






1 HyperLogLog
1.1 HyperLogLog简介
HyperLogLog(Hyper[ˈhaɪpə(r)])并不是一种新的数据结构(实际类型为字符串类型),而是一种基数算法,通过 HyperLogLog 可以利用极小的内存空间完成独立总数的统计,数据集可以是 IP、Email、ID 等。
如果你负责开发维护一个大型的网站,有一天产品经理要网站每个网页每天的 UV 数据,然后让你来开发这个统计模块,你会如何实现?
如果统计 PV 那非常好办,给每个网页一个独立的 Redis 计数器就可以了, 这个计数器的 key 后缀加上当天的日期。这样来一个请求,incrby 一次,最终就可以统计出所有的 PV 数据。
但是 UV 不一样,它要去重,同一个用户一天之内的多次访问请求只能计数一次。这就要求每一个网页请求都需要带上用户的 ID,无论是登陆用户还是未登陆用户都需要一个唯一 ID 来标识。
一个简单的方案,那就是为每一个页面一个独立的 set 集合来存储所有当天访问过此页面的用户 ID。当一个请求过来时,我们使用 sadd 将用户 ID 塞进去就可以了。通过 scard 可以取出这个集合的大小,这个数字就是这个页面的 UV 数据。但是,如果你的页面访问量非常大,比如一个爆款页面几千万的 UV,你需要一个很大的 set 集合来统计,这就非常浪费空间。如果这样的页面很多,那所需要的存储空间是惊人的。为这样一个去重功能就耗费这样多的存储空间,值得么?其实需要的数据又不需要太精确,1050w 和 1060w 这两个数字对于老板们来说并没有多大区别,So,有没有更好的解决方案呢? 这就是HyperLogLog 的用武之地,Redis 提供了 HyperLogLog 数据结构就是用来解决这种统计问题的。HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,Redis 官方给出标准误差是 0.81%,这样的精确度已经可以满足上面的 UV 统计需求了。
1.2 HyperLogLog操作命令
HyperLogLog 提供了 3 个命令: pfadd、pfcount、pfmerge。
例如 08-15 的访问用户是 u1、u2、u3、u4,08-16 的访问用户是 u-4、u-5、u-6、u-7
pfadd
pfadd key element [element …]
pfadd 用于向 HyperLogLog 添加元素,如果添加成功返回 1:
pfadd 08-15:u:id "u1" "u2" "u3" "u4"
pfcount
pfcount key [key …]
pfcount 用于计算一个或多个 HyperLogLog 的独立总数,例如 08-15:u:id 的独立总数为 4:
pfcount 08-15:u:id
如果此时向插入 u1、u2、u3、u90,结果是 5:
pfadd 08-15:u:id "u1" "u2" "u3" "u90"
pfcount 08-15:u:id
如果我们继续往里面插入数据,比如插入 100 万条用户记录。内存增加非常少,但是 pfcount 的统计结果会出现误差。
以使用集合类型和 HperLogLog 统计百万级用户访问次数的占用空间对比:

可以看到,HyperLogLog 内存占用量小得惊人,但是用如此小空间来估算如此巨大的数据,必然不是 100%的正确,其中一定存在误差率。前面说过,Redis官方给出的数字是 0.81%的失误率。
pfmerge
pfmerge destkey sourcekey [sourcekey ... ]
pfmerge 可以求出多个 HyperLogLog 的并集并赋值给 destkey,请自行测试。
2 事务
2.1 Redis事务
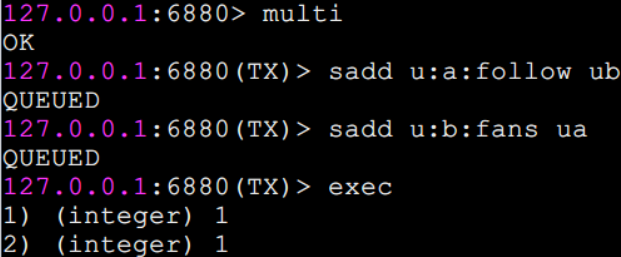
大家应该对事务比较了解,简单地说,事务表示一组动作,要么全部执行,要么全部不执行。例如在社交网站上用户 A 关注了用户 B,那么需要在用户 A 的关注表中加入用户 B,并且在用户 B 的粉丝表中添加用户 A,这两个行为要么全部执行,要么全部不执行,否则会出现数据不一致的情况。Redis 提供了简单的事务功能,将一组需要一起执行的命令放到 multi 和 exec两个命令之间。multi(['mʌlti]) 命令代表事务开始,exec(美[ɪɡˈzek])命令代表事务结束,如果要停止事务的执行,可以使用 discard 命令代替 exec 命令即可。 它们之间的命令是原子顺序执行的,例如下面操作实现了上述用户关注问题。

