







Abstract
在地理位置上分布的数据中心,生成,存储和处理大量数据已成为惯例。为了在这种地理分布的数据上运行单个数据分析作业,最近的研究建议在数据中心之间分配其任务,同时考虑数据局部性和数据中心之间的网络带宽。但是,在更普遍的情况下,这仍然是一个悬而未决的问题,在该情况下,多个分析工作需要公平地共享这些分布式数据中心的资源。在本文中,我们关注的是,在数据中心之间分配的任务属于多个作业的问题,具体目标是根据作业完成时间,在共享这些数据中心的作业之间实现最大-最小公平性。我们将此问题表述为词典最小化问题,由于其固有的多目标和离散性质,因此在实践中很难解决。为了解决这些问题,我们迭代地解决了其单目标子问题,由于其优越的性能,该子问题可以转换为等效线性规划(LP)问题以有效解决。作为本文的重点,我们已经设计并实现了我们提出的解决方案,它是基于现代数据处理框架Apache Spark的公平工作调度程序。通过在Amazon EC2上大量评估我们提出的实现,有充分的证据表明,使用我们的新作业调度程序已实现了最大-最小公平性。
1.INTRODUCTION
在世界各地的多个数据中心,在地理上分布式的生成和处理大量数据的形式越来越常见。流行的数据分析框架,如MapReduce [1]和Spark [2],被广泛用于高效地处理如此大量的数据。数据分析作业通常在连续的计算阶段中进行,每个阶段都由多个并行执行的计算任务组成。要开始一个新的计算阶段,需要提取前一阶段的中间数据,这可能会启动多个网络流。
当输入数据位于多个数据中心时,一种简单的方法是在单个数据中心内收集所有要在本地处理的数据。自然,跨数据中心传输大量数据可能会很慢且效率低下,因为数据中心间网络链接上的带宽有限。现有研究(例如[4],[5])表明,如果可以将分析作业中的任务分布在各个数据中心,并且更靠近要处理的数据,则可以实现更好的性能。在这种情况下,设计最佳的任务分配策略以将任务分配给数据中心非常重要,因为不同的策略会导致数据中心之间的流模式不同,最终导致不同的作业完成时间。
但是,在设计最佳任务分配策略时,文献[4],[5]中的现有工作仅考虑了单个数据分析工作。跨数据中心分配属于多个作业的任务的问题仍然存在。由于每个数据中心的资源数量有限,多个作业本来就会相互竞争资源。因此,在分配这样一个共享资源池时,保持公平是很重要的,如果分配一个作业的任务而不考虑其他作业,则这是无法被实现的。
本文提出了一种新的任务分配策略,当多个任务在多个地理分布的数据中心之间竞争有限的共享资源池时,任务分配策略的目标是在它们的性能上实现最大-最小的公平性。更具体地说,我们希望在保持最大-最小公平性的同时,最小化所有并发作业的作业完成时间。这样的问题可以正式表述为字典最小化问题,它具有独特的挑战,使得用多个目标解决这个问题变得困难。任务分配问题本质上是整数规划问题,通常是NP-hard的(NP是指非确定性多项式non-deterministic polynomial,缩写NP)。
为了解决这些问题,在深入研究问题结构的基础上,我们首先考虑在所有并行作业中最小化最坏(最长)作业完成时间的子问题,该子问题具有线性约束的完全幺模系数矩阵。这种良好的性质保证了可行解多面体区域的极值点是整数.此外,通过若干非平凡变换步骤,我们证明了原问题的最优解可以通过求解一个具有可分凸目标的等价问题得到。识别出这些结构后,我们便可以应用λ技术和线性松弛来获得线性规划(LP)问题,可以保证对原始问题具有相同的解决方案。因此,任何LP的求解方法,都可以用来最小化每一项作业的完成时间,并有效地计算出在最大-最小公平性下达到最优完成时间的总体分配决策。
为了证明我们提出的解决方案的实用性,我们设计并实现了一个新的作业调度器,在Apache Spark的环境下,将多个作业中的任务分配给地理分布的数据中心。我们在多个Amazon EC2数据中心的实验结果表明,我们的新调度器在优化任务完成时间和实现最大-最小公平方面是有效的。
