







一、logstash的一些名词介绍
Pipeline
- input-filter-output 的 3个阶段的处理流程。
- 队列管理。
- 插件生命周期管理。
Logstash Event
- 他是logstash内部流转的数据的表现形式。
- 原始数据在input 阶段被转换成 Event,在 output阶段 event 被转换成目标格式数据。
- 在配置文件中可以对 Event 中的属性进行增删改查。
架构图如下:
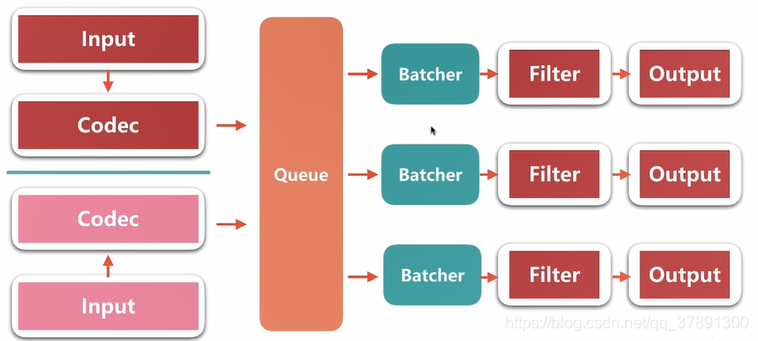
二、queue
1、分类(2类)
In Memory:无法处理进程 crash、机器宕机等情况,会导致数据丢失
Persistent Queue In Disk:
- 可处理进程crash 等情况,保证数据不会丢失
- 保证数据至少消费一次
- 充当缓冲区,可以替代kafka等消息队列的作用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5706
5706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