可以看到 sadd 命令此时的返回结果是 QUEUED,代表命令并没有真正执行,而是暂时保存在 Redis 中的一个缓存队列(所以 discard 也只是丢弃这个缓存队列中的未执行命令,并不会回滚已经操作过的数据,这一点要和关系型数据库的Rollback 操作区分开)。如果此时另一个客户端执行 sismember u:a:follow ub 返回结果应该为 0。

只有当 exec 执行后,用户 A 关注用户 B 的行为才算完成,如下所示 exec 返回的两个结果对应 sadd 命令。
另一个客户端:

如果事务中的命令出现错误,Redis 的处理机制也不尽相同。
1、命令错误
例如下面操作错将 set 写成了 sett,属于语法错误,会造成整个事务无法执行,key 和 counter 的值未发生变化:

2.运行时错误
例如用户B在添加粉丝列表时,误把sadd命令(针对集合)写成了zadd命令(针对有序集合),这种就是运行时命令,因为语法是正确的:
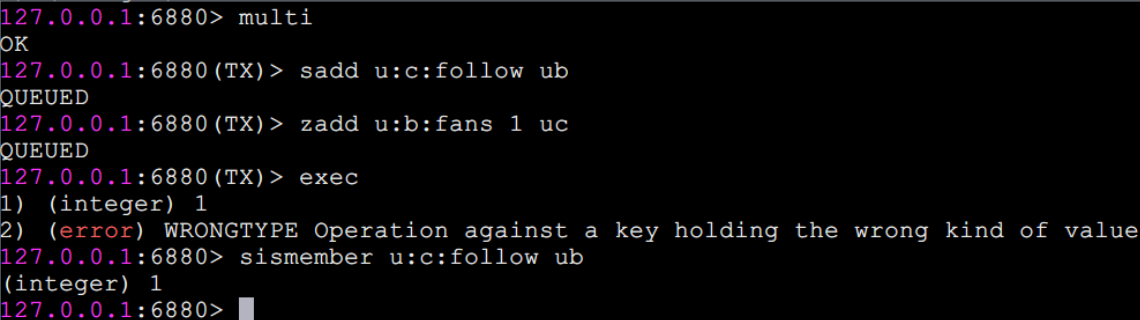
可以看到 Redis 并不支持回滚功能,sadd u:c:follow ub 命令已经执行成功,开发人员需要自己修复这类问题。
有些应用场景需要在事务之前,确保事务中的 key 没有被其他客户端修改过,才执行事务,否则不执行(类似乐观锁)。Redis 提供了 watch 命令来解决这类问题。
客户端 1:

客户端 2:

客户端 1 继续:


可以看到“客户端-1”在执行 multi 之前执行了 watch 命令,“客户端-2”在“客户端-1”执行 exec 之前修改了 key 值,造成客户端-1 事务没有执行(exec 结果为 nil)。
Redis 客户端中的事务使用代码参见:
cn.tuling.redis.adv.RedisTransaction
2.1 Redis事务与pipeline区别
简单来说,
1、pipeline 是客户端的行为,对于服务器来说是透明的,可以认为服务器无法区分客户端发送来的查询命令是以普通命令的形式还是以 pipeline 的形式发送到服务器的;
2 而事务则是实现在服务器端的行为,用户执行 MULTI 命令时,服务器会将对应这个用户的客户端对象设置为一个特殊的状态,在这个状态下后续用户执行的查询命令不会被真的执行,而是被服务器缓存起来,直到用户执行 EXEC 命令为止,服务器会将这个用户对应的客户端对象中缓存的命令按照提交的顺序依次
执行。
3、应用 pipeline 可以提服务器的吞吐能力,并提高 Redis 处理查询请求的能力。但是这里存在一个问题,当通过 pipeline 提交的查询命令数据较少,可以被内核缓冲区所容纳时,Redis 可以保证这些命令执行的原子性。然而一旦数据量过大,超过了内核缓冲区的接收大小,那么命令的执行将会被打断,原子性也就无法得到保证。因此 pipeline 只是一种提升服务器吞吐能力的机制,如果想要命令以事务的方式原子性的被执行,还是需要事务机制,或者使用更高级的脚本功能以及模块功能。
4、可以将事务和 pipeline 结合起来使用,减少事务的命令在网络上的传输时间,将多次网络 IO 缩减为一次网络 IO。Redis 提供了简单的事务,之所以说它简单,主要是因为它不支持事务中的回滚特性,同时无法实现命令之间的逻辑关系计算,当然也体现了 Redis 的“keep it simple”的特性。
3 Redis可能问到的数据结构
3.1 Trie 树
即字典树,也有的称为前缀树,是一种树形结构。广泛应用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是最大限度地减少无谓的字符串比较,查询效率比较高。
Trie 的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
先看一下几个场景问题:
1.我们输入 n 个单词,每次查询一个单词,需要回答出这个单词是否在之前输入的 n 单词中出现过。
答:当然是用 map 来实现。
2.我们输入 n 个单词,每次查询一个单词的前缀,需要回答出这个前缀是之前输入的 n 单词中多少个单词的前缀?
答:还是可以用 map 做,把输入 n 个单词中的每一个单词的前缀分别存入map 中,然后计数,这样的话复杂度会非常的高。若有 n 个单词,平均每个单词的长度为 c,那么复杂度就会达到 nc。
因此我们需要更加高效的数据结构,这时候就是 Trie 树的用武之地了。现在我们通过例子来理解什么是 Trie 树。现在我们对 cat、cash、apple、aply、ok 这几个单词建立一颗 Trie 树。

