







在上一讲中我们着重讲了持久层的一致性,其实,它是分布式系统的一个基础理论。你可能会问,学习基于 Web 的全栈技能,也需要学习一些分布式系统的技术吗?是的!特别是我们在学习其持久层的时候,我们还真得学习一些分布式系统的基础理论,从而正确理解和使用我们熟悉的这些持久层技术。
CAP 理论就是分布式系统技术中一个必须要掌握的内容,也是在项目早期和设计阶段实实在在地影响我们技术选型、技术决策的内容。
理解概念
我想,你已经很熟悉一致性了。今天,在一致性之后,我们也要涉及到 CAP 的另外的两个方面——可用性和分区容忍性。
1. CAP 的概念
CAP 理论,又叫做布鲁尔理论(Brewer’s Theorem),指的是在一个共享数据的分布式存储系统中,下面三者最多只能同时保证二者,对这三者简单描述如下:
一致性(Consistency):读操作得到最近一次写入的数据(其实就是上一讲我们讲的强一致性);
可用性(Availability):请求在限定时间内从非失败的节点得到非失败的响应;
分区容忍性(Partition Tolerance):系统允许节点间网络消息的丢失或延迟(出现分区)。
下面,请让我进一步说明,从而帮助理解。
一致性,这里体现了这个存储系统对统一数据提供的读写操作是线性化的。如果客户端写入数据,并且写操作返回成功给客户端,那么在下一次读取的时候(下一次写入以前),如果系统返回了“非失败”的响应,就一定是读出了完整、正确(最新)的那份数据,而不会读取到过期数据,也不会读取到中间数据。
可用性,体现的是存储系统持续提供服务的能力,这里表现在两个方面:
返回“非失败”的响应,就是说,不是光有响应就可以了,系统得是在实实在在地提供服务,而不是在报错;
在限定时间内返回,就是说,这个响应是预期时间内返回的,而不出现请求超时。
请注意,这里说的是“非失败”响应,而并没有说“正确”的响应。也就是说,返回了数据,但可以是过期的,可以是中间数据,因为数据是否“正确”并非由可用性来保证,而是由一致性来保证的。系统的单个节点可能会在任意时间内故障、出错,但是系统总能够靠处于非失败(non-failing)状态的其它节点来继续提供服务,保证可用性。
分区容忍性,体现了系统是否能够接纳基于数据的网络分区。只要出现了网络故障,无论什么原因导致某个节点和系统的其它节点失去了联系,节点间的数据同步操作无法被“及时”完成,那么,即便它依然可以对外(客户端)提供服务,网络分区也已经出现了。
当然,如果数据只有一份,不存在其它节点保存的副本,或不需要跨节点的数据共享,那么,这就不存在“分区”,这样的分布式存储系统也就不是 CAP 关心的对象。
2. 进一步理解
如果你觉得模糊,没关系,使用一个简单的图示来帮你理解。
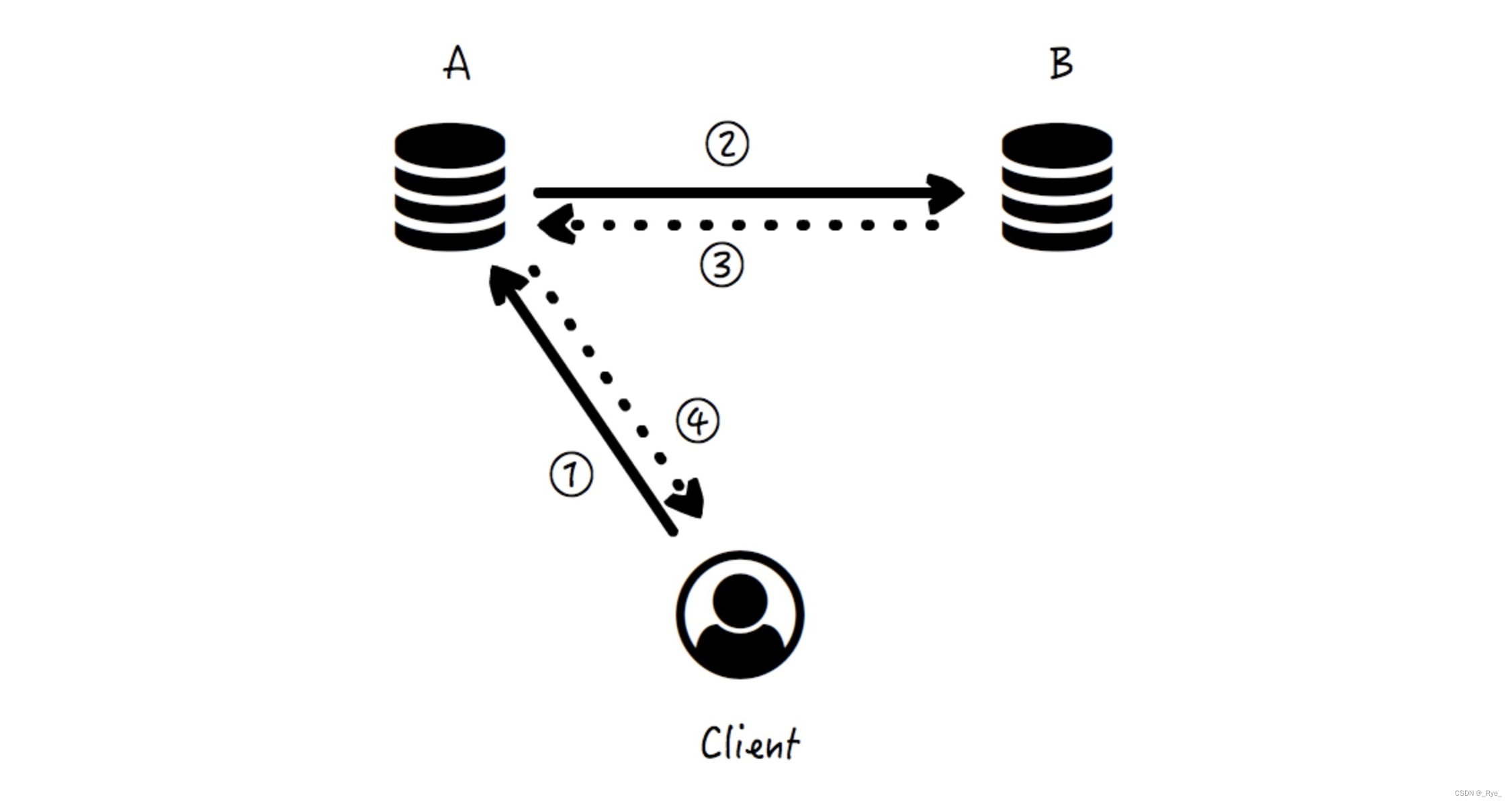
有这样一个存储系统,存在两个节点 A 和 B,各自存放一份数据拷贝。那么在正常情况下,客户端无论写数据到 A 还是 B,都需要将数据同步到另一个节点,再返回成功。比如图示中带序号的四个箭头:
箭头 ①,客户端写数据到节点 A;
箭头 ②,节点 A 同步数据变更到节点 B;
箭头 ③,节点 B 返回成功响应到节点 A;
箭
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









