+c
意思是从A走a 和 从C走c加上若干个完整环的路程相同,那就分别将两个指针放在A和C处,以相同的步长
s
t
e
p
=
1
step=1
step=1再走一次,走到即相遇,即得入口结点。
官方只给到 a + b = ( n − 2 m ) r a+b=(n-2m)r a+b=(n−2m)r这里, a + b = ( n − 2 m ) ( b + c ) a+b=(n-2m)(b+c) a+b=(n−2m)(b+c)移项凑 r r r得 a = ( n − 2 m − 1 ) r + c a=(n-2m-1)r+c a=(n−2m−1)r+c是理解的难点,推导到这里就知道把指针放到A,C点再走一次这个做法的原理了。
// 快慢指针
class Solution {
public:
//判断有没有环,返回相遇的地方
ListNode * hasCycle(ListNode *head) {
ListNode * fast(head);
ListNode * slow(head);
while(fast && fast->next)
{
fast = fast->next->next;
slow = slow->next;
if(fast==slow)
return fast;
}
return nullptr;
}
ListNode* EntryNodeOfLoop(ListNode* pHead)
{
ListNode* Fast(pHead);
ListNode* Slow(nullptr);
ListNode* MeetPoint = hasCycle(pHead);
if(MeetPoint)
{
//快指针从头开始,慢指针从相遇点开始,二者每次一步,再次相遇即是入口结点
Slow = MeetPoint;
while(Fast!=Slow)
{
Fast = Fast->next;
Slow = Slow->next;
}
return Fast;
}
return nullptr;
}
};
4. 本题小结
- 针对环的存在问题,灵活使用双指针来提高查找效率,此处使用了同向的快慢指针;
- s t e p f a s t = 2 step_{fast}=2 stepfast=2, s t e p s l o w = 1 step_{slow}=1 stepslow=1,由于 s t e p step step步长差为1,所以若有环,必相遇;
- 结合推导,相遇后,fast置于起点,slow不动,相同步长继续走,相遇即入口。
6. 删除链表的节点
1. 遍历删除(推荐)
借助虚拟节点(真的好用)
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @param val int整型
* @return ListNode类
*/
ListNode* deleteNode(ListNode* head, int val) {
// write code here
ListNode* Res = new ListNode(-1); //定义虚拟头节点用于保存结果链表
Res->next = head;
ListNode* LastPtr(Res);
while(head)
{
if(head->val==val)
{
LastPtr->next = head->next;
break;
}
else
{
LastPtr = head;
head = head->next;
}
}
return Res->next;
}
};
2. 使用map
将下个结点的值映射到上个结点的地址。
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* ListNode(int x) : val(x), next(nullptr) {}
* };
*/
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @param val int整型
* @return ListNode类
*/
ListNode* deleteNode(ListNode* head, int val) {
// write code here
map<int, ListNode*> map1;
ListNode* Res = new ListNode(-1); //定义虚拟头节点用于保存结果链表
ListNode* LastPtr(nullptr);
ListNode* ThisPtr(nullptr);
Res->next = head;
head = Res;
//保存这个结点的地址和下个结点的值
while(head->next)
{
//将下个结点的值映射到上个结点的地址
map1[head->next->val] = head;
head = head->next;
}
//如果有待删除的值则进行删除
if(map1.count(val))
{
LastPtr = map1[val];
