









实验目的要求
- 了解ET了工具Sqoop;
- 学会安装配置Sqoop;
- 学会使用数据迁移框架Sqoop;
- 使用Sqoop导入MySQL到HDFS和Hive;
- 使用Sqoop导出HDFS数据到MySQL;
实验环境
- Java jdk 1.7;
- apache-maven-3.6.0;
- Myeclipse C10;
- CDH Hadoop集群;
- 已配置MySQL数据库;
- 已配置Sqoop工具;
- 具体规划:
| 主机名 | IP地址 | 服务描述 |
| Cmaster | 192.168.159.170 | 主控节点 |
| Cslaver1 | 192.168.159.171 | 数据节点 |
| Cslaver2 | 192.168.159.172 | 数据服务 |
实验内容
任务一: 启动CDH_Hadoop集群,并检查sqoop工具;
1、进入控制台页面;

2、启动相关组件;

任务二:使用Sqoop;
1、准备MySQL数据库数据;


2、使用Sqoop测试与MySQL的连通;
命令:
sqoop import \
--connect jdbc:mysql://192.168.159.170:3306/sqoop \
--username root \
--password 123456 \

3、使用Sqoop导入MySQL数据到HDFS;
命令:
sqoop import \
--connect jdbc:mysql://192.168.159.170:3306/sqoop \
--username root \
--password 123456 \
--table emp -m 1 \
--columns "empno,ename,job,sal,comm" \
--target-dir emp_column \
--delete-target-dir



4、使用指定压缩格式及存储格式;
命令:
sqoop import \
> --connect jdbc:mysql://192.168.159.170:3306/sqoop \
> --username root \
> --password 123456 \
> --table emp \
> -m 1 \
> --columns "empno,ename,job,sal,comm" \
> --target-dir emp_parquet \
> --delete-target-dir \
> --as-parquetfile \
> --compression-codec org.apache.hadoop.io.compress.SnappyCodec


5、使用指定分隔符;
命令:
sqoop import \
--connect jdbc:mysql://192.168.159.170:3306/sqoop \
--username root \
--password 123456 \
--table emp -m 1 \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--target-dir emp_colimn_split \
--delete-target-dir \
--fields-terminated-by '\t' \
--lines-terminated-by '\n'


6、导入指定条件的数据;
命令:
sqoop import \
--connect jdbc:mysql://192.168.159.170:3306/sqoop \
--username root \
--password 123456 \
--table emp -m 1 \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--target-dir emp_colimn_where \
--delete-target-dir \
--where 'SAL>2000'



7、导入指定查询语句的数据;
命令:
sqoop import \
--connect jdbc:mysql://192.168.159.170:3306/sqoop \
--username root \
--passw 123456 \
--target-dir emp_column_query \
--delete-target-dir \
--query 'select * from emp where EMPNO>=7900 and $CONIONS' \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' -m 1 \
--split-by 'emp'



8、使用Sqoop导出HDFS数据到MySQL;
命令:
>create table emp_demo as select * from emp where 1=2;


命令:
$hdfs dfs -mkdir -p /usr/hadoop/emp

命令:
sqoop export \
--connect jdbc:mysql://192.168.159.170:3306/sqoop \
--username root \
--password 123456 \
--table emp_demo \
--export-dir /usr/hadoop/emp -m 1



9、导出指定字段
命令:
hdfs dfs -mkdir -p /usr/hadoop/emp_colum
hdfs dfs -ls /usr/hadoop/

命令:
sqoop export \
> --connect jdbc:mysql://192.168.159.170:3306/sqoop \
> --username root \
> --password 123456 \
> --table emp_demo \
> --columns "EMPNO,ENAME,JOB,SAL,COMM" \
> --export-dir /usr/hadoop/emp_colum -m 1



10、导出表示指定分隔符
命令:
hdfs dfs -mkdir -p /usr/hadoop/emp_column_split
hdfs dfs -ls /usr/hadoop/

