







目录
一、linux下的调度算法
下面是 0.11 的调度函数 schedule,在文件 kernel/sched.c 中定义为:
while (1) {
c = -1; next = 0; i = NR_TASKS; p = &task[NR_TASKS];
// 找到 counter 值最大的就绪态进程
while (--i) {
if (!*--p) continue;
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
}
// 如果有 counter 值大于 0 的就绪态进程,则退出
if (c) break;
// 如果没有:注意是所有进程(不是单单就绪态进程)
// 所有进程的 counter 值除以 2 衰减后再和 priority 值相加,
// 产生新的时间片
for(p = &LAST_TASK ; p > &FIRST_TASK ; --p)
if (*p) (*p)->counter = ((*p)->counter >> 1) + (*p)->priority;
}
// 切换到 next 进程
switch_to(next);
由上面的程序可以看出,0.11 的调度算法是选取 counter 值最大的就绪进程进行调度。
当没有 counter 值大于 0 的就绪进程时,要对所有的进程做 (*p)->counter = ((*p)->counter >> 1) + (*p)->priority。
其效果是对所有的进程(包括阻塞态进程)都进行 counter 的衰减,并再累加 priority 值。这样,对正被阻塞的进程来说,其此时的counter不为0,那么计算后得到的counter大于就绪态进程。
于是可知,一个进程在阻塞队列中停留的时间越长,其优先级越大,被分配的时间片也就会越大。
二、基于模板 process.c 编写多进程的样本程序
fork函数创建一个子进程。子进程的进程内存空间和父进程中的完全一样,并且从fork之后的地方开始执行。fork函数在父进程中返回子进程的pid,在子进程中返回0,出错时返回-1,并设置errno。
wait函数等待当前进程的子进程终止(只要有一个终止,wait系统调用就会返回),如果没有子进程终止,则会阻塞。如果成功,返回终止的子进程的pid,失败返回-1。
#include <stdio.h>
#include <unistd.h>
#include <time.h>
#include <sys/times.h> //使用了times函数
#define HZ 100 //每1/100秒产生1次时钟中断。
void cpuio_bound(int last, int cpu_time, int io_time);
int main(int argc, char * argv[])
{
if(!fork()) {
printf("I am child [%d] and my parent is [%d].\n", getpid(), getppid());
fflush(stdout);
cpuio_bound(10, 1, 0);
return 0;
}
if(!fork()) {
printf("I am child [%d] and my parent is [%d].\n", getpid(), getppid());
fflush(stdout);
cpuio_bound(10, 0, 1);
return 0;
}
if(!fork()) {
printf("I am child [%d] and my parent is [%d].\n", getpid(), getppid());
fflush(stdout);
cpuio_bound(10, 1, 9);
return 0;
}
if(!fork()) {
printf("I am child [%d] and my parent is [%d].\n", getpid(), getppid());
cpuio_bound(10, 9, 1);
return 0;
}
while(wait(NULL) != -1); //所有子进程退出后,父进程才推出;可在process.log中检验。
return 0;
}
/*
* 此函数按照参数占用CPU和I/O时间
* last: 函数实际占用CPU和I/O的总时间,不含在就绪队列中的时间,>=0是必须的
* cpu_time: 一次连续占用CPU的时间,>=0是必须的
* io_time: 一次I/O消耗的时间,>=0是必须的
* 如果last > cpu_time + io_time,则往复多次占用CPU和I/O
* 所有时间的单位为秒
*/
void cpuio_bound(int last, int cpu_time, int io_time)
{
struct tms start_time, current_time;
clock_t utime, stime;
int sleep_time;
while (last > 0)
{
/* CPU Burst */
times(&start_time);
/* 其实只有t.tms_utime才是真正的CPU时间。但我们是在模拟一个
* 只在用户状态运行的CPU大户,就像“for(;;);”。所以把t.tms_stime
* 加上很合理。*/
//为啥要算上核心态的CPU时间?
//用户CPU时间和系统CPU时间之和为CPU时间,即命令占用CPU执行的时间总和。
do
{
times(¤t_time);
utime = current_time.tms_utime - start_time.tms_utime;
stime = current_time.tms_stime - start_time.tms_stime;
} while ( ( (utime + stime) / HZ ) < cpu_time );
last -= cpu_time;
if (last <= 0 )
break;
/* IO Burst */
/* 用sleep(1)模拟1秒钟的I/O操作 */
sleep_time=0;
while (sleep_time < io_time)
{
sleep(1);
sleep_time++;
}
last -= sleep_time;
}
}
三、在 Linux0.11 上实现进程运行轨迹的跟踪与统计
1.实现对process.log文件的访问
为了能尽早开始记录,则要尽早访问log文件。而访问log文件需要满足以下3个前提:
①加载文件系统。
②建立文件描述符0、1和2与/dev/tty0的关联。
③把log文件的描述符关联到3。
原本是由进程1去实现上述①和②,但为了尽早开始记录,改由进程0实现①~③。

