









一、Tree-CNN:一招解决深度学习中的「灾难性遗忘」
深度学习领域一直存在一个比较严重的问题——“灾难性遗忘”,即一旦使用新的数据集去训练已有的模型,该模型将会失去对原数据集识别的能力【1】。
为解决这一问题,本文提出了树卷积神经网络,通过先将物体分为几个大类,然后再将各个大类依次进行划分、识别,就像树一样不断地开枝散叶,最终叶节点得到的类别就是我们所要识别的类。
■ 论文 | Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning
■ 链接 | https://www.paperweekly.site/papers/1839
1、网络结构
Tree-CNN模型借鉴了层分类器,树卷积神经网络由节点构成,和数据结构中的树一样,每个节点都有自己的ID、父亲(Parent)及孩子(Children),网(Net,处理图像的卷积神经网络),LT("Labels Transform"小编理解的就是每个节点所对应的标签,对于根节点和枝节点来说,可以是对最终分类类别的一种划分,对于叶节点来说,就是最终的分类类别。),其中最顶部为树的根节点。如图1所示,对于一张图像,首先会将其送到根节点网络去分类得到“super-classes”,然后根据所识别到的“super-classes”,然后根据根分类器得到的类别将图像送入对应的节点去作进一步的分类,得到一个更“具体”的类别,依次进行递归,知道分类出我们最终想要的类。其实小编感觉这就和人的识别过程相似,例如有下面一堆物品:数学书、语文书、物理书、橡皮、铅笔。如果要识别物理书,我们可能要经历这样的过程,先在这一堆中找到书,然后可能还要在书里面找到理科类的书,然后再从理科类的书中找到物理书,同样我们要找铅笔的话,我们可能需要先找到文具类的物品,然后再从中找到铅笔。如图1所示。
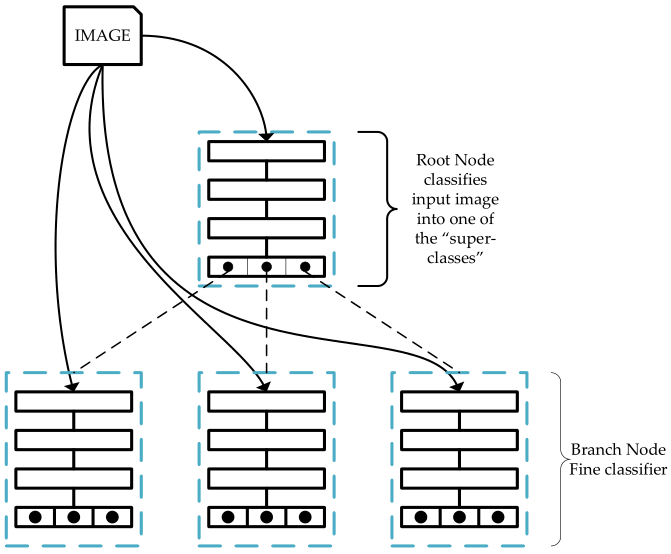
图 1
2、学习策略
(1)、在识别方面,Tree-CNN的思想基于很简单啦。如图1,主要就是从根节点出发,输出得到一个图像属于各个大类的概率,根据最大概率所对应的位置将识别过程转移到下一节点,这样最终我们能够到达叶节点,叶节点对应得到的就是我们要识别的结果啦。整个过程如图2所示。

图 2
(2)、要说按照上面的思路去做识别,其实并没有什么太大的意义,不仅使识别变得很麻烦,而且在下面的实验中也证明了采用该方法所得到的识别率并不会有所提高,那么这篇论文的意义在哪呢?对,这篇论文最主要的目的就是要解决咱们在前面提到的“灾难性遗忘问题”,即文中所说的达到“lifelong”的效果。
---------------------
版权声明:本文为CSDN博主「看_这是一群菜鸟」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_24305433/article/details/79856672
二、HD-CNN(深层卷积)
■ 论文 | Hierarchical Deep Convolutional Neural Networks for Large Scale Visual Recognition
■ 链接 | https://arxiv.org/abs/1410.0736
本文主要基于在分类问题中,并不是所有类别的区分程度都是相同的的观点,对于分类器而言,有些类别是比较难以区分的。基于上面的原理,作者提出了一种先进行粗分类,然后再进行细分类的方法,网络的架构如下【2】:
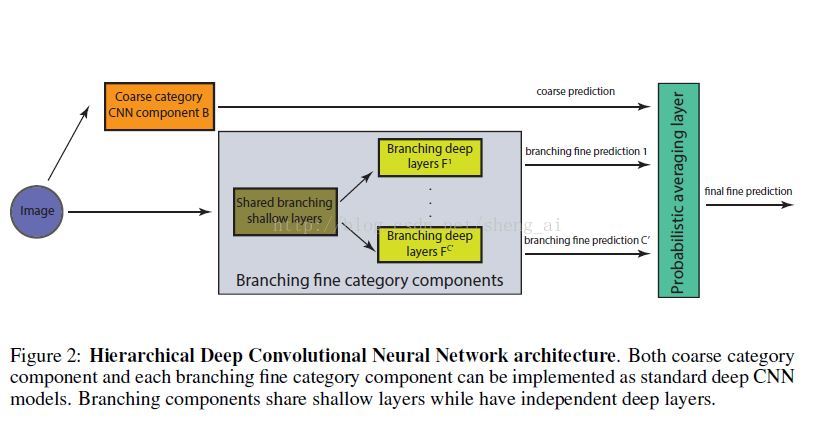
前面的过程都是普通的卷积过程,在最后的Probabilistic averageing layer,对所有的分支fine-category使用coarse category得到的结果进行组合,组合方法如下: 
在最后进行整个结构fine-tuning的时候,最后还引入一个称为“temporal sparsity”的约束项,添加了约束项之后,cost function定义如下:
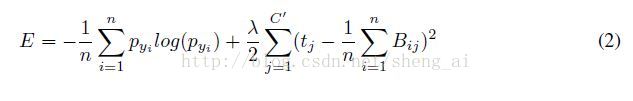

