






Getting started with reading Deep Learning Research papers: The Why and the How
当你读完那本书或者完成了关于深度学习的在线课程后,你如何继续学习呢?你如何变得“自给自足”,这样你就不需要依靠别人来打破这个领域的最新突破?
你阅读研究论文。
在你开始之前做个简短的笔记——我不是深度学习的专家。我最近才开始阅读研究论文。在这篇文章中,我将写下我刚开始觉得有用的一切。
The why
在Quora上,当被问及如何测试一个人是否有资格从事机器学习职业时,安德鲁·吴(谷歌Brain创始人,百度AI group前负责人)回答说,任何人都有资格从事机器学习职业。他说,在你完成了一些ML相关课程后,“要想走得更远,就要阅读研究论文。”更棒的是,尝试在研究论文中复制这些结果。
Dario Amodei (OpenAI的研究人员)说:“为了测试你是否适合在AI安全或ML中工作,你只需要非常快速地实现许多模型。从最近的论文中找到一个ML模型,实现它,试着让它快速工作。
这表明,阅读研究论文对于进一步了解该领域至关重要。
每个月都有数百篇论文发表,任何认真学习这一领域的人都不能仅仅依靠导师式的文章或课程,因为其他人会把最新的研究成果分解开来。在您阅读本文时,新的突破性研究正在进行中。这一领域的研究速度从未如此之快。唯一能让你跟上进度的方法就是养成阅读研究论文的习惯。
在这篇文章中,我将试着给你一些可行的建议,关于你如何开始阅读一篇论文。然后,在最后,我会试着分解一篇论文,这样你们就可以开始了。
The How
首先,阅读科研论文是困难的。事实上,“没有什么比阅读一篇科学期刊文章更让你觉得愚蠢的了。”
我只是想把它放在第一位,这样你就不会感到沮丧,如果你觉得你不能真正理解一篇论文的内容。你不太可能在前几关理解它。所以,勇敢点,再试一次吧!
现在,让我们谈谈一些对你的阅读有帮助的有价值的资源。
arXiv.org
你可以把它想象成这样一个地方:研究人员在发表论文之前,会先在那些著名的科学期刊或会议上发表(如果有的话)
他们为什么要这样做?
哦,原来做研究和写论文并不是结束。一篇论文从被提交到发表在一些科学杂志上是一个相当长的过程。当一篇论文被提交到这些期刊之后,同行评审的过程可能会非常缓慢(有时甚至会持续多年!)这对于像机器学习这样快速发展的领域来说是不可取的。
这就是为什么arXiv.出来了。
好的,所以允许研究人员轻松地预印他们的研究论文是件好事。但是那些看报纸的人呢?
如果你去arXiv网站,很容易感到害怕、渺小和迷茫。绝对不是一个新人 (就我看来,欢迎你也试试虽然☺)。

