










由于隐私、存储和其他限制,机器学习中对无监督域适应技术的需求越来越大,这种技术不需要访问用于训练源模型集合的数据。现有的多无源域自适应(MSFDA)方法主要是利用源模型产生的伪标记数据来训练目标模型,这些方法主要是改进伪标记技术或提出新的训练目标。相反,本文的目的是分析MSFDA的基本限制。特别是,我们对结果目标模型的泛化误差提出了一个信息论界限,这说明了固有的偏差-方差权衡。
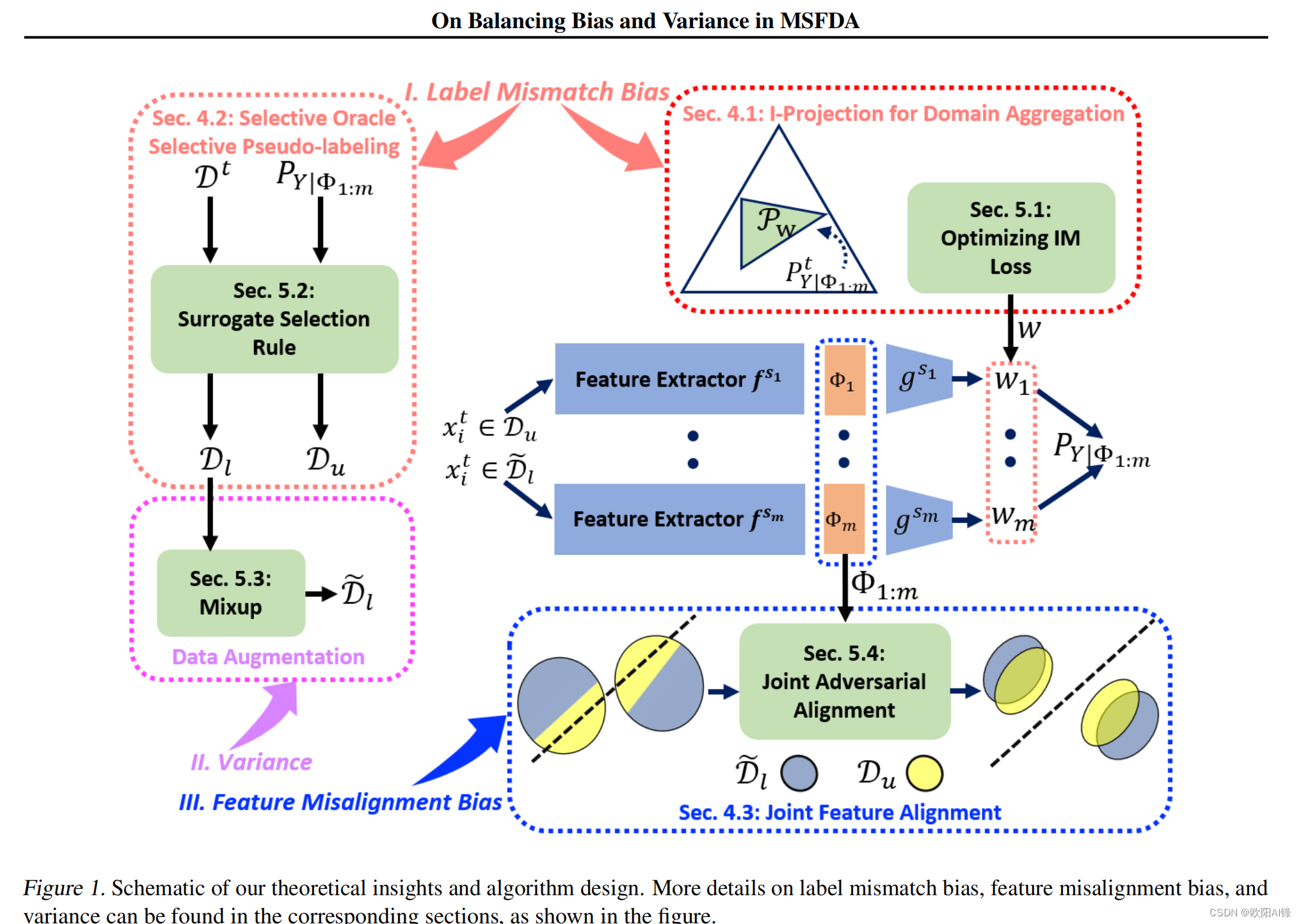


由于隐私、存储和其他限制,机器学习中对无监督域适应技术的需求越来越大,这种技术不需要访问用于训练源模型集合的数据。现有的多无源域自适应(MSFDA)方法主要是利用源模型产生的伪标记数据来训练目标模型,这些方法主要是改进伪标记技术或提出新的训练目标。相反,本文的目的是分析MSFDA的基本限制。特别是,我们对结果目标模型的泛化误差提出了一个信息论界限,这说明了固有的偏差-方差权衡。
 2115
2341
1万+
2115
2341
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