//头节点因为有虚拟节点,不用管
//尾结点
if(LastPtr->next->next==nullptr)
LastPtr->next = nullptr;
else
{
ThisPtr = LastPtr->next;
LastPtr->next = LastPtr->next->next; //删除结点
ThisPtr = nullptr;
}
}
return Res->next;
}
};
3. 本题小结
链表这种数据结构大部分是对指针进行操作,所以可以的话尽量不要使用额外的空间,申请个虚拟头节点已经够用了。
7. JZ22 链表中倒数最后k个结点(easy)
1. 使用栈
时间空间复杂度均为 O ( n ) O(n) O(n)
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pHead ListNode类
* @param k int整型
* @return ListNode类
*/
//使用栈
ListNode* FindKthToTail(ListNode* pHead, int k) {
// write code here
stack<ListNode * > sta1;
ListNode * Res(nullptr);
unsigned int count=0;
while(pHead)
{
sta1.push(pHead);
pHead = pHead->next;
++count;
}
if(0<k && k<=count)
{
for(unsigned int i=0; i<k-1; ++i)
sta1.pop();
Res = sta1.top();
}
return Res;
}
};
2. 两遍遍历法
第一遍取得整个链表的节点个数,与k求差即得待取的结点的正向序号m,第二遍遍历到第m个结点即可。
时间复杂度O(n),空间复杂度O(1)。
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pHead ListNode类
* @param k int整型
* @return ListNode类
*/
//两边遍历法
ListNode* FindKthToTail(ListNode* pHead, int k) {
// write code here
ListNode * TmpPtr(pHead);
ListNode * Res(nullptr);
int Count = 0;
int Begin = 0;
while(TmpPtr)
{
TmpPtr = TmpPtr->next;
++Count;
}
//判断大小
if(0<k && k<=Count)
{
Begin = Count - k + 1;
for(int i=0; i<Begin; ++i)
{
Res = pHead;
pHead = pHead->next;
}
}
return Res;
}
};
3. 双指针法(快慢指针,推荐)
思考:待取结点时导数第 k k k个,距离表尾的距离是 k k k,那么分别用两个指针 P 1 P_1 P1指向表尾和 P 2 P_2 P2倒数第k个,一起向前移动,当 P 1 P_1 P1到达表头时, P 1 P_1 P1和 P 2 P_2 P2的距离仍然是 k k k,启发而的,先让快指针走到第 k k k个,然后慢指针从表头再出发,等快指针到表尾null时,慢指针即到倒数第 k k k个。
编程细节:当for循环还在循环体内部时,证明还没到循环结束的条件,如果此时快指针已经走到了头,但是循环还没结束的话,就证明k太大了,超过了链表的长度,直接返回nullptr。
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* ListNode(int x) : val(x), next(nullptr) {}
* };
*/
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pHead ListNode类
* @param k int整型
* @return ListNode类
*/
//快慢指针法
ListNode* FindKthToTail(ListNode* pHead, int k) {
ListNode * Fast(pHead);
ListNode * Slow(pHead);
//特殊情况在内部处理
//快指针出发
if(k==0 || pHead==nullptr)
return nullptr;
//倒数第k个两指针之间相差k-1
for(int i=0; i<k; ++i)
{
//在循环内部说明还没到k步
if(Fast)
Fast = Fast->next;
//如果还没到k步就已经到头了,说明k太大
else
return nullptr;
}
//慢指针出发
while(Fast)
{
Fast= Fast->next;
Slow = Slow->next;
}
