







 本文介绍了如何利用大型语言模型的简单接口(Complete和Embedding)解决情感分析问题,通过Embedding计算文本向量间的相似度进行分类。传统方法如朴素贝叶斯和逻辑回归在此背景下显得复杂,而大模型提供了一种无需大量特征工程和机器学习经验的高效解决方案。
本文介绍了如何利用大型语言模型的简单接口(Complete和Embedding)解决情感分析问题,通过Embedding计算文本向量间的相似度进行分类。传统方法如朴素贝叶斯和逻辑回归在此背景下显得复杂,而大模型提供了一种无需大量特征工程和机器学习经验的高效解决方案。
上一讲我们看到了,大型语言模型的接口其实非常简单。像 OpenAI 就只提供了 Complete 和 Embedding 两个接口,其中,Complete 可以让模型根据你的输入进行自动续写,Embedding 可以将你输入的文本转化成向量。
不过到这里,你的疑问可能就来了。不是说现在的大语言模型很厉害吗?传统的自然语言处理问题都可以通过大模型解决。可是用这么简单的两个 API,能够完成原来需要通过各种 NLP 技术解决的问题吗?比如情感分析、文本分类、文章聚类、摘要撰写、搜索,这一系列问题怎么通过这两个接口解决呢?
别急,在接下来的几讲里,会告诉你,怎么利用大语言模型提供的这两个简单的 API 来解决传统的自然语言处理问题。这一讲我们就先从一个最常见的自然语言处理问题——“情感分析”开始,来看看我们怎么把大语言模型用起来。
传统的二分类方法:朴素贝叶斯与逻辑回归
“情感分析”问题,是指我们根据一段文字,去判断它的态度是正面的还是负面的。在传统的互联网产品里,经常会被用来分析用户对产品、服务的评价。比如大众点评里面,你对餐馆的评论,在京东买个东西,你对商品的评论,都会被平台拿去分析,给商家或者餐馆的评分做参考。也有些品牌,会专门抓取社交网络里用户对自己产品的评价,来进行情感分析,判断消费者对自己的产品评价是正面还是负面的,并且会根据这些评价来改进自己的产品。
对于“情感分析”类型的问题,传统的解决方案就是把它当成是一个分类问题,也就是先拿一部分评论数据,人工标注一下这些评论是正面还是负面的。如果有个用户说“这家餐馆真好吃”,那么就标注成“正面情感”。如果有个用户说“这个手机质量不好”,那么就把对应的评论标注成负面的。
我们把标注好的数据,喂给一个机器学习模型,训练出一组参数。然后把剩下的没有人工标注过的数据也拿给训练好的模型计算一下。模型就会给你一个分数或者概率,告诉你这一段评论的感情是正面的,还是负面的。
可以用来做情感分析的模型有很多,这些算法背后都是基于某一个数学模型。比如,很多教科书里,就会教你用朴素贝叶斯算法来进行垃圾邮件分类。朴素贝叶斯的模型,就是简单地统计每个单词和好评差评之间的条件概率。一般来说,如果一个词语在差评里出现的概率比好评里高得多,那这个词语所在的评论,就更有可能是一个差评。
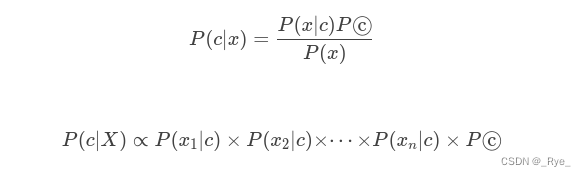
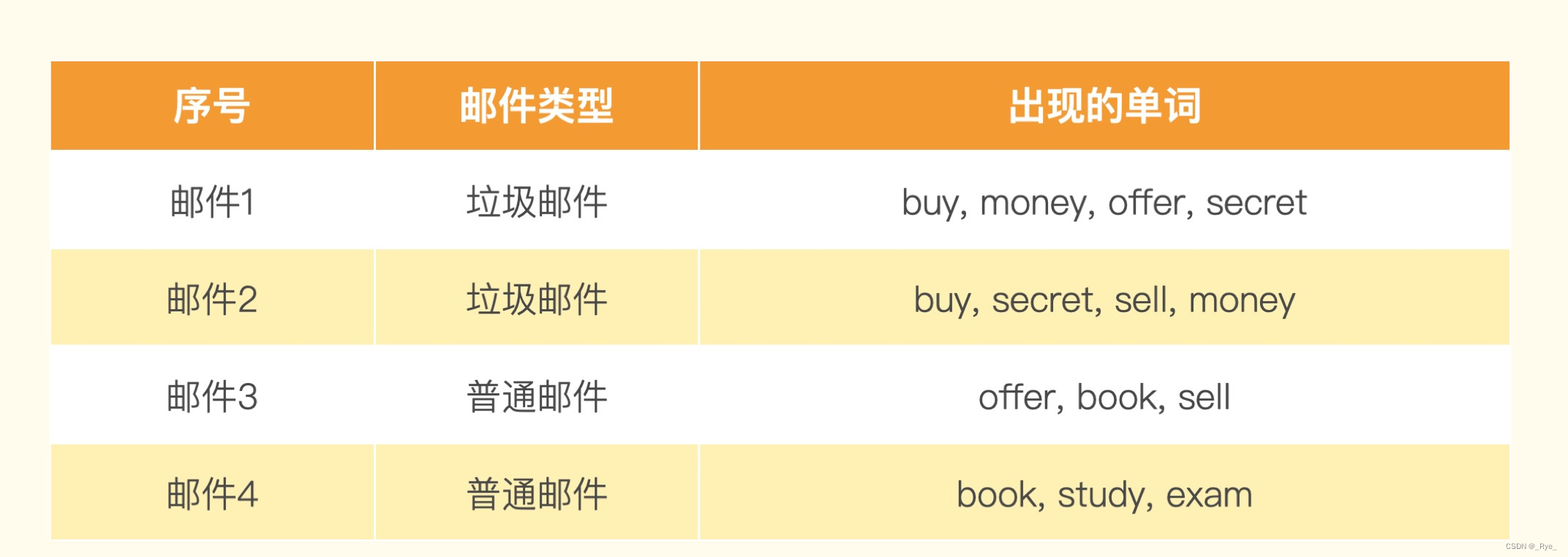
假设我们有一个训练集包含 4 封邮件,其中 2 封是垃圾邮件,2 封是非垃圾邮件。训练集里的邮件包含这些单词。
然后来了一封新邮件,里面的单词是:buy、money、sell。
通过这些单词出现的概率,我们很容易就可以预先算出这封邮件是垃圾邮件还是普通邮件。

然后我们把这封邮件里所有词语的条件概率用全概率公式乘起来,就得到了这封邮件是垃圾邮件还有普通邮件的概率。
P(垃圾∣X)∝P(buy∣垃圾)×P(money∣垃圾)×P(sell∣垃圾)×P(垃圾)=1×1×0.5×0.5=0.25
P(普通∣X)∝P(buy∣普通)×P(money∣普通)×P(sell∣普通)×P(普通)=0×0×0.5×0.5=0
在这里,我们发现 P(垃圾∣X)>P(普通∣X),而且 P(普通∣X) 其实等于 0。那如果用朴素贝叶斯算法,我们就会认为这封邮件 100% 是垃圾邮件。如果你觉得自己数学不太好,这个例子没有看明白也没有关系,因为我们接下来的 AI 应用开发都不需要预先掌握这些数学知识,所以不要有心理负担。
类似的&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