以下是我们创新贡献的亮点。首先,正如第二节中的例子所提出的动机,我们关注的是跨多个数据中心的多个数据并行作业的联合分配任务,这考虑了在共享有限的数据中心资源池时,这些作业之间的相互作用。第二,我们的问题,在第三节中表述为字典最小化问题,具有离散和多目标的性质,使其具有挑战性。幸运的是,通过对其结构的仔细研究,我们能够识别出完全幺模约束和可分凸目标的有利性质,将其转化为一个等价的LP问题从而得到有效的解决。(第四节和第五节)。最后,为了展示它的实用性,我们在Spark作业调度框架内完成了我们所提议的解决方案的真实实现,并在Amazon EC2 (Sec. VI)多个数据中心之间进行了大量的评估。
2.BACKGROUND AND MOTIVATION
一个数据分析作业通常包含数十个或数百个任务,由一个数据并行框架(如MapReduce和Spark)支持。由于后续阶段的任务需要从当前阶段的任务中获取中间数据,所以这些任务相互并行或相互依赖,相互依赖的任务之间产生网络流。例如,在MapReduce作业中,首先启动一组map任务读取输入数据分区并生成中间结果;然后reduce任务将从map任务中获取这些中间数据以进行进一步处理,这涉及到通过网络传输数据。
在跨多个数据中心运行数据分析作业的情况下,数据可能在数据中心间的链路上传输,由于带宽可用性有限,这可能成为瓶颈。本文的设计目标是计算出将属于多个作业的任务分配到地理分布的数据中心的最佳方式,使所有作业都能在不影响其他作业性能的情况下,就其完成时间而言达到可能的最佳性能。这意味着需要在共享数据中心的作业之间实现最大最小的公平,就其作业完成时间而言。
为了更好地理解我们的问题,我们使用图1来展示两个数据分析作业共享三个地理分布的数据中心的示例。对于作业A,它的两个任务tA1和tA2,都需要存储在DC1中的输入数据集A1的100M数据,和存储在DC3中的A2数据集的200MB数据。对作业B,任务tB1从DC2的B1数据集和DC3的B2数据集,都需要读取200MB数据;任务tB2需要从B1读取200 MB的数据,从B2读取300 MB的数据。这些任务分配给三个数据中心的可用计算槽位,每个数据中心分别有两个槽位、两个槽位和一个槽位。图中显示了数据中心间链路的可用带宽,单位为MB/s。

对于每个作业,不同的任务分配将导致不同大小的流,流过不同的链接,从而导致不同的作业完成时间。此外,这两个工作一定会在这些数据中心之间共享和竞争同一个计算资源池。例如,由于DC3只有一个可用的计算槽,如果我们从一个作业分配任务给DC3,那么就不能分配来自另一个作业的任务。为了使这两项工作都能取得最佳表现,我们需要共同而不是独立地考虑如何安排它们的任务。
我们在图2和图3中说明了分配任务给数据中心的两种方法。直观地说,DC3对于来自这两个工作的任务来说都是一个很好的位置,因为它们都有一部分输入数据存储在这个数据中心,以及DC1-DC3和DC2-DC3均具有较高的带宽。如果调度程序试图独立优化这些任务的任务分配,结果如图2所示。优化作业A的分配,任务tA2将被分配到DC3中唯一可用的计算槽,tA1将被放置在DC2中,这将导致作业完成时间max{100/80,200/160,100/150} =1.25秒。然后,如果调度程序继续优化作业B的分配,则选择DC1和DC2分别分配任务tB1和tB2,使作业B的完成时间max{200/80,200/100,300/160} = 2.5秒。
然而,当考虑到这些工作的共同表现时,这种布局不是最佳的。相反,我们在图3中给出了满足最大-最小公平性的两个任务的最优分配。这样,作业B的任务tB2将占用DC3的计算槽位,从而避免了从数据集B2中转移300MB的数据。任务tB1分配给DC2而不是DC1,它可以有效的利用DC3到DC2之间链路的高带宽。因此,数据的流动模式如图所示。在这个任务中,完成作业A、B的时间分别为max{200/100,100/80,200/160} = 2秒,max{200/160,200/120} = 5/3秒。与图2中最差性能为2.5秒的独立分配相比,该分配使得作业的最差完成时间为2秒(作业A),如果我们希望最小化最差完成时间,则这种方式是最佳的,并且就两个作业实现的性能而言是公平的。我们现在准备正式构建一个数学模型来研究优化任务分配的问题,在多个任务之间实现最大-最小公平。