return Slow;
}
};
4. 本题小结
- 使用栈和两遍遍历实际上都是为了获得链表的长度,知道长度就能定位倒数第k个节点的位置了。
- 对于链表的遍历,循环条件一般就用while(pHead)即可,因为大多数情况都是需要对最后一个非空结点进行操作的,所以一般不用while(pHead->next)。
8. JZ76 删除链表中重复的结点
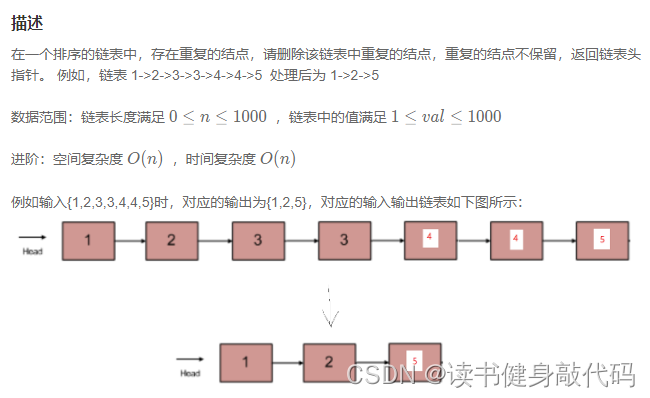
1. 临时头结点遍历法
建立临时头节点,维护一个相同值的变量SameVal,查看下两个结点的值,相等则跳过,并更新SameVal;不等则比较第一个的值跟SameVal是否相等,若不等则插入,若等则跳过,最后处理尾结点,比较尾结点值跟SameVal是否相等,若相等则令现在的尾结点直接指向nullptr,若不等则插入Res。
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};
*/
// 删除重复的结点,不保留
class Solution {
public:
ListNode* deleteDuplication(ListNode* pHead) {
ListNode* Res = new ListNode(-1);
Res->next = nullptr; //虚拟节点指向待删除的链表
ListNode* ResPtr = Res;
int SameVal = -1;
if(pHead==nullptr)
return nullptr;
while(pHead->next)
{
//连续两个相等
if(pHead->val == pHead->next->val)
{
SameVal = pHead->val;
pHead = pHead->next;
}
//不相等
else
{
//连续不同的结点,且不跟之前的sameval相同才行
if(pHead->val!=SameVal)
{
ResPtr->next = pHead;
ResPtr = pHead;
}
pHead = pHead->next;
}
}
//判断最后一个节点的值,如果不同则插入,若相同则将尾结点指空
if(pHead->val != SameVal)
ResPtr->next = pHead;
else
ResPtr->next = nullptr;
return Res->next;
}
};
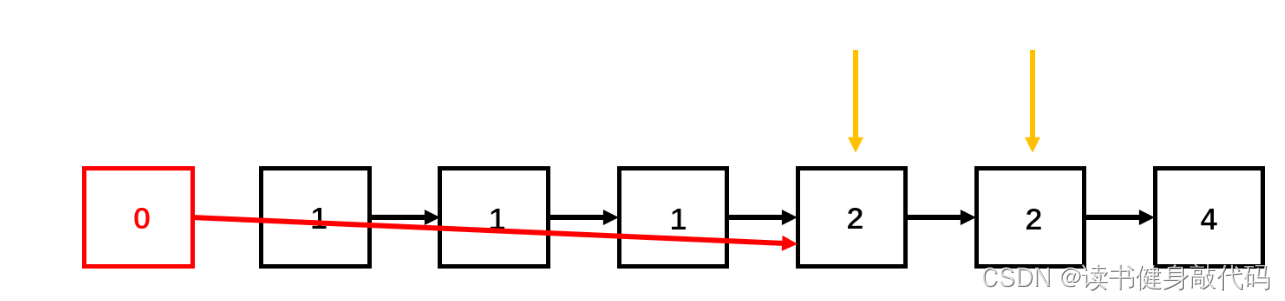
2. 官方解析,对于相等的结点,循环直到不相等为止(推荐)
这里注意
ResPtr->next = ResPtr->next->next;和ResPtr = ResPtr->next;的区别,前者是修改链表的指向,相当于把ResPtr->next 这个结点删掉了,而后者是保留ResPtr->next这个结点,只是后移。
这个看官方的这个动图更好理解。
大概这样:
// 删除重复的结点,不保留
class Solution {
public:
ListNode* deleteDuplication(ListNode* pHead) {
ListNode* Res = new ListNode(-1);
Res->next = pHead; //虚拟节点指向待删除的链表
ListNode* ResPtr = Res;
int SameVal = -1;
if(pHead==nullptr)
return nullptr;
while(ResPtr->next && ResPtr->next->next)
{
//连续两个相等
if(ResPtr->next->val == ResPtr->next->next->val)
{
SameVal = ResPtr->next->val;
//循环直到非相同值的第一个结点
while(ResPtr->next && ResPtr->next->val==SameVal)
ResPtr->next = ResPtr->next->next; //最后一个nullptr在跳出这个while循环时已经处理好了
}
//不相等
else
ResPtr = ResPtr->next;
}
return Res->next;
}
};
3. 本题小结
遍历的时候,停止条件的设立非常关键,要么是while(Ptr)要么是while(Ptr->next)就这两个,这个得做多了,熟悉才行。
无他,熟尔。
9. JZ35 复杂链表的复制
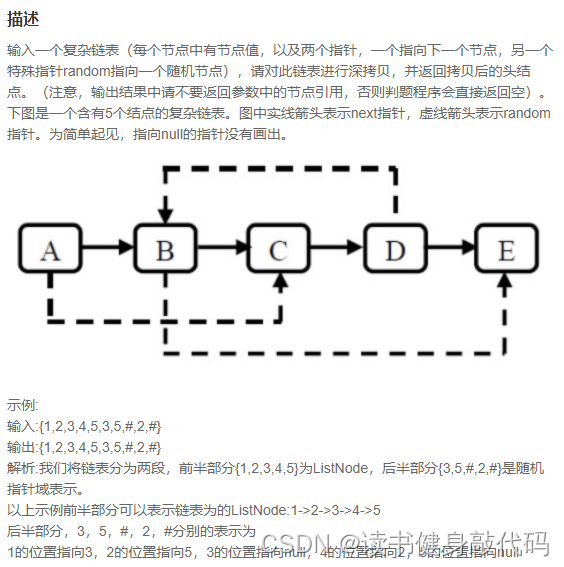
1. 自己使用map
使用两个map来做值->地址的映射。
//遍历原链表的值,每次都new一个新节点,用遍历的值及逆行初始化,然后使用next指针域将普通链表搭建出来,同时
//采用map<int, RandomListNode *>的形式,将val->random存储下来
//在第二遍遍历原链表时,
class Solution {
public:
RandomListNode* Clone(RandomListNode* pHead) {
map<int, RandomListNode *> map1;
map<int, RandomListNode *> map2;
RandomListNode* Res = new RandomListNode(-1);
RandomListNode* CurPtr = Res;
RandomListNode* RawPtr = pHead;
if(pHead==nullptr)
return nullptr;
//第一遍遍历
while(RawPtr)
{
CurPtr->next = new RandomListNode(RawPtr->label);
map1[RawPtr->label] = RawPtr->random; //存入新链表的 值->random 映射
map2[CurPtr->next->label] = CurPtr->next; //存入新链表的 值->next 映射
CurPtr = CurPtr->next;
RawPtr = RawPtr->next;
}
//第二遍遍历新链表
CurPtr = Res->next;
while(CurPtr)
{
RandomListNode* random = map1[CurPtr->label];
// CurPtr->random = random ? map2[random->label] : nullptr; //三目运算更费时间
if(random)
{
CurPtr->random = map2[random->label];
}
else{
CurPtr->random = nullptr;
}
CurPtr = CurPtr->next;
}
return Res->next;
}
};
2. 官方map(推荐)
官方的方法比我的巧妙之处在于建立的是新旧链表之间的映射map<RandomListNode*, RandomListNode*>,只使用了一个map可以完成对于新旧链表的随机访问。
class Solution {
public:
RandomListNode* Clone(RandomListNode* pHead) {
map<RandomListNode *, RandomListNode *> map1;
RandomListNode* Res = new RandomListNode(-1);
RandomListNode* CurPtr = Res;
RandomListNode* RawPtr = pHead;
if(pHead==nullptr)
return nullptr;
//第一遍遍历原链表
while(RawPtr)
{
CurPtr->next = new RandomListNode(RawPtr->label);
map1[RawPtr] = CurPtr->next; //旧->新的
CurPtr = CurPtr->next;
RawPtr = RawPtr->next;
}
//第二遍遍历新链表,因为新旧链表间已经建立了联系,所以访问到旧链表的任何结点,都可以通过map在新链表中访问到
for(auto node:map1)
{
if(node.first->random)
node.second->random = map1[node.first->random];
else
node.second->random = nullptr;
}
return Res->next;
}
};
更简洁的版本,但是这个如果在笔试中估计写不出来,无他,熟尔。
RandomListNode* Clone(RandomListNode* pHead) {
if(!pHead) return nullptr;
RandomListNode* cur = pHead;
unordered_map<RandomListNode*, RandomListNode*> map;
//复制各节点,并建立 “原节点 -> 新节点” 的 Map 映射
while(cur != nullptr) {
map[cur] = new RandomListNode(cur->label);
cur = cur->next;
}
cur = pHead;
//构建新链表的 next 和 random 指向
while(cur != nullptr) {
map[cur]->next = map[cur->next];
map[cur]->random = map[cur->random];
cur = cur->next;
}
//返回新链表的头节点
return map[pHead];
}
3. 本题小结
建立新旧链表的结点映射关系map,通过旧链表来访问新链表,完成深拷贝。















 121
121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









