







我们上一节有看到说,如果你选择不同的function set 你就选择不同的model ,你在testing data上也会得到不同的error。而且越复杂的model不见得会给你越低的error。
本节讨论的问题,这些error来自什么地方?
error 有两个来源:
一个是来自bias
一个是来自于variance。
如果你可以诊断你的error来源,你就可以挑选适当的方法来improve你的model。
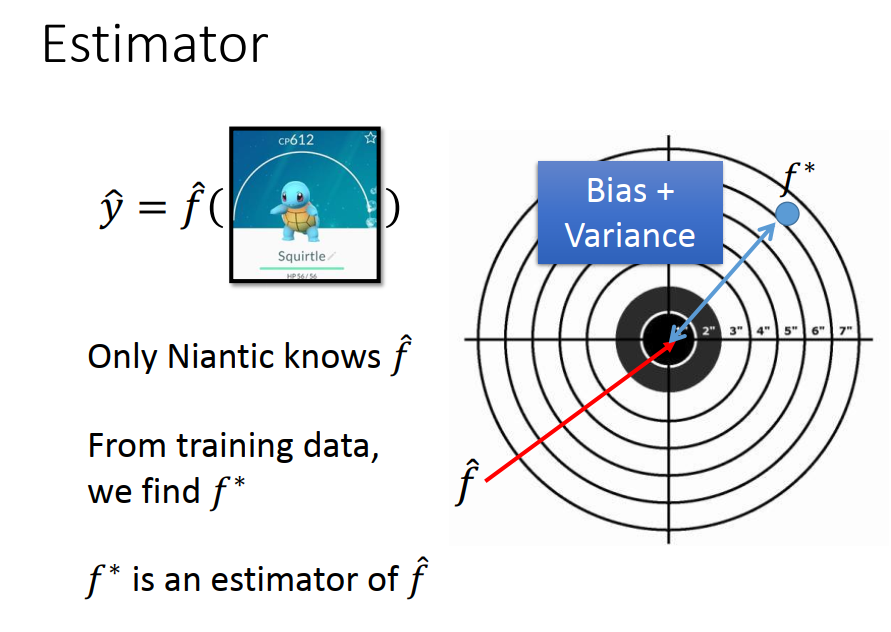
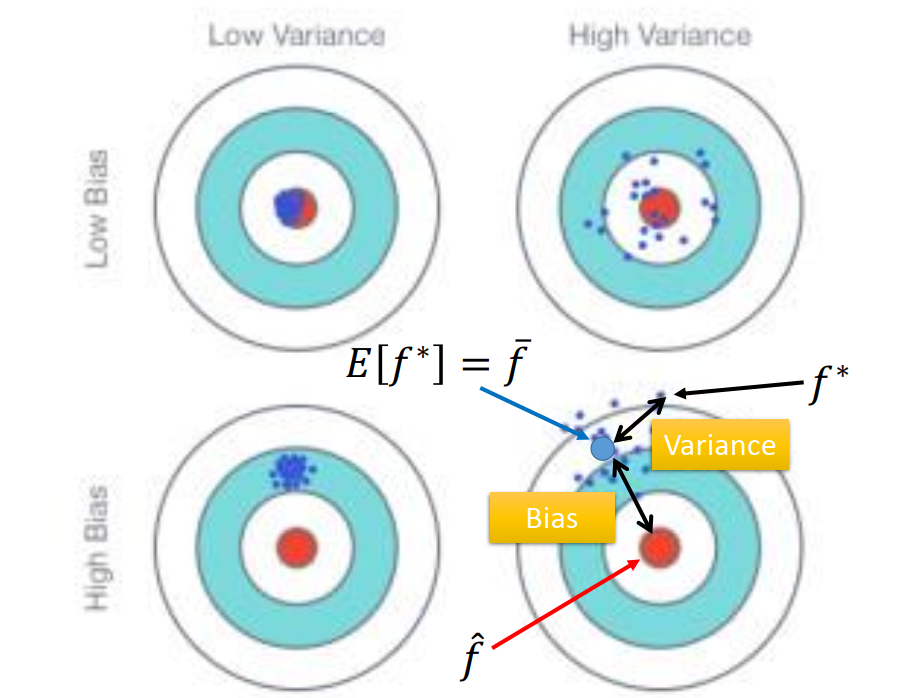
bias 是没瞄准,variance是不集中
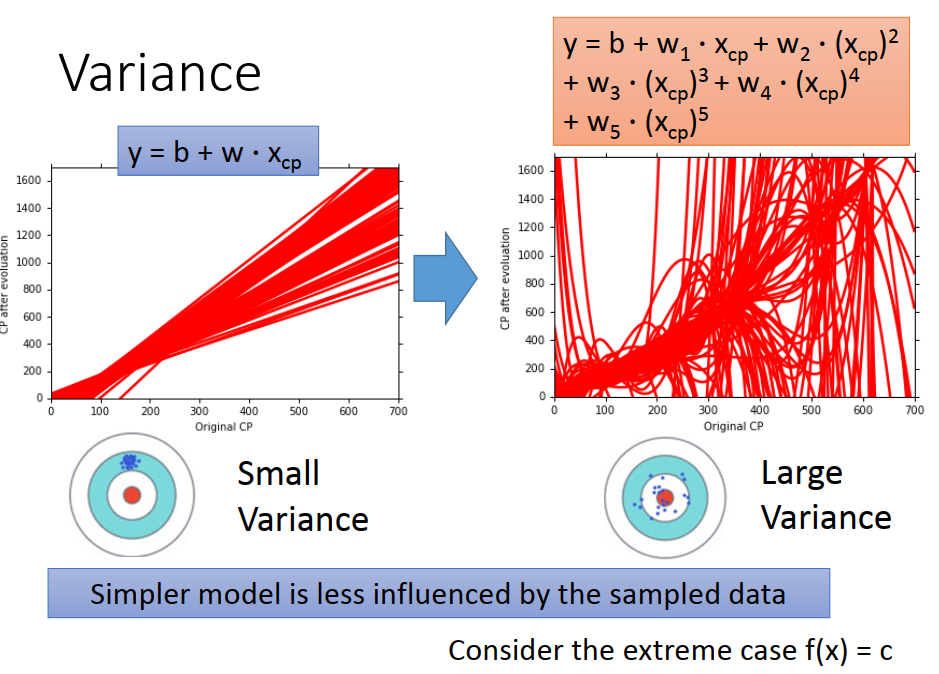
越简单的model ,variance越小。
因为越简单的model 受不同data的影响越小(比如,最简单model f(x)=c 它的variance 为0)。
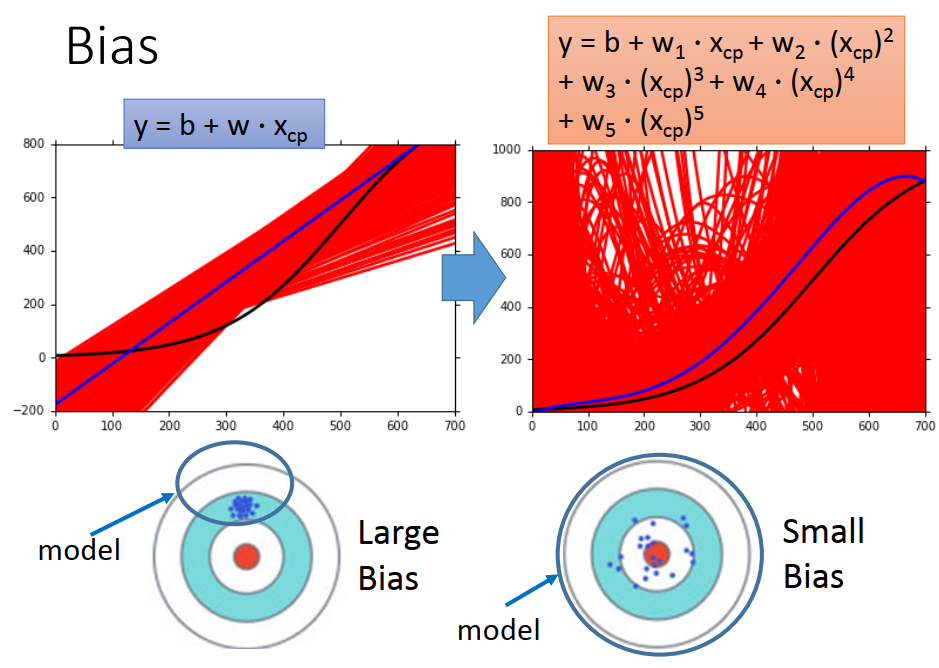

比较简单的model ,bias比较大
