






 文章介绍了如何下载并配置TesseractOCR的环境变量,包括在用户和系统变量中添加路径。然后,通过Python的pyocr库进行验证,但遇到在Jenkins中无法初始化OCR工具的问题,即使在CMD中可以正常工作。作者提出问题寻求帮助,希望找到Jenkins中调用pyocr失败的原因。
文章介绍了如何下载并配置TesseractOCR的环境变量,包括在用户和系统变量中添加路径。然后,通过Python的pyocr库进行验证,但遇到在Jenkins中无法初始化OCR工具的问题,即使在CMD中可以正常工作。作者提出问题寻求帮助,希望找到Jenkins中调用pyocr失败的原因。
20230306
下载链接:https://digi.bib.uni-mannheim.de/tesseract/
如下选择最新的版本,这里我选择tesseract-ocr-w64-setup-5.3.0.20221222.exe
配置tesseract的环境变量
在用户变量path中,添加安装路径如:D:\Program Files\Tesseract-OCR
在系统变量path中,添加安装路径如:D:\Program Files\Tesseract-OCR
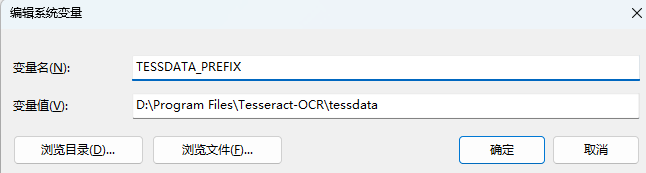
在系统变量中,新建变量名:TESSDATA_PREFIX
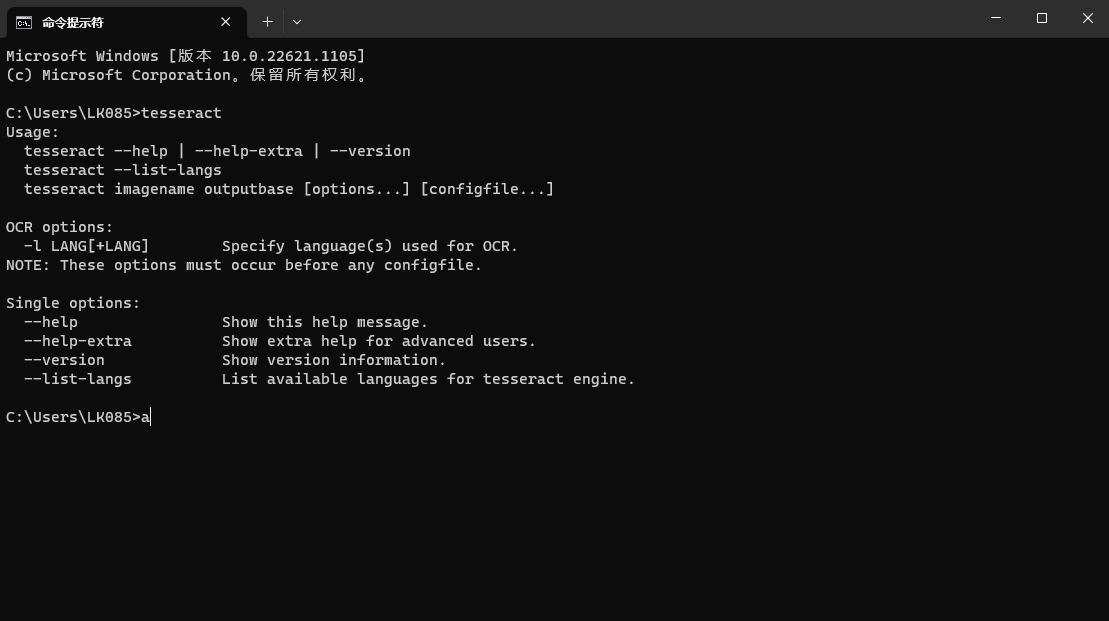
验证安装与环境配置成功:
有如下python模块操作tesseract
pyocr
国内源:pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ pyocr (亲测可用)
import pyocr
import pyocr.builders
# 初始化
tools = pyocr.get_available_tools()
# 判断tools列表中是否为空,为空则初始化失败
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
报错:No OCR tool found
如果在cmd中就无法获取tool,请检查PATH中是否有tesseract?path是否配正确?
如果cmd中能正常获取tool如下:

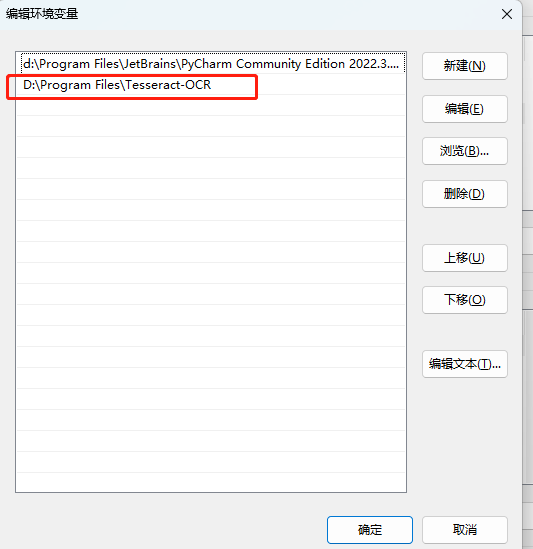
而pycharm不可以的话,请在环境变量用户变量中编辑pycharm,增加如下路径
pytesseract
from pytesseract import pytesseract
# 定义tesseract.exe的路径
path_to_tesseract = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
# Providing the tesseract executable
# location to pytesseract library
pytesseract.tesseract_cmd = path_to_tesseract
如果你有其他任何疑问,可以参考此链接:https://openpaper.work/download
20230316
发现一个问题:
当我本地测试用pyocr初始化去获取tesseract工具时,是可以获取到的,但是通过Jenkins去,却获取不到,目前仍然知晓原因,注意,Jenkins调用cmd是可行的。如果有人知道为什么或者有什么建议,可以在文章下面评论!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









