








1、树模型
决策树:从根节点开始一步步走到叶子节点(决策)
所有的数据最终都会落到叶子节点,既可以做分类也可以做回归
2、树的构造
根节点:第一个选择点
非叶子节点与分支:中间过程
叶子节点:最终的决策结果
1) 开始:构建根节点,将所有训练数据都放在根节点,选择一个最优特征,按着这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。
2) 如果这些子集已经能够被基本正确分类,那么构建叶节点,并将这些子集分到所对应的叶节点去。
3)如果还有子集不能够被正确的分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的节点,如果递归进行,直至所有训练数据子集被基本正确的分类,或者没有合适的特征为止。
4)每个子集都被分到叶节点上,即都有了明确的类,这样就生成了一颗决策树。
3、决策树的训练与测试
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建。
- 训练阶段:从给定的训练集构造出一棵树(从跟节点开始选择特征,如何进行特征切分?)
- 测试阶段:根据构造出来的树模型从上到下走一遍,一旦构造好了决策树,那么分类或者预测任务就很简单了
- 难点就在于如何构造出来一颗树
(1)选择特征的衡量标准
目标:通过一种衡量标准(分类的效果较好),来计算通过不同特征进行分支选择后的分类情况,找出来最好的那个当成根节点,以此类推
衡量标准-熵
**熵:**表示随机变量不确定性的度量(物体内部的混乱程度,如杂货市场比专卖店的熵大)
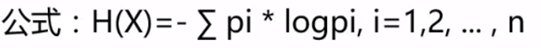 (只取x为0~1的y值,需取反)
(只取x为0~1的y值,需取反)

结论:熵越接近1(越杂乱),确定性越小,熵越接近0,确定性越大
熵:不确定性越大,得到的熵值也就越大
当p=0或p=1时,H§=0,随机变量完全没有不确定性
当p=0.5时,H§=1,此时随机变量的不确定性最大
(如抛硬币时,概率都为0.5,不确定性很大)
(2)选择节点
信息增益:表示特征X使得类Y的不确定性减少的程度,即提升纯度的大小。
(例:当前有十个特征,分别遍历每个特征对熵值的改变程度,改变的越大,则此特征信息增益较大)
示例:根据天气情况是否打球
现有特征:室外的环境(太阳、阴天、下雨),温度(热、冷、温和),湿度,,是否有风
标签为:打、不打


a、求根节点的熵
在历史数据中,有9天打球,5天不打球,所以此时的熵为:
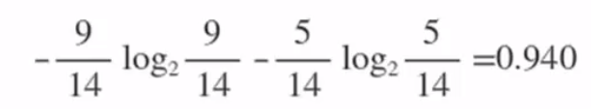
b、某特征的熵
’室外环境‘ 特征的熵
当outlook=sunny时,yes:no=2:3
则
- Psunny= (2/5) * log(2/5) + (3/5) * log(3/5)=0.971
- Povercast= 1 * log1 + (0/5) * log(0/5)=0
- Prainy= (3/5) * log(3/5) + (2/5) * log(2/5)=0.971

c、遍历每个特征,计算出每个特征对应的信息增益
*信息增益 = 划分前熵 - 划分后熵(跟节点的熵 - 特征的熵)
并选择信息增益最大的特征作为根节点,同样的方法得到其他的节点,每个子集都被分到叶节点上,即都有了明确的类,这样就生成了一颗决策树
-
根据数据统计,outlook取值分别为sunny,overcast,rainy的概率分别为:
5/14, 4/14, 5/14 -
特征的熵值计算:5/14 * 0.971 + 4/14 * 0 + 5/14 * 0.971 = 0.693
(gain(temperature)=0.029 gain(humidity)=0.152 gain(windy)=0.048) -
信息增益:系统的熵值从原始的0.940下降到了0.693,增益为0.247
同样的方式可以计算出其他特征的信息增益,那么我们选择最大的那个,相当于是遍历了一遍特征,找出来了大当家,然后再其的
中继续通过信息增益找二当家
4、决策树算法的改进过程:
ID3模型:
ID3算法的核心是在决策树各个结点上对应信息增益准则选择特征,递归地构建决策树。
具体方法是:
1)从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征。
2)由该特征的不同取值建立子节点,再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止;
3)最后得到一个决策树。
缺点:若考虑ID作为一类特征加入训练,我们会发现,每个ID对应一个样本,ID作为特征将产生14个分支,每个叶子节点只包含一个样本,ID特征的熵:(1/14)* log(1/14)*14 ,此时信息增益远大于其他特征,如果模型中存在这样的特征,则这样的决策显然不具有泛化能力,无法会新样本进行有效预测。