命令:
sqoop export \
> --connect jdbc:mysql://192.168.159.170:3306/sqoop \
> --username root \
> --password 123456 \
> --table emp_demo \
> --columns "EMPNO,ENAME,JOB,SAL,COMM" \
> --export-dir /usr/hadoop/emp_column_split \
> --fields-terminated-by '\t' \
> --lines-terminated-by '\n' -m 1


11、批量导出
命令:
sqoop export \
> -Dsqoop.export.records.pre.statement=10 \
> --connect jdbc:mysql://192.168.159.170:3306/sqoop \
> --username root \
> --password 123456 \
> --table emp_demo \
> --export-dir /usr/hadoop/emp -m 1


12、使用Sqoop导入MySQL数据到Hive中
命令:
sqoop create-hive-table \
--connect jdbc:mysql://192.168.159.170:3306/sqoop \
--username root \
--password 123456 \
--table emp \
--hive-table emp_import


13、导入表的指定字段到Hive中
命令:
create table emp_column(empno int,ename string,job string,mgr int,hiredate string,sal double,comm double,deptno int) row format delimited fields terminated by '\t' lines terminated by '\n';



任务三:将常用的Sqoop脚本定义成作业,方便其他人调用(因为版本问题,此处使用sqoop2)
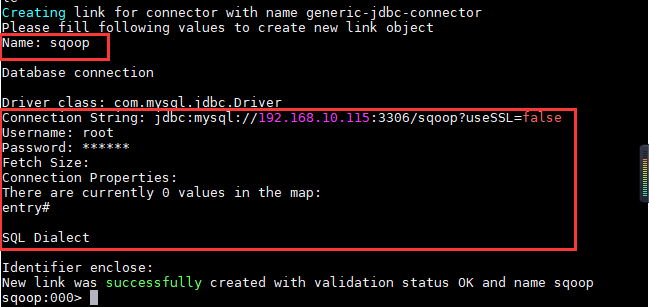
1、进入sqoop-shell,创建MySQL数据库连接;

2、查看连接信息;

3、创建HDFS文件系统连接;
命令:
>create link -connector hdfs-connector

4、创建数据传输服务(从MySQL到hdfs);
命令:
>create job f sqoop -t hdfs

5、启动job任务;
命令:
>start job -n jobsqoop

6、查看job任务状态;
命令:
>status job -n jobsqoop
出现的问题与解决方案
排错一:
错误:导入指定查询语句的数据失败

排错思路:
- 查看日志分析原因;
- 根据报错提示分析
原因分析:参数query和table不能同时使用
解决方案:
命令:
sqoop import \
--connect jdbc:mysql://192.168.159.170:3306/sqoop \
--username root \
--passw 123456 \
--target-dir emp_column_query \
--delete-target-dir \
--query 'select * from emp where EMPNO>=7900 and $CONIONS' \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' -m 1 \
--split-by 'emp'


排错二:
错误:测试sqoop1版本与mysql是否互通出错;

排错思路:
- 分析日志及错误原因;
- 分析错误提示
原因分析:缺少jar包;
解决方案:在sqoop的lib目录下加入所缺jar包,添加后正常;

知识拓展
sqoop 是 apache 旗下一款“Hadoop 和关系数据库服务器之间传送数据”的工具。
核心的功能有两个:
导入、迁入
导出、迁出
导入数据:MySQL,Oracle 导入数据到 Hadoop 的 HDFS、HIVE、HBASE 等数据存储系统
导出数据:从 Hadoop 的文件系统中导出数据到关系数据库 mysql 等 Sqoop 的本质还是一个命令行工具,和 HDFS,Hive 相比,并没有什么高深的理论。
sqoop:工具:本质就是迁移数据, 迁移的方式:就是把sqoop的迁移命令转换成MR程序
hive工具,本质就是执行计算,依赖于HDFS存储数据,把SQL转换成MR程序
2. 工作机制
将导入或导出命令翻译成 MapReduce 程序来实现 在翻译出的 MapReduce 中主要是对 InputFormat 和 OutputFormat 进行定制















 3263
3263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