3.MODEL AND FORMULATION
我们考虑一组数据并行作业K ={1,2,···,k}提交给调度程序进行任务分配。这些作业的输入数据分布在一组地理分布的数据中心中,用D ={1,2,···,J}表示。每个作业k∈K都有一组并行任务Tk={1,2,···,nk}将在这些数据中心的可用计算槽上启动。我们用aj表示数据中心j∈D中可用计算槽的容量。
对于每个属于作业k任务i∈Tk,完成任务所需的时间包括,分配给数据中心 j 后,获取输入数据的网络传输时间 c ^ k i,j 和执行时间 e ^ k i,j。网络传输时间由要读取的数据量,和数据传输链路上的带宽决定。用S^k,i表示存储作业k中任务i的输入数据的数据中心集,为方便起见,称为该任务的源数据中心。任务需要从其每个源数据中心 s∈S ^k,i读取输入数据,其数量用d ^k,s i表示。让b s, j
表示从数据中心s到数据中心j的链路带宽(s != j)。因此,将任务i∈Tk分配给数据中心j时,其网络传输时间表示为:

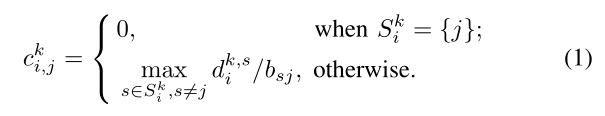
这表示当来自所有源数据中心的输入数据被获取时,网络传输完成。
任务的分配由二进制变量x^k i,j表示,指示作业k的第i个任务是否分配给数据中心j。作业k在其最慢的任务完成时完成,因此由τk表示的作业k的完成时间由其所有任务中的最大完成时间决定,表示如下:

==由于所有数据中心的计算槽由多个作业的任务共享,我们希望在不超过资源容量的情况下获得最佳的任务分配。==更具体地说,我们的调度器将决定所有任务的分配,旨在优化所有作业中作业完成时间的最差性能,然后优化下一个最差性能,而不影响前一个,等等。这将重复执行,直到所有作业的完成时间都得到优化。这样一个目标可以严格地表述为一个字典序最小化问题,其基本原理如以下定义。

有了这些定义,我们现在准备建立在所有作业之间的最优任务分配问题,如下所示:

其中约束(5)表示分配给数据中心j的任务总数不超过其容量aj,即可用计算槽的总数。
约束(6)意味着每个任务都应该分配给一个单独的数据中心。
目标是一个有K个元素的向量f ∈ R^K,每个元素代表一个特定作业 k ∈ K 的完成时间。

4.OPTIMIZING THE WORST COMPLETION TIME AMONG CONCURRENT JOBS
问题(3)是一个多目标的向量优化问题。在本节中,我们考虑优化最差作业性能的单目标子问题如下: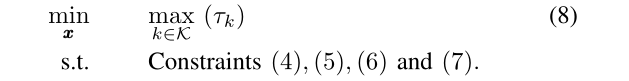
这是解决原始问题的主要步骤,将在下一节中详细阐述。
用约束条件(4)中的表达式替换目标中的完成时间Tk,在非线性约束条件(4)被消除的情况下,我们有以下问题: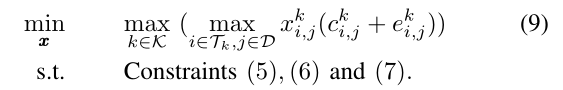
虽然这个问题是一个整数规划问题,但我们将在深入研究它的结构后,证明它可以转化为等价的线性规划问题。作为这种转换的结果,可以有效地求解以获得最优调度向量x。我们的变换利用了它的可分凸目标和全幺模线性约束的特点,它包括三个主要步骤,将在下面的小节中详细说明。
A. Separable Convex Objective(可分凸目标)
在第一步中,我们将表明,问题(9)的最优解可以通过用可分离的凸目标函数求解问题来获得,该目标函数表示为关于每个单变量x^k i,j的凸函数的和。
首先证明问题(9)的最优解可以通过求解以下问题得到: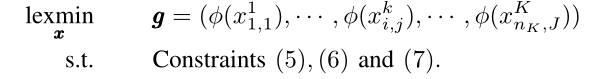