Arxiv Sanity对Arxiv所做的,就像Twitter的newsfeed对Twitter所做的(当然,它完全是开源的,没有广告)。正如newsfeed可以让你看到最有趣的tweets,个性化到你自己的口味,从浩瀚的大海中,这就是Twitter,同样地,Arxiv Sanity带给ML的论文,对你来说可能是最有趣的。它可以让你根据流行趋势、过去的喜好以及你关注的人的喜好对论文进行排序。(正是个性化推荐功能让我们得到了如此广泛的应用。
https://www.youtube.com/watch?v=S2GY3gh6qC8&feature=youtu.be Check out this short introductory video of the website to know more about it
机器学习- WAYR在Reddit上的帖子
WAYR是What Are You Reading的缩写。这是reddit https://www.reddit.com/r/MachineLearning/机器学习网站上的一个帖子https://www.reddit.com/r/MachineLearning/comments/807ex4/d_machine_learning_wayr_what_are_you_reading_week/,人们在这里发布他们这周读过的ML论文,并讨论他们从中发现的有趣之处。
正如我所说,arXiv每周在机器学习领域发表的研究论文数量是非常巨大的。这就意味着,一个人几乎不可能每周阅读所有的书籍,做一些常规的事情,比如上大学、工作,或者与他人交流。而且,并不是所有的报纸都值得一读。
因此,你需要把你的精力花在阅读最有前途的论文上,而我上面提到的线程(thread)就是一种方法。
时事通讯 时事通讯 时事通讯
时事通讯是我个人了解人工智能领域最新进展的最好来源。你可以简单地订阅他们,并把他们送到你的收件箱每周一免费!就这样,你可以了解到与人工智能相关的最有趣的新闻、文章和研究论文。
以下是我订阅的:
《进口人工智能》,杰克·克拉克著 https://jack-clark.net/
这是我最喜欢的,因为除了提供我上面提到的所有信息之外,它还有一个名为“技术故事”的部分。这部分包含了一个新的人工智能相关的科幻短篇故事基于过去一周的事件!
(嘘. .坦白说:即使是在我对人工智能的新事物不那么感兴趣的那些星期里,我也会因为科技故事而略读这篇时事通讯)
山姆·德布勒的《机器学习》 https://machinelearnings.co/
他还以同样的名字维护一个媒体出版物。它包含了一些非常有趣的文章。也一定要检查一下。
内森。《人工智能》(ai),内森·本奈奇(Nathan Benaich)著 https://www.getrevue.co/profile/nathanbenaich
虽然以上两份通讯是每周的,但这是一份季度通讯。所以,你每三个月就会收到一封很长的电子邮件,它总结了过去三个月该领域最有趣的发展。
丹尼·布里兹(Denny Britz)的《艾城狂野周》(The Wild Week in AI) https://www.getrevue.co/profile/wildml
我真的很喜欢这个,因为它非常干净,简洁,但是它似乎在过去的两个月里变得不活跃了。不管怎样,我在这里提一下,以防丹尼又开始发那些邮件。
另一种与该领域最优秀和最新的技术保持同步的好方法是关注Twitter上著名的研究人员和开发人员的帐户。以下是我跟踪的一些人:
Michael Nielsen
Andrej Karpathy
Francois Chollet
Yann LeCun
Chris Olah
Jack Clark
Jack Clark
Jeff Dean
OpenAI(我知道这不是“人”,但……)
“这很好,但我该怎么开始呢??”
是的,这是更紧迫的问题。
好的,首先要确保你理解机器学习的基础知识,比如回归和其他类似的算法,深度学习的基础知识——普通的神经网络,反向传播,正则化,以及一些比ConvNets, RNN和LSTM更基础的知识。我真的不认为阅读研究论文是理清这些主题基础的最好方法。您可以参考许多其他资源来完成此操作。
一旦你做到了这一点,你应该从阅读一篇最初介绍上述观点的论文开始。这样,你就能专注于习惯一篇研究论文的样子。你不必太担心你的第一篇研究论文,因为你已经非常熟悉这个概念了。
我建议你从AlexNet的论文开始。 Neural Information Processing Systems (NIPS)
为什么这篇文章?
看这个图:
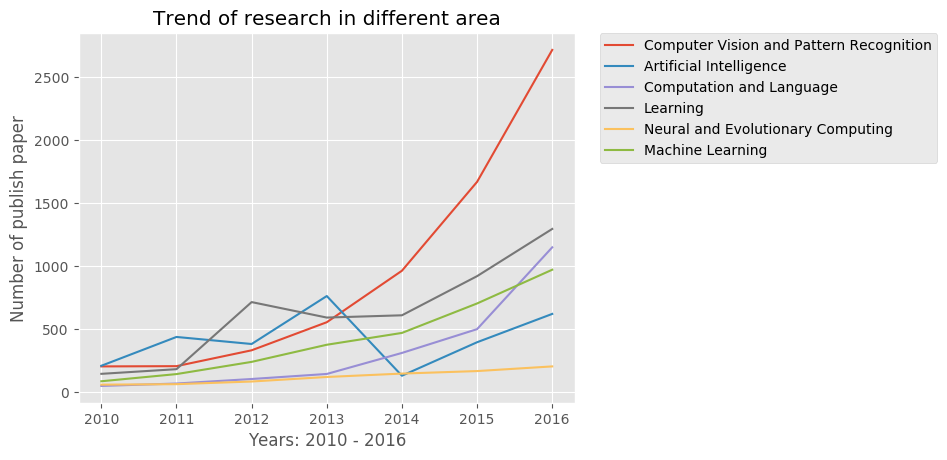
看到计算机视觉和模式识别曲线是如何在2012年迅速增长的吗?这主要是因为这篇论文。
这篇论文重新点燃了人们对深度学习的兴趣。
本文由Alex Krizhevsky、Ilya Sutskever、Geoffrey Hinton合著,标题为ImageNet Classification with Deep tional Networks,被认为是该领域最具影响力的论文之一。它描述了作者如何使用CNN(名为AlexNet)赢得2012年ImageNet大规模视觉识别挑战(ILSVRC)。
对于那些不知道的人来说,让计算机看到和识别物体(又名计算机视觉)是计算机科学最早的目标之一。ILSVRC就像奥运会上的“可视计算机”,在这种“可视计算机”中,参与者(计算机算法)试图正确地识别出属于1000个类别之一的图像。2012年,AlexNet以巨大的优势赢得了这个挑战:
它达到了最高的5个错误率15.3%,相比之下,第二好的条目收到了26.2% !
不用说,整个计算机视觉社区都感到震惊,这一领域的研究速度比以往任何时候都要快。人们开始意识到深层神经网络的力量,好吧,现在你要试着去理解你如何才能分得一杯羹!
也就是说,如果你通过一些课程或教程对CNNs有一个基本的了解,就会很容易掌握本文的内容。所以,给你更多的力量!
完成本文之后,您可以查看其他与CNN相关的开创性论文,或者迁移到您感兴趣的其他体系结构(RNNs、LSTMs、GANs)。
在Github上也有很多存储库,它们收集了很多关于深度学习的重要研究论文(这里有一个很酷的,https://github.com/floodsung/Deep-Learning-Papers-Reading-Roadmap)。开始的时候一定要了解他们的情况。他们会帮助你建立自己的阅读清单。

如果我不提及另一个消息来源,那将是极大的疏忽
如果所有的研究论文都发表在蒸馏期刊上,那么我可能就不会写这篇文章了,你不需要阅读一篇文章来指导你阅读一篇研究论文,而互联网将需要更少的课程和教程(如果有的话)来试图以可理解的方式解释这些开创性的研究思想。
我会让迈克尔·尼尔森给你一个更合适的蒸馏期刊背后的动机:
所以,一定要看看里面的文章https://distill.pub/。这真的是下一代的东西!
谢谢你从头到尾的阅读!我希望本文能够帮助您跟上最新的ML研究。记住,阅读科学论文是困难的。所以,没有必要气馁。如果你不明白,就再读一遍。















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









