







- LR和SVM
1、LR采用log损失,SVM采用合页损失。
2、LR对异常值敏感,SVM对异常值不敏感。
3、在训练集较小时,SVM较适用,而LR需要较多的样本。
4、LR模型找到的那个超平面,是尽量让所有点都远离他,而SVM寻找的那个超平面,是只让最靠近中间分割线的那些点尽量远离,即只用到那些支持向量的样本。
5、对非线性问题的处理方式不同,LR主要靠特征构造,必须组合交叉特征,特征离散化。SVM也可以这样,还可以通过kernel。
6、svm 更多的属于非参数模型,而logistic regression 是参数模型,本质不同。其区别就可以参考参数模型和非参模型的区别
那怎么根据特征数量和样本量来选择SVM和LR模型呢?Andrew NG的课程中给出了以下建议:
如果Feature的数量很大,跟样本数量差不多,这时候选用LR或者是Linear Kernel的SVM
如果Feature的数量比较小,样本数量一般,不算大也不算小,选用SVM+Gaussian Kernel
如果Feature的数量比较小,而样本数量很多,需要手工添加一些feature变成第一种情况。(LR和不带核函数的SVM比较类似。)
-
LR使用对数几率的意义在哪?
Logistic 回归实际上是使用线性回归模型的预测值逼近分类任务真实标记的对数几率,其优点有:
1、直接对分类的概率建模,无需实现假设数据分布,从而避免了假设分布不准确带来的问题;
2、不仅可预测出类别,还能得到该预测的概率,这对一些利用概率辅助决策的任务很有用;
3、对数几率函数是任意阶可导的凸函数,有许多数值优化算法都可以求出最优解。 -
逻辑回归的损失函数为什么要使用极大似然函数作为损失函数?
1、因为我们想要让 每一个 样本的预测都要得到最大的概率,即将所有的样本预测后的概率进行相乘都最大,也就是极大似然函数.
2、对极大似然函数取对数以后相当于对数损失函数,
在逻辑回归这个模型下,对数损失函数的训练求解参数的速度是比较快的。至于原因大家可以求出这个式子的梯度更新
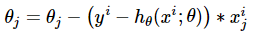
这个式子的更新速度只和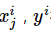 相关。和sigmod函数本身的梯度是无关的。这样更新的速度是可以自始至终都比较的稳定。
相关。和sigmod函数本身的梯度是无关的。这样更新的速度是可以自始至终都比较的稳定。 -
为什么不选平方损失函数的呢?
因为如果你使用平方损失函数,你会发现梯度更新的速度和sigmod函数本身的梯度是很相关的。sigmod函数在它在定义域内的梯度都不大于0.25。这样训练会非常的慢。 -
为什么我们还是会在训练的过程当中将高度相关的特征去掉?
去掉高度相关的特征会让模型的可解释性更好
可以大大提高训练的速度。如果模型当中有很多特征高度相关的话,就算损失函数本身收敛了,但实际上参数是没有收敛的,这样会拉低训练的速度。其次是特征多了,本身就会增大训练的时间。 -
LR对于正则项的选择:
L1 正则化就是在 loss function 后边所加正则项为 L1 范数,加上 L1 范数容易得到稀疏解(0 比较多)。L2 正则化就是 loss function 后边所加正则项为 L2 范数的平方,加上 L2 正则相比于 L1 正则来说,得到的解比较平滑(不是稀疏),但是同样能够保证解中接近于 0(但不是等于 0,所以相对平滑)的维度比较多,降低模型的复杂度。 -
LR可以用来处理非线性问题么?(还是lr啊 只不过是加了核的lr 这里加核是显式地把特征映射到高维 然后再做lr)怎么做?可以像SVM那样么?为什么?
1、