因为:当你定义一个model的时候,你就已经设定好说你最好的function 就只能从这个function set 里面选出。如果是一个简单的model ,它的space是比较小的,这个比较小的space,可能根本就没有包含你的target。 不管你怎么sample 你都不会平均到target。
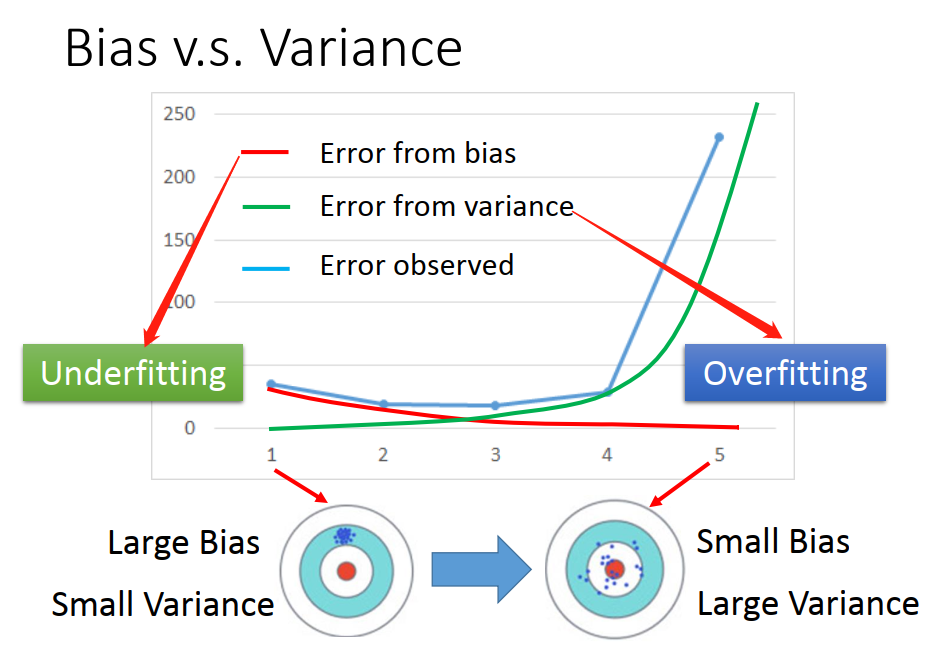
随着model越来越复杂,bias越来越小,但variance越来越大,当两者同时被考虑的时候,得到的就是蓝色的这条线(error observed)。
也就是说在某个地方你可以找到一个平衡点,让你同时考虑bias 和 variance 的时候,你得到的error是最小的。
如果你的error来自于variance 很大,这个状况就是overfitting(过拟合)。
如果你的error来自于bias很大,这个状况就是 underfitting(欠拟合)。
判断依据:
如果你的model 没办法 fit 你的training 的examples,那代表说 你的bias 是大的(你的model跟正确的model是有一段差距的)–underfitting。
