







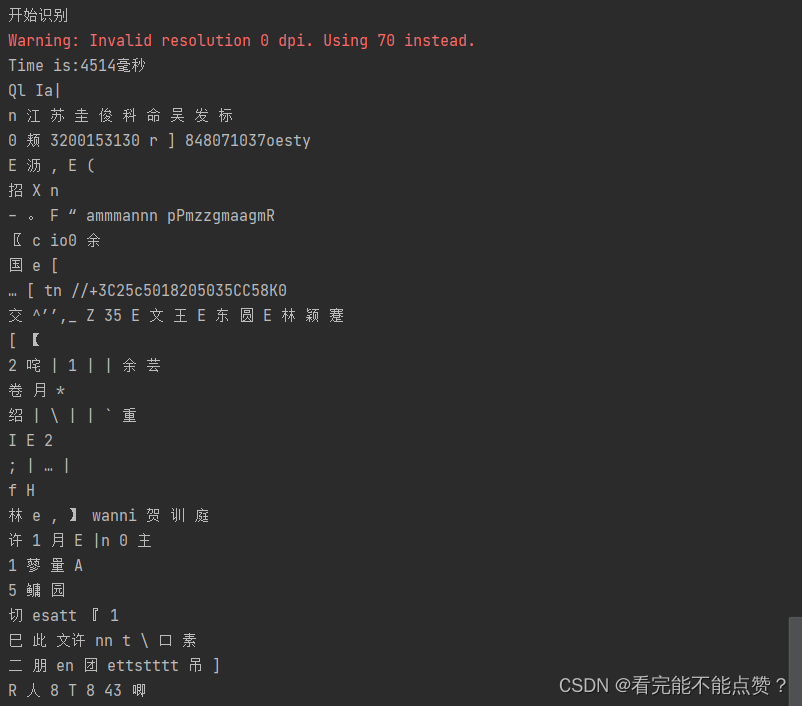
基础的识别代码识别准确率不是很高。对标准图片识别还可以,对手机拍摄出来的图片识别就相当相当啥也不是。有需要的可以拿去学习使用。
依赖:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.4</version>
</dependency>
代码:
public static void main(String[] args) {
System.out.println("开始识别");
long starttime = System.currentTimeMillis();
//获取绝对路径
String path = "D:\\testjpg.jpg";
//语言库位置
String lagnguagePath = "D:\\";
File file = new File(path);
ITesseract instance = new Tesseract();
instance.setDatapath(lagnguagePath);
//chi_sim:简体中文
instance.setLanguage("chi_sim");
String result = null;
try {
long startTime = System.currentTimeMillis();
result = instance.doOCR(file);
long endTime = System.currentTimeMillis();
System.out.println("Time is:" + (endTime - startTime) +"毫秒");
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(result);
}=================================分界线===================================
后续研究研究怎么提高准确度。
















 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









