







 本文回顾了Web全栈技术的学习历程,从网络协议、MVC架构、前端技术到数据持久化,强调了从做项目到做产品的转变和保持技术包容性的重要性。作者鼓励读者持续学习,全栈之路才刚刚开始。
本文回顾了Web全栈技术的学习历程,从网络协议、MVC架构、前端技术到数据持久化,强调了从做项目到做产品的转变和保持技术包容性的重要性。作者鼓励读者持续学习,全栈之路才刚刚开始。
回顾一下,我们学到了什么?
现在,是时候来回顾一下我们学过的 Web 全栈树了。这里按章节进行划分,把每一讲的标题和主要内容做成了一张思维导图,帮助回顾。
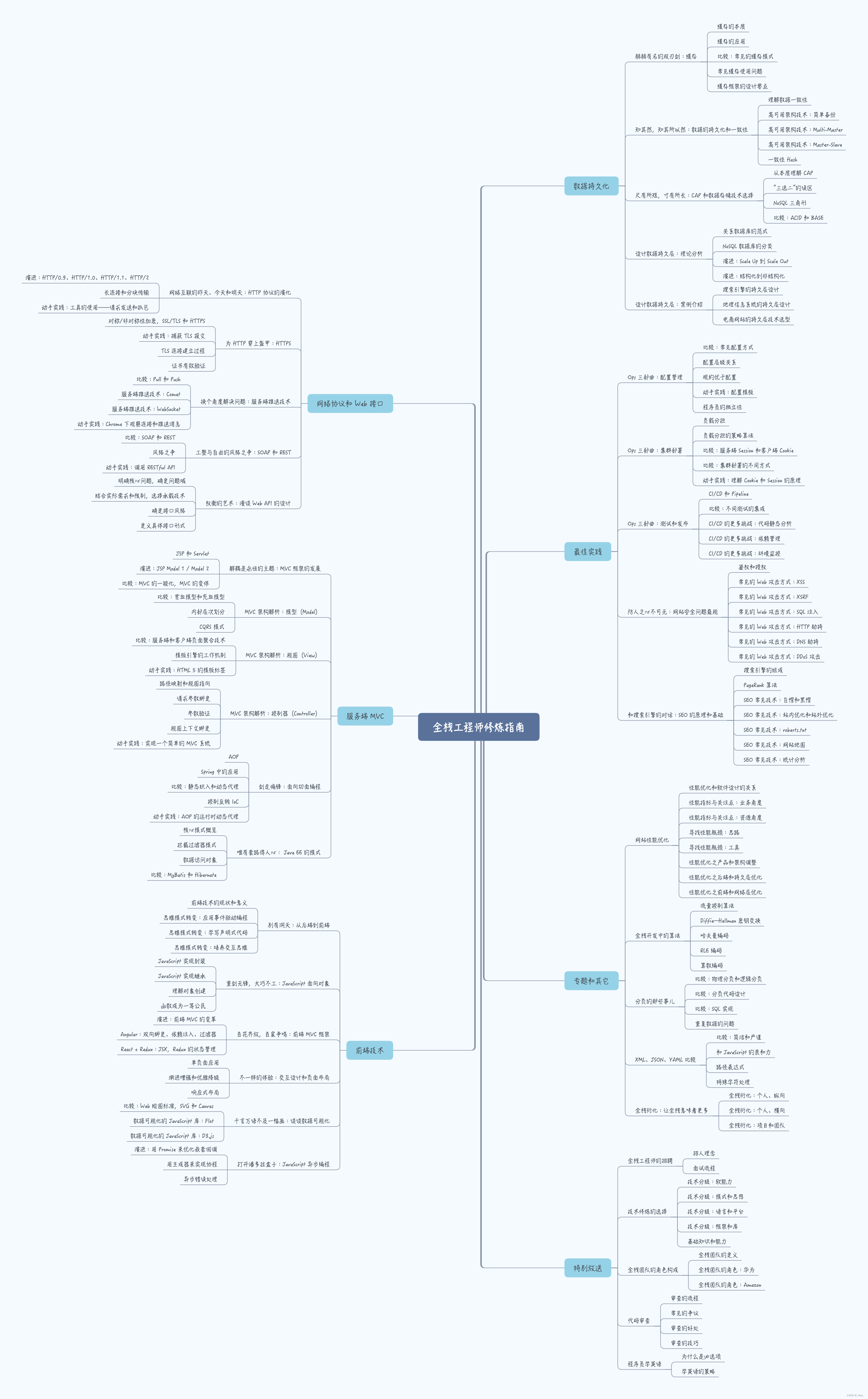
下面把它展开来,你可以顺着这个展开的内容,回顾自己所学。
第一章:网络协议和 Web 接口
第一章是网络协议和 Web 接口,我以 HTTP 为核心,介绍了它的演进历史、相关技术,以及它的局限性:
对于安全传输方面的局限,我介绍了 HTTPS 的原理;
对于交互模式上的局限,介绍了一些服务端推送技术;
对于无状态连接的局限,在第五章我介绍了客户端和服务端的会话。
也是从这一章开始,我们开始接触了 push 和 pull 这两个“对立”的套路,对于整个专栏,我们在各个层面的技术中把它们拿出来反复比较,权衡利弊。
对于 Web 接口部分,从 SOAP 和 REST 所代表的两大设计风格开始,梳理了 Web 接口设计的过程,以及需要考虑的零零总总各个方面。
第二章:欢迎来到 MVC 的世界
第二章主要针对 MVC 这个对于网站和其它 Web 应用开发来说,最重要的架构和设计模式,介绍演进、分层,并逐层仔细深挖:
模型层,介绍了贫血模型和充血模型,以及常见的 CQRS 模式;
视图层,页面聚合是我们的重点,包括客户端聚合和服务端聚合,特别是模板引擎的工作原理;
控制器层,把这一层拆分为几个方面,梳理了控制器在 MVC 架构中的工作步骤。
之后我们将 MVC 泛化,了解了其它重要的设计模式和套路,包括 AOP 和 IoC,以及实现切面编程所需的代理技术;还有其它著名的 JavaEE 模式,特别是拦截过滤器和数据访问对象模式。
第三章:从后端到前端
第三章主要讲前端技术。首先我从一个大体上俯瞰的角度,阐述了我所理解的前端技术的“不同”,特别是思维模式的不同。
然后介绍了一些前端技术重要的知识点,比如 JavaScript 面向对象,包括封装、继承和多态的实现方式,也包括对象创建的原理。接着我以 React 和 Angular,以及它们的重要特性为例,介绍了百花齐放的前端 MVC 框架为我们带来的变革。
在页面设计和交互布局一讲中,我使用实际例子介绍了页面设计方面的一些原则和思路,包括渐进增强和优雅降级等等。
接着在数据可视化一讲中,我仔细比较了当今最重要的两种 Web 绘图标准,SVG 和 Canvas,并介绍了 Flot 和 D3.js 这两个可视化的库。
最后是 JavaScript 异步编程的技术,我们重新回归 JavaScript,梳理了最重要的几个技术要点,这也是这一章相对比较难的一讲。