**如果你可以fit 你的 training data,但是在testing data上,你却得到一个大的error,这意味着你的model 可能是variance 比较大–overfitting **。
处理方式:
如果bias 大,你需要redesign 你的model。
• Add more features as input(添加更多的特征)
• A more complex model (考虑更高次,二次、三次。。)

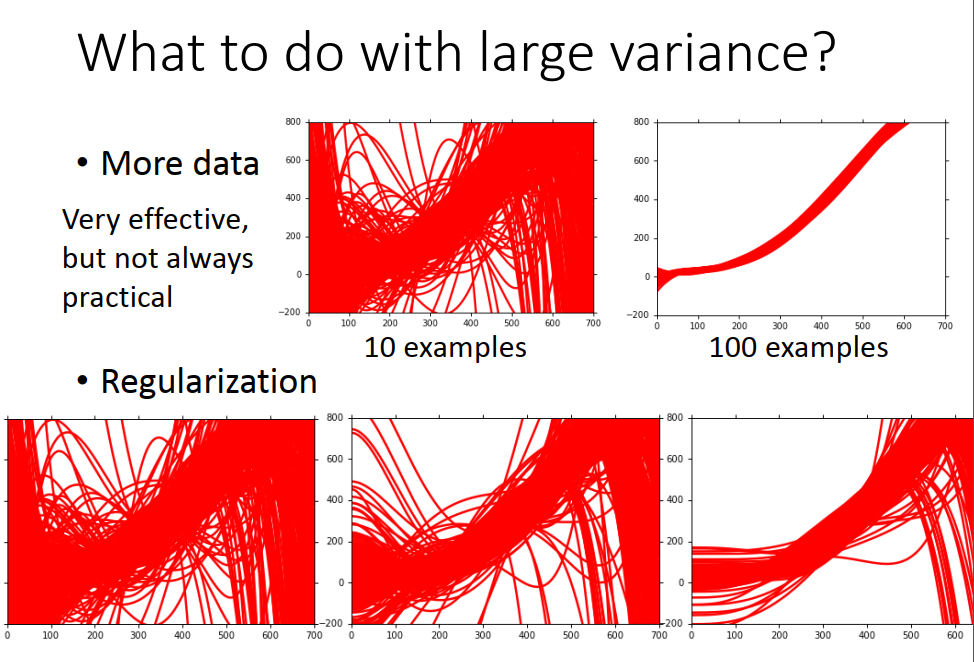
如果variance 大
• More data (不会伤害你的bias,但 collect data 很麻烦,可以自己制作)
• Regularization (可能会伤害你的bias,调整曲线后可能没办法包含你的那个目标的function)
所以,当你做regularization的时候,你要调整一下regularization的weight(weight越大 曲线越平稳) 在variance 和bias之间,取得平衡。
Model Selection
• There is usually a trade-off between bias and variance.