φ(x ^ k i, j) = x^k i, j (c ^k i, j + e ^k i, j),∀i∈Tk,∀j∈D,∀k∈K, g是一个维数为M的向量。对于这个问题,目标包括最小化g中的最大元素,这是所有作业中最坏的完成时间。因此,给出g∗的最优赋值变量x∗也给出了问题(9)的最优解。
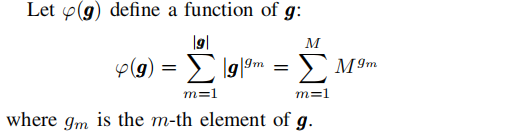



因此,解决问题(9)等价于解决以下具有可分凸目标的问题:
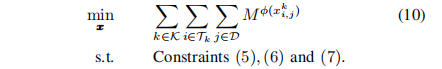
B. Totally Unimodular Linear Constraints
第二步,研究线性约束(5)和(6)的系数矩阵。一个m×n矩阵是完全幺模[6],如果它满足两个条件:1)它的任何元素都属于{-1,0,1};2)任意行子集R属于{1,2,···,m}可以分为两个不相交的集合R1和R2,例如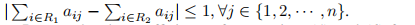
Lemma 2:约束(5)和约束(6)的系数构成一个完全幺模矩阵。
Proof:
总之,我们证明了这两个条件都满足,因此系数矩阵Am×n是完全幺模的。
C. Structure-Inspired Equivalent LP Transformation
最后,利用完全幺模约束和可分凸目标的问题结构,利用λ表示技术[7]对问题进行变换
(10)求解一个线性规划问题的最优解。
对于单个整数变量y∈Y ={0,1,···,y}, 凸函数h: Y→R可以用λ-线性化,表示如下:
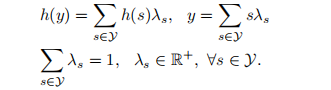
在我们的问题中,我们将λ-表示技术应用于每个凸函数h ^k i,j (x ^k i,j) = Mφ(x ^k i,j): {0,1} ->R
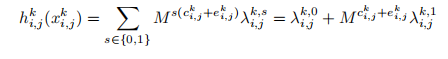
…
5.ITERATIVELY OPTIMIZING WORST COMPLETION TIMES TO ACHIEVE MAX-MIN FAIRNESS
将最小化最差完成时间的子问题有效地解决为线性规划问题(11),我们通过重复地最小化下一个最差完成时间来继续解决我们最初的多目标问题(3)。
在解决子问题后,已知最理想的最差完成时间由作业k实现,作业k的最慢任务i被分配给数据中心j。在我们确定了作业k* 的最慢任务的计算分配之后,这意味着相应的调度变量 x ^k,ij 从下一轮的变量集合x 中移除。此外,由于任务i将被分配给数据中心j,因此直观的是,与其相关的所有分配变量都应修正为0,并从集合中移除x:x ^k*,ij = 0,∀j != j*,j ∈ D。
由于我们已经确定了一部分分配,下一轮的资源容量应该在我们的问题约束中更新。例如,如果x ^ k∗,i∗ j∗= 1,这意味着任务k∗中的第i 个任务将被分配给数据中心j∗,那么对于下一轮的问题,x ^ k, * i * j 不再是变量了。资源容量限制应该更新为…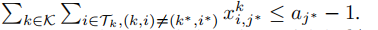
并且,得到了作业k∗的完成时间为φ(x ^k∗,i∗ j∗),即最慢任务i∗分配给数据中心j∗的完成时间,然而,此作业的其他任务的分配还没有确定,这将是下一轮问题的变量(x ^k*,i j,∀(i, j) !=(i∗,j*)。我们将这些变量的相关完成时间设置为x ^ k∗,ij (c ^k∗,i∗j∗+e ^k∗,i∗j∗)。其基本原理是,不管作业k∗的其他任务完成得有多快,完成时间由最慢的任务i∗决定的。这确保了下一轮优化的完成时间是由另一个作业完成的,而不是作业k∗的任务。图4的例子可以更好地说明这一点。