第四章:数据持久化
继续往技术栈的下方挖,数据持久化。在这一章的一开始,首先介绍了这一层中互联网应用最广泛的技术之一——缓存,讲了它的本质、应用和常见的坑,以及缓存框架的设计要点。
接着是数据一致性,我介绍了它的概念,还有围绕它而产生的常见架构技术。有了数据一致性的基础知识,我们就进一步学习了 CAP 的原理,包括它的本质、常见的误区,以及我们该怎样根据 CAP 去做技术选型。
最后则是数据持久层的设计,包括理论部分、关系数据库和非关系数据库的一些设计要点;以及实例部分,包括几个范例系统:搜索引擎、地理信息系统和电商网站。
第五章:寻找最佳实践
在第五章中,我们跳出了全栈技术纵深方向上具体某一层的限制,而是从一个横向的角度去分析相关的实践技术。
在 Ops 三部曲中,分别介绍了:
配置管理,有哪些配置管理的技术,我们该选择怎样的方式去做配置管理;
集群部署,我介绍了集群部署的方式,部署下的负载分担原理和策略算法,以及集群部署下常见的话题——Session 和 Cookie;
测试和发布,围绕 CI/CD 介绍了 pipeline 的含义、内容和挑战,以及不同类型的测试在其上集成的方式。
在网络安全那一讲中,我着重介绍了常见的 Web 攻击方式的原理,包括 XSS、CSRF、SQL 注入、HTTP 和 DNS 劫持,以及 DDoS。
最后则是 SEO 这一讲,我介绍了 SEO 和白帽、黑帽的含义,以及一些常见的 SEO 技术,包括站内优化和站外优化。
第六章:专题
在第六章,选取了四大专题分别展开介绍。
在网站性能优化一讲,首先介绍了一些基础知识,包括性能优化和软件设计的关系,性能优化的关注点,性能测试和指标,以及寻找性能瓶颈的思路;接着按照产品架构调整、后端和持久层优化,以及前端和网络层优化这样三个部分,分别介绍相应的常见性能优化技术。
在全栈开发中的算法这一讲,以这样几大场景为主线,介绍了一些重要的算法:
流量控制算法,包括基于固定时间窗口和滑动时间窗口的流量控制,漏桶算法和令牌桶算法;
Diffie–Hellman 密钥交换算法,从中我们学到了数学上超大质数在安全领域的一个典型应用;
数据压缩算法,包括哈夫曼编码、RLE 编码和算术编码,从而帮助我们理解,如今繁多的压缩技术的最基本的原理。
在分页这一讲中,我讲了分页的分类和几种实现分页的技术,最后则是分页的常见问题——重复数据,它背后可能的原因和相应的解决方案。
在最后的 XML、JSON 和 YAML 这一讲,我把这几个数据承载格式的优劣进行了仔细的比较,包括简洁和严谨的程度,与 JavaScript 的亲和力,schema、转义方式和路径表达式等等。
其它
以上是技术方面的“硬通货”,对于非技术方面,通过特别放送等等的形式,讨论了一些我认为比较重要,尤其是对于 Web 全栈工程师来说比较重要的话题。
怎样去理解 Web 全栈技术,全栈技术应该怎样学习,需要遵从怎样的学习策略;
北美全栈工程师的招聘,招人会秉持怎样的理念,整个流程是怎样的;
技术修炼应该怎样进行取舍和选择,哪些技术应该深挖,哪些则可以点到即止;
全栈团队的构成一般是怎样的,有哪些重要的角色;