C4.5模型:
信息增益准则对可取值数目较多的属性有所偏好。为解决这个问题,提出了C4.5模型,使用信息增益比来选择特征。
信息增益比 = 信息增益 / 划分前熵
C4.5模型选择信息增益比最大的作为最优特征,信息增益率对可取值数目较少的属性有所偏好
C4.5 处理连续特征是先将特征取值排序,以连续两个值中间值作为划分标准。尝试每一种划分,并计算修正后的信息增益,选择信息增益最大的分裂点作为该属性的分裂点。
CART模型:
GINI系数:概率越接近1,确定性越大,则GINI系数越小(与熵值类似)
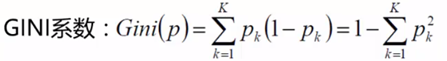
直观来说,Gini反应了从数据集D中随机抽取两个样本,其类别标记不一致的概率。因此概率越大,Gini越小,数据集的纯度越高。
衡量标准的对比:
(1)信息增益 vs 信息增益比
之所以引入了信息增益比,是由于信息增益的一个缺点。那就是:信息增益总是偏向于选择取值较多的属性。信息增益比在此基础上增加了一个罚项,解决了这个问题。
(2)Gini 指数 vs 熵
既然这两个都可以表示数据的不确定性,不纯度。那么这两个有什么区别那?
Gini 指数的计算不需要对数运算,更加高效;
Gini 指数更偏向于连续属性,熵更偏向于离散属性。
5、决策树剪枝策略
为何要剪枝:防止过拟合,决策树过拟合分线很大,理论上可以完全分得开数据(分得太详细)
剪枝策略:
(1)预剪枝:边建立决策树边进行剪枝的操作(特征较多时,只选择部分特征作为参数减少深度)
预剪枝操作:
限制深度
叶子节点个数
叶子节点样本数
信息增益量(达到阈值时不再分裂)
(2)后剪枝:先建立完决策树,在进行剪枝操作
后剪枝操作:
通过一定的衡量标准(叶子节点越多,损失越大)
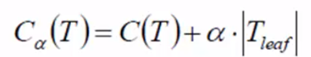
第一项 C(T)为当前的损失:叶子节点样本数 * 熵值(或GINI系数) <-- 每片叶子都要累加
第二项 a*T:为了限制叶子个数(Tleaf:叶子节点的个数)
遍历所有的节点,再判断某个节点是否需要分裂
如判断下图红底节点时
首先计算不分裂的情况:Ca1(T)=90.49+a1 // 1为不分裂时的叶子树
再计算分裂的情况:Ca2(T)=30+30+30.44+a3 // 3为分裂后的叶子数
再进行比较,结果大的效果不好,即可进行是否剪枝的判断
6、决策树的特点:
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
缺点:可能会产生过度匹配的问题
适用数据类型:数值型和标称型
7、结论
决策树算法主要包括三个部分:特征选择、树的生成、树的剪枝。常用算法有 ID3、C4.5、CART。
特征选择。特征选择的目的是选取能够对训练集分类的特征。特征选择的关键是准则:信息增益、信息增益比、Gini 指数;
决策树的生成。通常是利用信息增益最大、信息增益比最大、Gini 指数最小作为特征选择的准则。从根节点开始,递归的生成决策树。相当于是不断选取局部最优特征,或将训练集分割为基本能够正确分类的子集;
决策树的剪枝。决策树的剪枝是为了防止树的过拟合,增强其泛化能力。包括预剪枝和后剪枝。















 2964
2964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