从图中可以看出:
1.每一个节点代表一个字符
2.有相同前缀的单词在树中就有公共的前缀节点。3.整棵树的根节点是空的。
4.每个节点结束的时候用一个特殊的标记来表示,这里我们用-1 来表示结束,
从根节点到-1 所经过的所有的节点对应一个英文单词。
5.查询和插入的时间复杂度为 O(k),k 为字符串长度,当然如果大量字符串没有共同前缀时还是很耗内存的。所以,总的来说,Trie 树把很多的公共前缀独立出来共享了。这样避免了很多重复的存储。想想字典集的方式,一个个的 key 被单独的存储,即使他们都有公共的前缀也要单独存储。相比字典集的方式,Trie 树显然节省更多的空间。
Trie 树其实依然比较浪费空间,比如我们前面所说的“然如果大量字符串没有共同前缀时”。
比如这个字符串列表:"deck", "did", "doe", "dog", "doge" , "dogs"。"deck"这一个分支,有没有必要一直往下来拆分吗?还是"did",存在着一样的问题。像这样的不可分叉的单支分支,其实完全可以合并,也就是压缩。
3.2 Radix树 :压缩后的trie树
所以 Radix 树就是压缩后的 Trie 树,因此也叫压缩 Trie 树。比如上面的字符串列表完全可以这样存储:

同时在具体存储上,Radix 树的处理是以 bit(或二进制数字)来读取的。一次被对比 r 个 bit。
比如"dog", "doge" , "dogs",按照人类可读的形式,dog 是 dogs 和 doge 的子串。
但是如果按照计算机的二进制比对:
dog: 01100100 01101111 01100111
doge: 01100100 01101111 01100111 01100101
dogs: 01100100 01101111 01100111 01110011
可以发现 dog 和 doge 是在第二十五位的时候不一样的。dogs 和 doge 是在第二十八位不一样的,按照位的比对的结果,doge 是 dogs 二进制子串,这样在存储时可以进一步压缩空间。
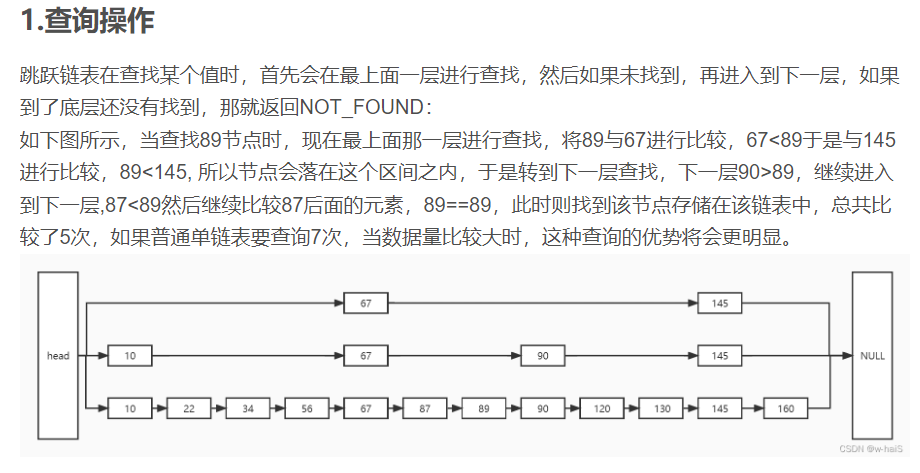
3.3 跳跃链表















 153
153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