在本例中,经过第一轮的计算,DC2中分配的任务tA1在两个共享作业中完成时间最慢,为4s。在第二轮中,如果我们不改变另一个有关联的任务tA2的完成时间,则分配(a)将被计算为最优解,因为它达到了四个任务的完成时间(4,3,2.5,2),在字典序上小于分配(b)的完成(4,3.5, 2,2)。然而,分配
(a)使同一作业a的另一个任务的下一个最坏完成时间最小化,这与我们的原目标为作业B优化最坏完成时间的目标不匹配。相反,如果我们将作业A的所有任务的相关完成时间设置为4,则分配(b)实现的目标函数为(4,4,2,2),比分配(a)中的(4,4,2.5,2)要好。这样,优化就能正确地选择分配(b)达到作业b的最佳完成时间。注意,虽然作业(b)中任务tA2的完成时间比作业(a)中任务tA2的完成时间长,但作业a的完成时间仍然是4s。
因此,下一轮的子问题在一个减少的变量集上得到了解决,并更新了约束和目标,因此下一轮最差作业的完成时间将得到优化,而不会影响这一轮最差的工作表现。重复执行该过程,直到最后一个最坏的作业完成时间被优化,达到最大最小公平性,如算法1所示。
6.REAL-WORLD IMPLEMENTATION AND PERFORMANCE EVALUATION
在证明了我们的调度解决方案的理论最优性和效率之后,我们继续在Apache Spark中实现它,并在实际实验中证明了它在优化作业完成时间方面的有效性。
A. Design and Implementation
在Spark中,一个作业可以用一个有向无环图(DAG)表示,一个结点代表一个任务,一条有向边代表结点的优先级约束。一般来说,以最小化作业完成时间为目标,将一个DAG中的所有任务分配给若干个工作节点的问题称为NP-Complete[9]。Spark是一种实用、高效的任务调度方案,由DAG调度器进行任务分阶段执行。当一个作业被提交时,它被转换成一个任务的有向无环图,分类成一组阶段的集合。DAG调度器会在每个阶段(称为TaskSet)提交任务集合,每当一个阶段准备被任务调度器所调度时,这意味着它的所有父阶段都已完成。
幸运的是,Spark中的任务调度程序,可以获取本文中算法所需的大部分信息作为其输入。因此,我们实现了新的任务分配算法,作为Spark TaskScheduler模块的扩展。我们的实现设计如图5所示。在我们的实现中,只要DAG调度程序将作业中的任务集提交给任务调度程序,它们就会立即在调度池中排队。当有大量等待调度的并发作业时,当预先设置的定时器过期或池中等待调度的作业数量超过一定阈值时,将触发我们的算法。
为了优化任务的分配,我们的算法需要从每一个映射任务中知道输出数据的大小和位置,在我们的公式中,用d ^k,s j来表示。这些数据可以从MapOutputTracker中获取,并保存在reduce任务的TaskSet中。每对数据中心之间的可用带宽(b s,j)
(s to j)可以用iperf2工具进行测量。此外,有关可用资源数量的信息(对应于我们公式中的aj)可以从集群管理器中获得。既然我们算法所需的所有输入都准备好了,那么我们将通过Breeze优化库[10]中的LP求解器,迭代地制定和解决更新版本的线性规划问题,对调度池中的所有任务进行最优分配。
在计算完赋值后,它将被记录在相应的TaskSet中,覆盖原来的任务分配的参数设置。当任务最终提交执行时,这些分配的参数将以贪心的方式获得。由于调度决策将通过考虑资源提供来满足资源约束,任务集中的每个任务都可以在分配的数据中心的任何可用计算槽中启动。
B. Experimental Setup
现在,我们已经准备好评估现实世界的实现,使用部署在Amazon EC2中的6个数据中心的大量实验,这些实验以地理分布的方式分布在不同的大洲。每一对数据中心之间的可用带宽,测量iperf2实用程序,显示在表i intra-datacenter相比网络可用带宽约为1 Gbps, inter-datacenter链接更有限的带宽:几乎所有洲际链接少于100 Mbps的带宽。这证实了跨数据中心传输大量数据可能是耗时的观察结果。