2.写log文件的准备工作
(1)实现fprintk函数以写log文件(在kernel/printk.c实现)
fprintk函数的用法:
// 向stdout打印正在运行的进程的ID
fprintk(1, "The ID of running process is %ld", current->pid);
// 向log文件输出跟踪进程运行轨迹
fprintk(3, "%ld\t%c\t%ld\n", current->pid, 'R', jiffies);
(2)log文件中的time指滴答数。
产生一次时钟中断则滴答1下,并且每10ms滴答一下。
(3)关键
必须找到所有发生进程状态切换的代码点,并在这些点添加适当的代码,来输出进程状态变化的情况到 log 文件中。
新建:N 就绪:J 运行:R 阻塞:W 退出:E
写入信息是要判断进程状态是否真正的发生了改变。 十分重要! 如果忽略了,那么很可能导致“Error at line 31: It is a clone of previous line.”
四、在状态切换点插入记录进程语句
①无->新建
(1)修改kernel/fork.c
调用copy_process函数实现创建进程
②新建->就绪
调用copy_process函数实现创建进程
③就绪->运行 | 运行->就绪
在schedule函数中
只有调度的不是当前进程的时候才需要记录,不然是同一个进程的话,不存在状态的变化
因此,加了if判断

④阻塞->就绪
在schedule函数中
检查闹钟,唤醒任何有信号的可中断任务

wake_up函数中:

⑤运行->阻塞 (2种:被动 + 主动)
被动
sleep_on函数中:

interruptible_sleep_on函数中:

主动
sys_pause函数中:

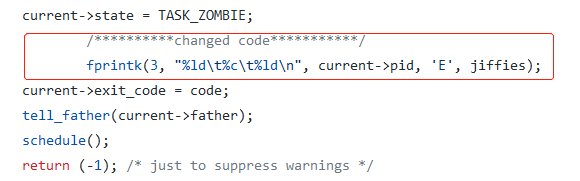
⑥运行->退出
在kernel/exit.c中
do_exit函数中:
五.一些步骤
(1)在linux-0.11目录下,make all
(2)通过sudo ./mount-hdc的方式(oslab目录下)把process.c放到linux-0.11环境下的root目录中。
(3)在oslab目录下,./run运行linux-0.11,然后在linux-0.11中编译运行process.c
(4)在linux-0.11的shell中输入sync,写入磁盘
(5)通过sudo ./mount-hdc将linux-0.11环境下的var目录中的process.log文件拷贝到ubuntu中
(6)将实验楼里/home/teacher/stat_log.py通过剪切板复制到做实验的虚拟机中。并赋予可执行的权限。
chmod +x stat_log.py

进程的完成时间(周转时间)、等待时间,
平均完成时间、平均等待时间,
吞吐量。
(0, 15, 15)

六、修改时间片大小
对现有的调度算法进行时间片大小的修改,并进行实验验证。
为完成此工作,我们需要知道两件事情:
进程 counter 是如何初始化的
首先回答第一个问题,显然这个值是在 fork() 中设定的。Linux 0.11 的 fork() 会调用 copy_process() 在这里插入代码片来完成从父进程信息拷贝(所以才称其为 fork),看看 copy_process() 的实现,会发现其中有下面两条语句:
// 用来复制父进程的PCB数据信息,包括 priority 和 counter
*p = *current;
// 初始化 counter
p->counter = p->priority;
// 因为父进程的counter数值已发生变化,而 priority 不会,
// 所以上面的第二句代码将p->counter 设置成 p->priority。
// 每个进程的 priority 都是继承自父亲进程的,除非它自己改变优先级。
①假设没有改变优先级,时间片的初值就是进程 0 的 priority,即宏 INIT_TASK 中定义的:
#define INIT_TASK \
{ 0,15,15,
// 上述三个值分别对应 state、counter 和 priority;
当进程的时间片用完时,被重新赋成何值?
接下来回答第二个问题,当就绪进程的 counter 为 0 时,不会被调度(schedule 要选取 counter 最大的,大于 0 的进程),而当所有的就绪态进程的 counter 都变成 0 时,会执行下面的语句:
(*p)->counter = ((*p)->counter >> 1) + (*p)->priority;
算出的新的 counter 值也等于 priority,即初始时间片的大小。
结果
(0, 15, 15)
(0, 30, 15)

(0,15,30)

七、log文件分析
1 N 48 //进程1新建(init())。此前是进程0建立和运行,但为什么没出现在log文件里?
1 J 49 //新建后进入就绪队列
0 J 49 //进程0从运行->就绪,让出CPU
1 R 49 //进程1运行
2 N 49 //进程1建立进程2。2会运行/etc/rc脚本,然后退出
2 J 49
1 W 49 //进程1开始等待(等待进程2退出)
2 R 49 //进程2运行
3 N 64 //进程2建立进程3。3是/bin/sh建立的运行脚本的子进程
3 J 64
2 E 68 //进程2不等进程3退出,就先走一步了
1 J 68 //进程1此前在等待进程2退出,被阻塞。进程2退出后,重新进入就绪队列
1 R 68
4 N 69 //进程1建立进程4,即shell
4 J 69
1 W 69 //进程1等待shell退出(除非执行exit命令,否则shell不会退出)
3 R 69 //进程3开始运行
3 W 75
4 R 75
5 N 107 //进程5是shell建立的不知道做什么的进程
5 J 108
4 W 108
5 R 108
4 J 110
5 E 111 //进程5很快退出
4 R 111
4 W 116 //shell等待用户输入命令。
0 R 116 //因为无事可做,所以进程0重出江湖
4 J 239 //用户输入命令了,唤醒了shell
4 R 239
4 W 240
0 R 240
……















 2085
2085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