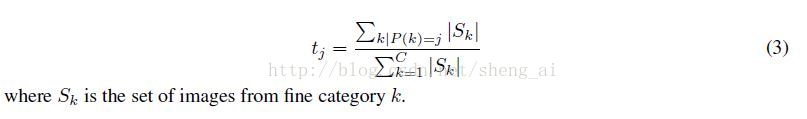
训练过程如下:
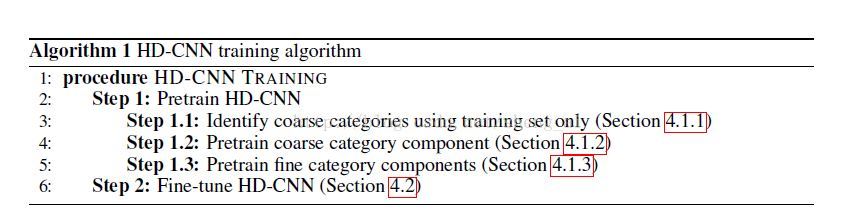
实验结果
作者使用的数据集为CIFAR-100数据集,获得了state-of-the-art的效果。
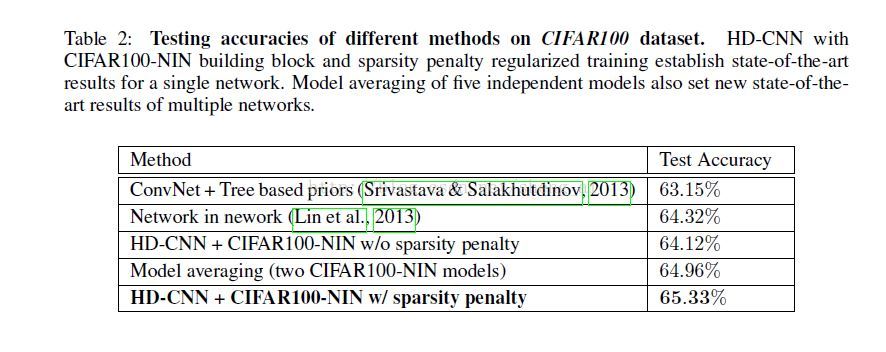
这种通过粗分类然后进行细分类的想法其实挺容易想到的,但是,如何划分粗类别、如何增加细类别的正确率以及如何整合细类别分类器得到的结果,这些都是比较难的地方,作者对于上面的问题都给出了自己的解决方法。对于划分粗类别的问题,作者根据CNN得到的特征进行了降维,然后使用聚类算法进行聚类,从而得到了粗类别;对于增加细类别的正确率,作者采用使用想要增加的类别的样本对原始的CNN后面的卷积层和全连接层进行了再训练;对于细类别结果整合问题,作者使用一个Probabilistic averageing layer将细类别结果使用粗分类得到的概率进行了整合。这些想法都比较实用,可以在以后的实验中进行使用。
---------------------
作者:shengno1
原文:https://blog.csdn.net/sheng_ai/article/details/43313971
三、细粒度图像识别
细粒度图像识别(fine-grained image recognition),即 精细化分类