区别是:SVM如果不用核函数,也得像逻辑回归一样,在映射后的高维空间显示的定义非线性映射函数Φ,而引入了核函数之后,可以在低维空间做完点积计算后,映射到高维。
综上,逻辑回归本质上是线性回归模型,关于系数是线性函数,分离平面无论是线性还是非线性的,逻辑回归其实都可以进行分类。对于非线性的,需要自己去定义一个非线性映射。
2、使用核函数(特征组合映射):针对线性不可分的数据集,可以尝试对给定的两个feature做一个多项式特征的映射,例如
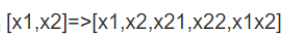
但是这种直接在交叉项xixj的前面加上交叉项系数wij的方式在稀疏数据的情况下存在一个很大的缺陷,即在对于观察样本中未出现交互的特征分量,不能对相应的参数进行估计。
即,在数据稀疏性普遍存在的实际应用场景中,二次项参数的训练是很困难的。其原因是,每个参数 wij的训练需要大量xi和 xj都非零的样本;由于样本数据本来就比较稀疏,满足xi 和 xj都非零”的样本将会非常少。训练样本的不足,很容易导致参数 wij 不准确,最终将严重影响模型的性能。
-
为什么LR把特征离散化后效果更好?离散化的好处有哪些?
逻辑回归属于广义线性模型,表达能力受限;
在工业界,很少直接将连续值作为逻辑回归模型的特征输入,而是将连续特征离散化为一系列0、1特征交给逻辑回归模型,这样做的优势有以下几点:
1、逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
2、离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
3、特征离散化以后,简化了逻辑回归模型,降低了模型过拟合的风险
4、离散特征的增加和减少都很容易,易于模型的快速迭代;
5、稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
6、离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
7、特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问; -
如何选择LR与SVM?
如果Feature的数量很大,跟样本数量差不多,这时候选用LR或者是Linear Kernel的SVM
如果Feature的数量比较小,样本数量一般,不算大也不算小,选用SVM+Gaussian Kernel
如果Feature的数量比较小,而样本数量很多,需要手工添加一些feature变成第一种情况。
- 什么是参数模型(LR)与非参数模型(SVM)?
参数模型通常假设总体(随机变量)服从某一个分布,该分布由一些参数确定(比如正太分布由均值和方差确定),在此基础上构建的模型称为参数模型;
非参数模型对于总体的分布不做任何假设,只是知道总体是一个随机变量,其分布是存在的(分布中也可能存在参数),但是无法知道其分布的形式,更不知道分布的相关参数,只有在给定一些样本的条件下,能够依据非参数统计的方法进行推断。
-
为什么LR可以用来做点击率预估?
把被点击的样本当成正例,把未点击的样本当成负例,那么样本的ctr实际上就是样本为正例的概率,LR可以输出样本为正例的概率,所以可以用来解决这类问题,另外LR相比于其他模型有求解简单、可解释强的优点,这也是工业界所看重的。 -
逻辑回归估计参数时的目标函数 (就是极大似然估计那部分)。如果加上一个先验的服从高斯分布的假设,会是什么样(其实就是在后面乘一个东西,取log后就变成加一个东西,实际就变成一个正则项)
-
LR为什么用sigmoid函数。这个函数有什么优点和缺点?为什么不用其他函数?
Sigmoid 函数到底起了什么作用:
线性回归是在实数域范围内进行预测,而分类范围则需要在 [0,1],逻辑回归减少了预测范围;
线性回归在实数域上敏感度一致,而逻辑回归在 0 附近敏感,在远离 0 点位置不敏感,这个的好处就是模型更加关注分类边界,可以增加模型的鲁棒性。
解其他的分类模型吗,问LR缺点,LR怎么推导,写LR目标函数,目标函数怎么求最优解(也不会)讲讲LR的梯度下降,梯度下降有哪几种,逻辑函数是啥
LR与其他模型的对比:
-
LR与线性回归
1、线性回归和逻辑回归都是广义线性回归模型的特例
2、 线性回归只能用于回归问题,逻辑回归用于分类问题(可由二分类推广至多分类)
3、 线性回归使用最小二乘法作为参数估计方法,逻辑回归使用极大似然法作为参数估计方法
4、 逻辑回归引入了sigmoid函数,把y值从线性回归的(−∞,+∞)限制到了(0,1)的范围。
5、 逻辑回归通过阈值判断的方式,引入了非线性因素,可以处理分类问题。
6、 线性回归要求变量服从正态分布,logistic回归对变量分布没有要求。 -
LR与 SVM
相同点:
都是分类算法,本质上都是在找最佳分类超平面;
都是监督学习算法;
都是判别式模型,判别模型不关心数据是怎么生成的,它只关心数据之间的差别,然后用差别来简单对给定的一个数据进行分类;
都可以增加不同的正则项。
不同点:
1、LR 是一个统计的方法,SVM 是一个几何的方法;
2、SVM 的处理方法是只考虑 Support Vectors,也就是和分类最相关的少数点去学习分类器。而逻辑回归通过非线性映射减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重;
3、损失函数不同:LR 的损失函数是交叉熵,SVM 的损失函数是 HingeLoss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。对 HingeLoss 来说,其零区域对应的正是非支持向量的普通样本,从而所有的普通样本都不参与最终超平面的决定,这是支持向量机最大的优势所在,对训练样本数目的依赖大减少,而且提高了训练效率;
4、LR 是参数模型,SVM 是非参数模型,参数模型的前提是假设数据服从某一分布,该分布由一些参数确定(比如正太分布由均值和方差确定),在此基础上构建的模型称为参数模型;非参数模型对于总体的分布不做任何假设,只是知道总体是一个随机变量,其分布是存在的(分布中也可能存在参数),但是无法知道其分布的形式,更不知道分布的相关参数,只有在给定一些样本的条件下,能够依据非参数统计的方法进行推断。所以 LR 受数据分布影响,尤其是样本不均衡时影响很大,需要先做平衡,而 SVM 不直接依赖于分布;
5、LR 可以产生概率,SVM 不能;
6、LR 不依赖样本之间的距离,SVM 是基于距离的;
7、LR 相对来说模型更简单好理解,特别是大规模线性分类时并行计算比较方便。而 SVM 的理解和优化相对来说复杂一些,SVM 转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
- 逻辑回归的求解方法
1、由于该极大似然函数无法直接求解,我们一般通过对该函数进行梯度下降来不断逼急最优解。在这个地方其实会有个加分的项,考察你对其他优化方法的了解。因为就梯度下降本身来看的话就有随机梯度下降,批梯度下降,small batch 梯度下降三种方式,面试官可能会问这三种方式的优劣以及如何选择最合适的梯度下降方式。
(1)简单来说 批梯度下降会获得全局最优解,缺点是在更新每个参数的时候需要遍历所有的数据,计算量会很大,并且会有很多的冗余计算,导致的结果是当数据量大的时候,每个参数的更新都会很慢。
(2)随机梯度下降是以高方差频繁更新,优点是使得sgd会跳到新的和潜在更好的局部最优解,缺点是使得收敛到局部最优解的过程更加的复杂。
(3)小批量梯度下降结合了sgd和batch gd的优点,每次更新的时候使用n个样本。减少了参数更新的次数,可以达到更加稳定收敛结果,一般在深度学习当中我们采用这种方法。
LINK:https://blog.csdn.net/sinat_33231573/article/details/99709837















 6861
6861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