• Select a model that balances two kinds of error to minimize total error

不要做这件事情,分别通过training set用model 1,model 2,model 3分别去找一个best function。接下来你把它apply 到testing set 上面 根据error 找出最小的model。
但是这个testing set 是你自己手上的testing set 而真正的testing set是你没有的。
而你手上的这个testing set 有一个bias(数据采集的偏差),所有你选择的最好的model 在真正的testing set 上,不见得是最好的model,通常是比较差的。
你可以这样做:
Cross Validation 交叉验证

将training set 分成 training set 和validation set 两部分。假设model 3 的performance 是最好的,你可以直接把这个model 3 的结果拿来apply 在整个training data上(如果你担心 training set太小的话)。
这个时候,如果你把 model 3 apply 到testing set(public)上,你可能得到的error 表面上看起来比较大,但它却能反映真实的error。
通常你看到你的public set 上的结果太差,你就会想回头在调一下model,不建议这么做。
如果你再去调model 你就又把这个public testing set 的bias 考虑进去了。
这样会造成,你在这个public testing set上的error 没有办法反映 private testing set的error。
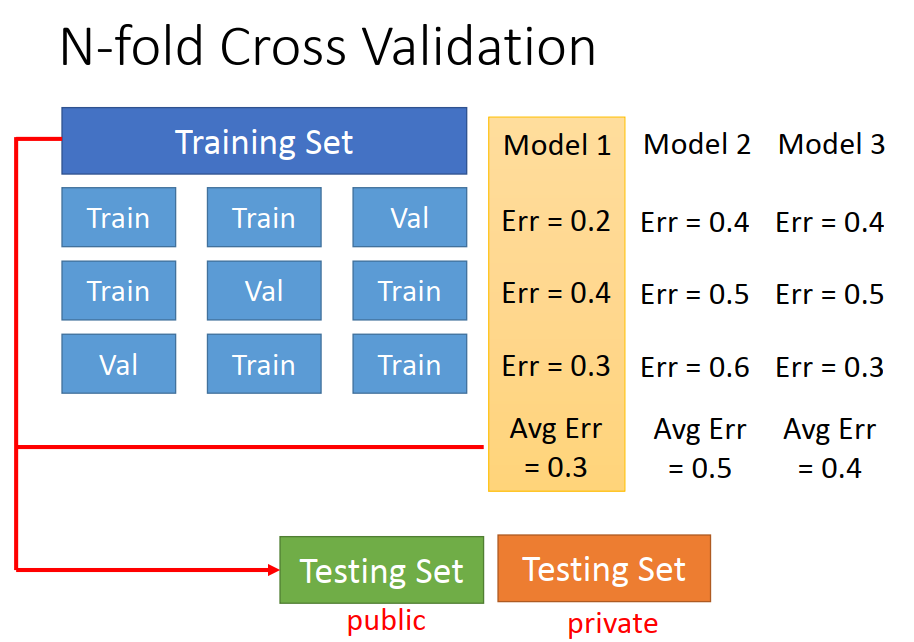
N-fold Cross Validation : N折交叉验证
如果你不相信某一次分train 跟test的结果,那你就分很多种不同的样子。
原则就是 如果你少去在意在public testing set上的分数(少去根据它调整你的model),你往往会在private set上面得到error 和public set 的差距是比较小的。
















 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