在我们的实验中,我们总共使用了12个按需虚拟机(VM)实例作为位于6个数据中心的Spark集群中的Spark workers。使用弗吉尼亚州(us-east-1)的两个特殊VM实例,分别作为Spark的主节点和HDFS的[11]名称节点。所有实例的类型都是m3。大,每个有2个vcpu, 7.5 GB内存和32GB固态硬盘。在每个实例中,我们都运行Ubuntu Server 14.04 LTS 64位(HVM),安装了Java 1.8和Scala 2.11.8。安装Hadoop 2.6.4提供HDFS对Spark的支持。我们自己实现的任务分配算法是基于Spark 1.6.1的,该版本最近发布于2016年7月。我们的Spark集群以独立模式运行,所有配置都保留为默认配置。没有外部资源管理器(如YARN)或数据库系统被激活。
为了说明我们的任务分配算法的效率,我们使用遗留的排序应用程序作为基准工作负载。我们选择这个工作负载,因为它简单而原始。作为最简单的MapReduce应用程序之一,Sort只有一个map和一个reduce阶段。
然而,它的sortByKey()操作是许多复杂数据分析应用程序的基本构建块,特别是在
Spark SQL。它会触发所有的shuffle,这比其他reduce操作(如reduceByKey())带来更大的跨节点流量。
在我们的实验中,我们实现了一个具有多个作业的排序应用程序,并将其提交给Spark执行。
这些作业以并行的线程提交给Spark,从而触发并发作业共享集群资源。
因此,这些并发作业的任务分配决策将由我们在TaskScheduler中的实现来制定和执行。
为了评估不同工作负载下的性能,我们分别运行3、4和5个并发任务的工作负载作为单独的实验。
对于基准测试应用程序中的每个排序作业,默认的并行度设置为3。换句话说,该作业将触发3个reduce任务来对输入数据集进行排序,该数据集有3个分区分布在3个随机选择的工作节点上。输入数据集作为映射任务中的一个步骤准备。生成的数据集的每个分区大小为100mb,包含10,000个键-值对。然后,作为reduce任务的开始,这些键值将在网络上被打乱。由于每个数据中心只有两个工作人员,部分经过重组的流量将通过数据中心间网络链路发送,这可能是性能瓶颈。我们的任务分配算法是专门为减轻这种瓶颈的负面影响而设计的。
C. Experimental Results
我们进行了三组实验,分别有3组、4组和5组同时进行的工作。在前两组中,每个任务有三个任务;而在第三组中,将5个job的任务总数设置为可用计算槽的总数,在我们Spark集群中为12个。
在每个实验中,我们将最优任务分配算法与Spark默认调度算法的任务完成时间进行比较,作为我们比较研究的基线。
我们的实验结果如图6和图7所示,分别显示了并发作业中最差完井次数和第二最差完井次数。
对于最坏的完成时间,很容易看到我们的算法总是比Spark中的基线表现更好,性能提升达到66%,如图6所示。
对于第二差的完成时间,我们的算法在理论上不能保证它比任何不公平放置时的完成时间要小。
即使没有保证,我们的算法也总是比Spark中的基线表现出更好的性能。实验显示了令人信服的证据,我们的算法-最大最小公平性优化-是有效的最大化最坏的完成时间,并为所有并发任务实现最佳可能的性能。
为了提供更深入的检查,并说明为什么可以实现这样的性能改进,我们考虑在第二组实验中进行第7次运行,共享关系和带宽如图8所示。这六个圆圈代表了我们实验中使用的六个数据中心。A1位于Virginia数据中心,表示作业A中的任务所需的数据。对于要调度的作业A中的每个任务,需要从所有三个数据集(A1、A2和A3)读取一部分数据。由于每个数据中心有两个可用的计算槽,因此从4个作业中分配12个任务成为一对一的映射。在这样一个有限资源的场景中,任务的分配是紧密耦合的。如果不跨所有任务进行优化,Spark中的默认策略就很难找到一个好的分配。此外,Spark中的默认调度没有考虑数据中心之间的广泛可用带宽,这也解释了我们的策略相对于基线的性能改进。