代码审查为什么不可或缺,有哪些争议和好处,又有哪些技巧;
程序员为什么要学英语,重要性在哪里,又有哪些好办法;
作为 Web 全栈工程师,我们还有哪些发展方向可以考虑,我们为什么需要让项目和团队也“全栈化”?
继续提升的重要两步
对于我们专栏已经覆盖到的这些技能树的枝枝丫丫,我还想特别强调两个方面,这两个方面其实我们已经谈到过了,但是我觉得在今天,我们需要再拿出来稍稍强化一下。因为在我看来,它们有些特殊——它们对于程序员进一步发展至关重要,它们也是“成为更好的全栈工程师”所必须迈出的两步,但是谈论的人却很少。
1. 从做项目到做产品
你还记得吗? [第 28 讲] 的选修课堂,我介绍了程序员独立性的几个阶段,不知道你属于哪一个阶段呢?作为职业生涯进阶的一部分,如果你还停留在“做项目”的阶段,那么你需要在某一天切换到“做产品”的模式上来,完成程序员独立性的升级。事实上,“做项目”,终归只是“做产品”整个过程中很小的一部分,只有对于产品多个阶段的不断地迭代、回馈,程序员很多方面的认识才能不断进化。
举个例子,对于程序员来说,oncall(定位和修复线上问题)就是“做产品”必经的一环,也是团队“吃自己的狗食”的重要一环。这个过程可以反哺开发阶段,没有这样的过程,就不会真正体会到代码质量的重要性,就不会彻底意识到单元测试的重要性,也不会对代码评审的必要性有深刻的认识。因此,如果你还只有“做项目”的经验,我建议你,在未来给自己寻找做产品的机会。
2. 保持技术上的包容心
在 [第 14 讲] 我就谈到过这个给自己“贴标签”的问题,有些程序员工作没几年,无论是有意识还是无意识地,就已经给自己贴上了过于明确的技术分类的标签。
比如说,给自己贴上“PHP 工程师”的标签,理由是觉得 PHP 是最好的语言,因此求职的时候非 PHP 的岗位一概不考虑;比如,只想做 Billing 系统,其它的业务领域和项目一概不考虑;再比如,极度强调自己是“技术人”,而特别排斥管理技巧、沟通合作能力等这些被鄙视为“非干货”、“非实战”的内容,可是对于几乎所有的职业生涯技术路线来说,它们其实都是非常重要,且绕不开的槛。
再说说具体的技术,每个人都有偏好,但是不要因为自己的偏好,在技术的选择上失去程序员应有的理性判断,甚至将应当去接纳和学习的技术拒之门外。因为你也不知道哪一天,一个新领域、一门新技术会像浪潮一样涌来,就像几年前的云计算,这两年的区块链。只有那些有着包容心的程序员,才能去接纳和抓住机会。这也正如我在 [开篇词] 中所说的,最终也许我们需要“学得精”,但是一开始我们一定要“学得杂”。
送君千里,终须一别
任何一段旅程都有终点,这个专栏也不例外。
全栈,不只是一种技术分类,还代表了一种态度:理性、包容、好学。希望你可以从这个专栏得到你想要的,但更多的收获,需要你在线下继续努力。毕竟,《全栈工程师修炼指南》这个专栏结束了,而你的全栈之路却才刚刚开始。

















 814
814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









