







Hierarchy-Aware Global Model for Hierarchical Text Classification
1、背景
1、作者(第一作者和通讯作者)
Zhou Jie, Liu Gongshen
2、单位
Shanghai Jiao Tong University
3、年份
2020
4、来源
ACL会议
2、四个问题
1、要解决什么问题?
层次化文本分类是具有分类层次的多标签文本分类的重要组成部分,也是一个具有挑战性的子任务。现有方法难以在全局视图中对分层标签结构进行建模。此外,它们不能充分利用文本特征空间和标签空间之间的相互作用。
2、用了什么方法解决?
提出了一种端到端的层次化全局模型(HiAGM)。该模型有两个变体。一种多标签注意变体(HiAGM-LA)通过分层编码器学习层次感知标签嵌入,并对标签文本特征进行归纳融合。提出了一种文本特征传播模型(HiAGM-TP),作为将文本特征直接馈入层次编码器的演绎变体。
3、效果如何?
在三个基准数据集上都取得了显著且一致的改进。
4、还存在什么问题?
论文笔记
1、INTRODUCTION
层次文本分类(HTC)是一种特殊的多标签文本分类(MLC)问题,其中分类结果对应于分类层次中的一个或多个节点。分类层次结构通常建模为树或有向无环图。如下图所示:HTC可能是单路径或多路径问题。
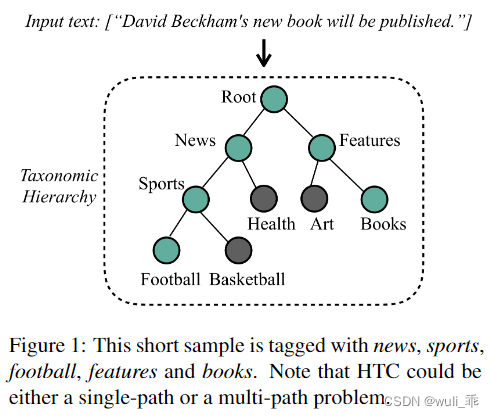
现有的HTC有两种方法:(1)局部:倾向于构建多种分类模型,然后采用自顶向下的遍历方式。之前的局部方式提出通过向父节点学习来克服子节点上的数据不平衡。(2)全局:HTC问题视为平面MLC问题,并对所有类使用一个单独的分类器。
在本文中,作者将层次表示为有向图,并利用标签依赖的先验概率来聚集节点信息。提出了一种层次感知全局模型(HiAGM),利用标签结构特征增强文本信息。包括用于提取文本信息的传统文本编码器和用于建模层次标签关系的层次感知结构编码器。分层感知结构编码器可以是树形结构模型,也可以是集成了分层先验知识的分层GCN模型。此外,这两个结构编码器是双向计算的,允许它们以自上而下和自下而上的方式捕获标签相关信息。因此,HiAGM比以前的自上而下模型更健壮,并且能够减轻由暴露偏差和不平衡数据引起的问题。
为了聚合文本特征和标注结构特征,作者提出了HiAGM的两种变体:多标签注意力模型HiAGM-LA和文本特征传播模型HiAGM-TP。这两种变体都基于结构编码器提取层次感知的文本特征。
HiAGM-LA提取归纳标签文本特征,具体来说,HiAGM-LA更新整个层次中嵌入的标签,然后使用节点输出作为层次感知的标签表示。最后,对标签感知的文本特征进行多标签注意。
**HiAGM-TP直接利用文本特征作为串行数据流中结构编码器的输入。**因此,它在整个层次结构中传播文本信息。整个层次结构中每个节点的隐藏状态表示特定于类的文本信息。
2 Related Work
分类层次主要包括树状结构和有向无环图结构,有向无环图结构可以被简化为树状结构。因此,分类层次可以简化为树状结构。