此外,为了评估我们算法的实用性,我们记录了计算最优解所需的时间。
图9显示了计算时间,平均每次运行10次,变量数量从12到120不等。
我们算法中的线性程序是有效的,因为它需要大约1秒来获得48个变量的解。
对于120个变量,计算时间不到3秒,与跨数据中心的传输时间(可能是数十秒或数百秒)相比,这是可以接受的。
在我们的实验中,算法运行在有2个vcpu的VM中。
我们设想在生产环境中使用更强大的调度器服务器,运行时间可能会更小。
7.RELATED WORK
随着全球生成并存储在地理分布数据中心的数据量越来越大,跨多个数据中心部署数据分析工作的研究受到了越来越多的关注。根据他们的目标,现有的努力大致可以分为两类:减少数据中心间的网络流量,以节省运营成本;减少作业完成时间,以提高应用程序性能。
Vulimiri等人[3]、[12]首先提出减少要在数据中心之间移动的数据量,当运行时跨地理分布的数据分析工作。为了降低带宽成本,他们提出了一个整数规划问题来优化查询执行计划和数据复制策略。它们还利用丰富的存储资源积极缓存查询结果,以便后续查询利用这些结果减少数据传输。Pixida[13]建议将一个作业的DAG划分为几个部分,每个部分在一个数据中心中执行,目标是最小化这些划分部分之间的总流量。
尽管这些解决方案减少了跨数据中心的流量,但并不一定会缩短作业完成时间,因为带宽可用性在不同的链路和时间之间是不同的。
作为第二类的代表性工作,Iridium[4]提出了一种在线启发式方法,可以在数据中心之间放置数据和任务。不幸的是,它假设连接数据中心的广域网络没有拥塞,这是远远不现实的。Flutter[5]去掉了这一不现实的假设,提出了一个单工序单阶段任务分配的字典最小化问题,并得到了它的最优解。然而,现有的所有工作都集中在单个作业中分配任务,而没有考虑并发作业之间资源的内在竞争。尽管使用了与[5]相似的理论基础,我们的问题考虑了多个工作,因此显著不同,更具挑战性。
考虑到多个作业共享地理分布数据中心的情况,Hung等人[14]提出了一种贪婪调度启发式算法来跨地理分布数据中心进行作业调度决策,其目标是减少作业平均完成时间。但是,它假设任务分配是预先确定的,调度决策是每个数据中心中所有被分配任务的执行顺序。因此,尽管在地理分布的数据中心中考虑多个任务共享相同的计算资源池,但本研究与我们的工作是正交的,我们的目标是在考虑公平性的情况下,为所有共享任务确定最佳的可能任务位置。
在大数据分析框架中,已有大量关于任务分配和作业调度的工作[15]-[17]。为了减少任务完成时间,他们提出了改善数据局部性和公平性[15]、[16],并减轻进度缓慢的任务(称为掉队任务([17]))的负面影响。然而,它们都是为部署在单个数据中心的框架而设计的,不能有效地跨多个数据中心工作。
8. CONCLUDING REMARKS
本文对输入数据分布于地理分布的数据中心的竞争数据分析工作的任务分配问题进行了理论研究。针对多个任务在各个数据中心竞争计算槽的情况,我们设计并实现了一种新的最优调度程序来跨这些数据中心分配任务,以更好地满足任务需求,并在任务完成时间上实现最大最小的公平性。为了实现这一目标,我们首先制定了一个字典最小化问题来优化所有作业完成时间,这是具有挑战性的,因为多目标和离散优化固有的复杂性。为了解决这些问题,我们从单目标子问题出发,在深入研究问题结构的基础上,将其转化为一个等价的线性规划问题,并在实践中得到有效的解决。进一步设计了一种算法来重复解决更新版本的LP子问题,最终在达到最大最小公平性的情况下优化所有的工作性能。最后但并非最不重要的是,我们在流行的Spark框架中实现了性能最优的调度程序,并通过现实世界的实验证明了我们的新算法的有效性。















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