精细化分类
识别出物体的大类别(比如:计算机、手机、水杯等)较易,但如果进一步去判断更为精细化的物体分类名称,则难度极大。
细粒度图像识别是现在图像分类中一个难点,它的目标是在一个大类中识别子类,同一大类别下 不同子类别间的视觉差异极小。比如说在鸟的大类下识别鸟的种类,在车的大类下,识别车的型号。由于相同的子类中物体的动作姿态可能大不相同,不同的子类中物体可能又有着相同的动作姿态,这是识别的一大难点。不止对计算机,对普通人来说,细粒度图像识别的难度和挑战也很巨大。
细粒度图像分类的关键点在寻找一些存在细微差别的局部区域(比如鸟类的喙、眼睛、爪子等),因此,精细化分类 所需的图像分辨率 较高。同时,现有的细粒度图像识别算法不但寻找图像中的整个物体(object),还寻找一些有区别的局部(part)。
细粒度图像主要分为两类【3】:
1. 基于强监督信息的细粒度图像分类模型
所谓“强监督细粒度图像分类模型”是指:在模型训练时,为了获得更好的分类精度,除了图像的类别标签外,还使用了物体标注框(Object Bounding Box)和部位标注点(PartAnnotation)等额外的人工标注信息,如下图所示。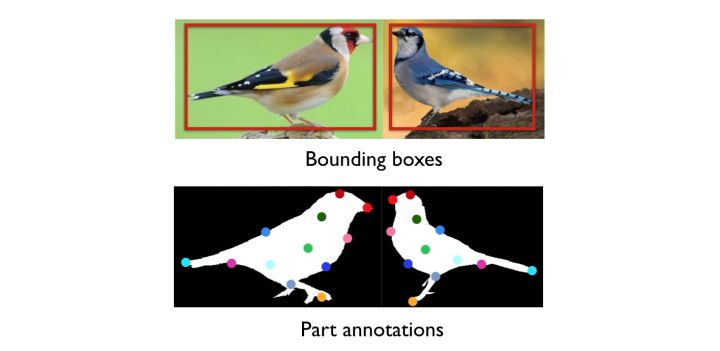
几个经典模型:
Part-based R-CNN
Pose Normalized CNN
Mask-CNN
Mask-CNN中,借助FCN学习一个部位分割模型(part-based segmentation model)。一个图像分为三部分,其中,一部分为头部,一部分为躯干,最后一部分则是背景。
FCN训练完毕后,可以对测试集中的细粒度图像进行较精确地part定位。
将头部,躯干,整个个体输入Mask-CNN模型,即可得到最终的分类

RA-CNN【4】
MSRA通过观察发现,对于精细化物体分类问题,其实形态、轮廓特征显得不那么重要,而细节纹理特征则起到了主导作用。因此提出了 “将判别力区域的定位和精细化特征的学习联合进行优化” 的构想,从而让两者在学习的过程中相互强化,也由此诞生了 “Recurrent Attention Convolutional Neural Network”(RA-CNN,基于递归注意力模型的卷积神经网络)网络结构。

RA-CNN 网络可以更精准地找到图像中有判别力的子区域,然后采用高分辨率、精细化特征描述这些区域,进而大大提高精细化物体分类的精度:

---------------------
版权声明:本文为CSDN博主「JNingWei」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/JNingWei/article/details/79241193
2.基于弱监督信息的分类模型
思路同强监督分类模型类似,也需要借助全局和局部信息来做细粒度级别的分类。而区别在于,弱监督细粒度分类希望在不借助part annotation的情况下,也可以做到较好的局部信息的捕捉。当然,在分类精度方面,目前最好的弱监督分类模型仍与最好的强监督分类模型存在差距(分类准确度相差约1~2%)。
三个弱监督细粒度图像分类模型的代表。
Two Level Attention Model
Constellations
Bilinear CNN
四、YOLO9000: Better,Faster,Stronger
原文下载:https://arxiv.org/pdf/1612.08242v1.pdf
工程代码:http://pjreddie.com/darknet/yolo/
摘要【5】
- 提出YOLO v2 :代表着目前业界最先进物体检测的水平,它的速度要快过其他检测系统(FasterR-CNN,ResNet,SSD),使用者可以在它的速度与精确度之间进行权衡。
- 提出YOLO9000 :这一网络结构可以实时地检测超过9000种物体分类,这归功于它使用了WordTree,通过WordTree来混合检测数据集与识别数据集之中的数据。
- 提出了一种新的联合训练算法( Joint Training Algorithm ),使用这种联合训练技术同时在ImageNet和COCO数据集上进行训练。YOLO9000进一步缩小了监测数据集与识别数据集之间的代沟。
简介
目前的检测数据集(Detection Datasets)有很多限制,分类标签的信息太少,图片的数量小于分类数据集(Classification Datasets),而且检测数据集的成本太高,使其无法当作分类数据集进行使用。而现在的分类数据集却有着大量的图片和十分丰富分类信息。
文章提出了一种新的训练方法–联合训练算法。这种算法可以把这两种的数据集混合到一起。使用一种分层的观点对物体进行分类,用巨量的分类数据集数据来扩充检测数据集,从而把两种不同的数据集混合起来。
联合训练算法的基本思路就是:同时在检测数据集和分类数据集上训练物体检测器(Object Detectors ),用监测数据集的数据学习物体的准确位置,用分类数据集的数据来增加分类的类别量、提升健壮性。
YOLO9000就是使用联合训练算法训练出来的,他拥有9000类的分类信息,这些分类信息学习自ImageNet分类数据集,而物体位置检测则学习自COCO检测数据集。
All of our code and pre-trained models are available online at http://pjreddie.com/yolo9000/
---------------------
版权声明:本文为CSDN博主「Joe_quan」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hysteric314/article/details/53909408
【2】HD-CNN: HIERARCHICAL DEEP CONVOLUTIONAL NEURAL NETWORK FOR IMAGE CLASSIFICATION(泛读)
【3】细粒度图像识别初步学习

















 3032
3032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