图2:分类层次结构的示例。该数字指示根据训练语料库的标签依赖关系的先验概率。
3 Problem Definition
如图2所示,我们将分类层次结构表示为有向图,将有向图G作为分类层次。
G = ( V , E → , E ← ) G = (V , \overrightarrow{E}, \overleftarrow{E} ) G=(V,E,E),其中V = {v1, v2,…,vC}为标签节点集合,C为节点总数量。
E
→
\overrightarrow{E}
E = {(vi,vj) | i ∈ V, j ∈ child(i)} 代表父类到子类的一个路径。
E
←
\overleftarrow{E}
E = {(vj,vi) | i ∈ V, j ∈ child(i)} 代表子类到父类的一个路径。
则HTC可以定义为:
H = ( X , L ) H = (X, L) H=(X,L) 其中 X = {x1, x2,…,xN} 为输入的文本组成的集合,L = {l1, l2,…,lN} 为样本对应的标签集合。对于xi样本来说,预测它的所属标签li就是一个层级性的多标签分类任务。
4 Hierarchy-Aware Global Model
下图为论文的整体框架,可分三部分来看:左边部分是文本的encoder,中间是对应两种不同的decoder方法,右边部分是中间模块中的Structure Encoder展开的详细图。
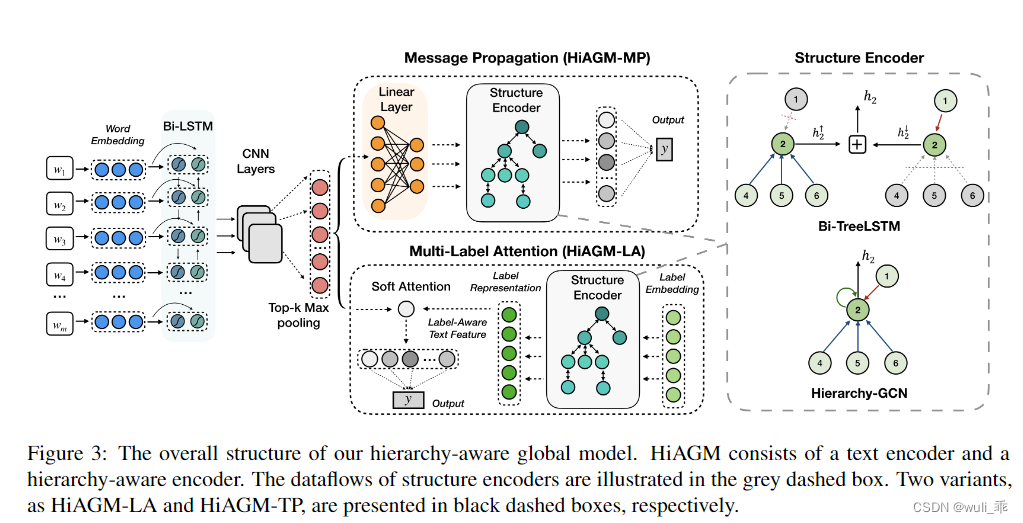
所以作者在大体框架下提出两种不同解决方案,一种称为Message Propagation(HiAGM-MP),一种称为Multi-Label Attention(HiAGM-LA)。两种方案的差别在对于处理label体系(L)信息上,前者将文本表征的向量接个全连接层后,参与L的Structure Encoder的计算,然后进行预测;而后者是将文本表征成的向量,和L表征的向量加一个soft attention进行融合,然后进行预测。简单来说:HiAGM-MP方法将文本的特征作为一个输入,参与L的特征表征;HiAGM-LA是将文本与label各自独立表征后,进行attention方式交互来预测。
4.1 Prior Hierarchy Information
分类层次描述了层级的关系,主要瓶颈就是如何充分利用这种结构。HiGAM把这种关系用概率来表示。
假设在父节点Vi与子节点Vj之间有一个层级路径ei,j,边缘特征f(ei,j)通过P(Uj | Ui) 和 P(Ui | Uj)表示:

Uk是vk的存在并且P(Uj | Ui)是Vi出现的Vj的条件概率。Nk是Uk在训练集中出现的数量。
4.2 Hierarchy-Aware Structure Encoder
论文中提出了两个label体系的编码方式,一个为Bi-TreeLSTM,一个为Hierarchy-GCN。在讲述两种编码方式之前,作者引入了先验层级信息的概念(Prior Hierarchy Information),思想很简洁,图2和4.1中的公式可以看出:label节点之间传递转成概率问题,父类到各个子类传递的概率之和为1,子类到父类传递概率为1,前者可在训练数据集中使用统计得到。
利用先验层级信息,加入label体系的编码中,作者认为这样可以区别之前静态的学习方式,利用数据集中存在的先验信息,能更好地学习label之间的层级关系。在这点上,论文也有对应的实验来验证。
Bidirectional Tree-LSTM
Tree-LSTM是使用LSTM结构来对Tree结构数据进行编码,在此基础上,作者引入双向的Tree-LSTM进行label体系的encoder,因为这对应着上面提到的父类到子类,子类到父类两个方向。下面为一个节点的编码公式:

h k b i h_k^{bi} hkbi为label节点k最终编码向量, h k ↑ {h}^\uparrow_k hk↑和 h k ↓ {h}^\downarrow_k hk↓分别代表k节点到父类,子类的编码向量。依据上面的先验层级信息, f p ( e k , j ) f_p(e_{k,j}) fp(ek,j) = 1, f c ( e k , p ) f_c(e_{k,p}) fc(ek,p) = N p / N k N_p/N_k Np/Nk 。
h k ↑ = T r e e L S T M ( h ~ k ↑ ) {h}^\uparrow_k = TreeLSTM(\widetilde{h}^\uparrow_k) hk↑=TreeLSTM(h k↑), h k ↓ = T r e e L S T M ( h ~ k ↓ ) {h}^\downarrow_k = TreeLSTM(\widetilde{h}^\downarrow_k) hk↓=TreeLSTM(h k↓)
TreeLSTM计算公式如下:

Hierarchy-GCN
在使用GCN进行label体系编码时,对于k节点来说,是基于它的临近节点进行GCN计算,所以:

其中 d ( j , k ) d(j,k) d(j,k)为节点到k的路径,包括父到子,子到父,自己到自己三个方向。 a k , j a_{k,j} ak,j对应节点的信息,若 d j , k d_{j,k} dj,k为父到子: a k , j = N k / N j a_{k,j} = N_k/N_j ak,j=Nk/Nj;若 d j , k d_{j,k} dj,k为子到父: a k , j = 1 a_{k,j} = 1 ak,j=1;若 d j , k d_{j,k} dj,k为自己到自己: a k , j = 1 a_{k,j} = 1 ak,j=1。学习到的 h k h_k hk为节点的最终表征向量。
4.3 Hybrid Information Aggregation
以前的全局模型根据原始文本信息对标签进行分类,并通过预定义的层次路径来改进解码器。相比之下,我们构建了一个新颖的端到端层次感知全局模型,用于文本特征和标签相关性的相互作用。
给出一个文档 x = (w1,w2,…,wS), 首先将嵌入序列送入bi-GRU网络中获取文本特征。然后,多种CNN被用来产生n-gram特征。n-gram特征的连接由top-k 最大池层过滤以提取关键信息。最后我们可以得到一个文本表示S = (s1,…,sn)。
Hierarchy-Aware Multi-Label Attention
在HiGAM-LA方案中,使用soft-attention方式将学习的文本向量S与标签体系向量h进行交互计算,将结果向量V参与最后的label预测。

计算的思路是:将文本每个N-gram特征与label进行一个权重计算,认为N-gram特征对不同的label影响程度是不同的。
Hierarchical text feature propagation
在HiAGM-MP方案中,作者是将文本的表征向量S进行一个全连接,转成V向量, V = M S V = MS V=MS,作为Structure Encoder的初值参与计算,将更新后的向量V参与最后label的预测。
5 Experiment
5.1 Experiment Setup
论文选择了RCV1,WOS,NYT三个公开数据集进行测试,数据集的统计结果如下所示:

实验的主要结果如下所示,论文主要对比了TextRNN、TextCNN、TextRNN以及自己的两种方案的变体,从结果显示HiAGM-TP方法表现的更好些,在label体系编码中,GCN的编码效果更好些。

本文参考:https://zhuanlan.zhihu.com/p/339471554
https://blog.csdn.net/mars_ch/article/details/114715189?spm=1001.2014.3001.5502














 765
765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









