







今天要与你分享的主题是“怎样实现大型电商热销榜”。
在 Google 面试过很多优秀的候选人,应对普通的编程问题 coding 能力很强,算法数据结构也应用得不错。
可是当我追问数据规模变大时该怎么设计系统,他们却说不出所以然来。这说明他们缺乏必备的规模增长的技术思维(mindset of scaling)。这会限制这些候选人的职业成长。
因为产品从 1 万用户到 1 亿用户,技术团队从 10 个人到 1000 个人,你的技术规模和数据规模都会完全不一样。
今天我们就以大型电商热销榜为例,来谈一谈从 1 万用户到 1 亿用户,从 GB 数据到 PB 数据系统,技术思维需要怎样的转型升级?
同样的问题举一反三,可以应用在淘宝热卖,App 排行榜,抖音热门,甚至是胡润百富榜,因为实际上他们背后都应用了相似的大规模数据处理技术。
真正的排序系统非常复杂,仅仅是用来排序的特征(features)就需要多年的迭代设计。
为了便于这一讲的讨论,我们来构想一个简化的玩具问题,来帮助你理解。
假设你的电商网站销售 10 亿件商品,已经跟踪了网站的销售记录:商品 id 和购买时间 {product_id, timestamp},整个交易记录是 1000 亿行数据,TB 级。作为技术负责人,你会怎样设计一个系统,根据销售记录统计去年销量前 10 的商品呢?
举个例子,假设我们的数据是:
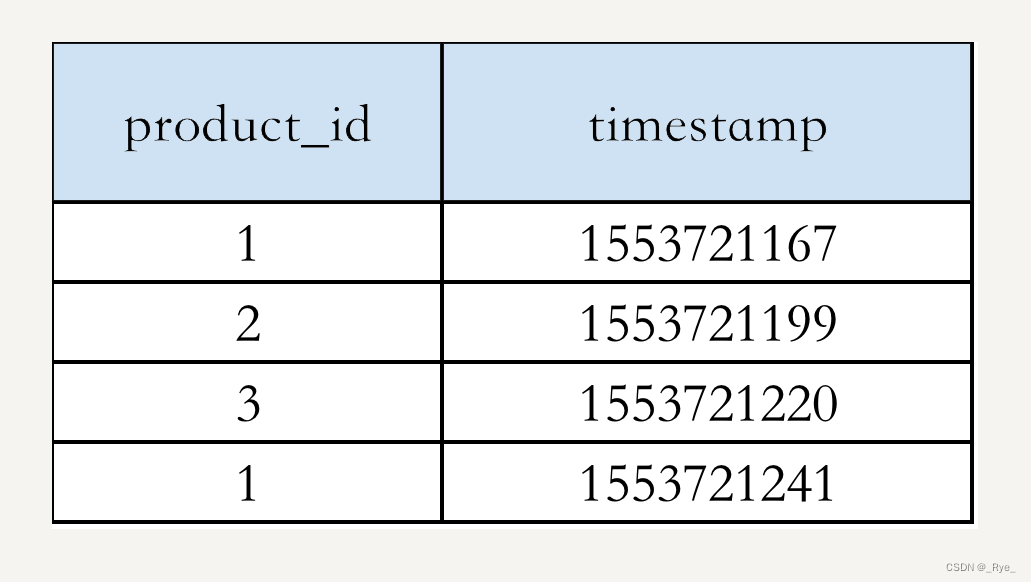
我们可以把热销榜按 product_id 排名为:1, 2, 3。
小规模的经典算法
如果上过数据结构与算法之美,你可能一眼就看出来,这个问题的解法分为两步:
第一步,统计每个商品的销量。你可以用哈希表(hashtable)数据结构来解决,是一个 O(n) 的算法,这里 n 是 1000 亿。
第二步,找出销量前十
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









