






一、树剪枝概述
1.什么是剪枝?
通过降低决策树的复杂度来避免过拟合的过程称为剪枝。
2.为什么要剪枝?
决策树算法在学习的过程中为了尽可能正确的分类训练样本,不停地对结点进行划分,因此这会导致整棵决策树的分支过多,也就导致了过拟合。所以我们可通过“剪枝”来一定程度避免因决策分支过多,以致于把训练集自身的一些特点当做所有数据都具有的一般性质而导致的过拟合。
2.剪枝的基本策略:
- 预剪枝:预剪枝就是在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点记为叶结点,其类别标记为该节点对应训练样例数最多的类别。
- 后剪枝:后剪枝就是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行分析计算,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
二、预剪枝
1.数据集:


2.未剪枝决策树:
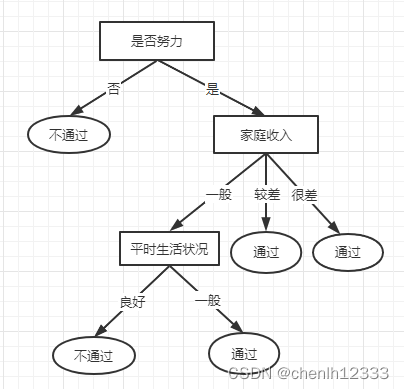
3.预剪枝过程:
针对上述数据集,基于信息增益准则,选取属性“是否努力”划分训练集。分别计算划分前(即直接将该结点作为叶结点)及划分后的验证集精度,判断是否需要划分。
(1)结点1:若不划分,则将其标记为叶结点,类别标记为训练样例中最多的类别,即“通过”。验证集中编号{20}被分类正确,得到验证集精度为 (1/5)*100%=20%
(2)结点1::若划分,则根据结点2、3的训练样例,将这2个结点分别标记为“不通过”、“通过”:
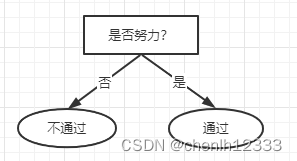
此时,验证集中编号{18,19,20}的样例被划分正确,验证集精度为 (3/5)*100%=60%:

由于60%>20%,划分后验证集的精度更高,所以继续划分。
(3)结点2:本身为叶子结点。
(4)结点3:选取属性“家庭收入”继续划分:
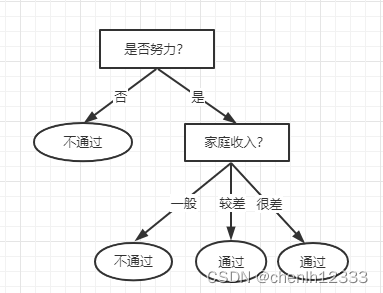
验证集中编号为{16,17,20}的样例被划分正确,验证集精度为 (3/5)*100%=60%:
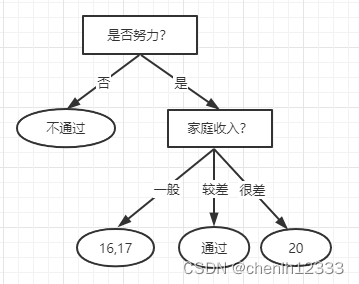
由于60%=60%, 划分后验证集的精度没有提高,所以取消划分。
(4)最终得到仅有一层划分的决策树:
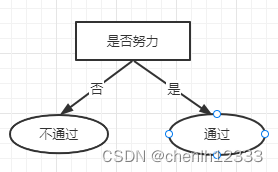
4.编写代码:
def createTreePrePruning(dataTrain, labelTrain, dataTest, labelTest, names, method = 'id3'):
trainData = np.asarray(dataTrain)
labelTrain = np.asarray(labelTrain)
testData = np.asarray(dataTest)
labelTest = np.asarray(labelTest)
names = np.asarray(names)
# 如果结果为单一结果
if len(set(labelTrain)) == 1:
return labelTrain[0]
# 如果没有待分类特征
elif trainData.size == 0:
return voteLabel(labelTrain)
# 其他情况则选取特征
bestFeat, bestEnt = bestFeature(dataTrain, labelTrain, method = method)
# 取特征名称
bestFeatName = names[bestFeat]
# 从特征名称列表删除已取得特征名称
names = np.delete(names, [bestFeat])
# 根据最优特征进行分割
dataTrainSet, labelTrainSet = splitFeatureData(dataTrain, labelTrain, bestFeat)
# 预剪枝评估
# 划分前的分类标签
labelTrainLabelPre = voteLabel(labelTrain)
labelTrainRatioPre = equalNums(labelTrain, labelTrainLabelPre) / labelTrain.size
# 划分后的精度计算
if dataTest is not None:
dataTestSet, labelTestSet = splitFeatureData(dataTest, labelTest, bestFeat)
# 划分前的测试标签正确比例
labelTestRatioPre = equalNums(labelTest, labelTrainLabelPre) / labelTest.size
# 划分后每个特征值的分类标签正确的数量
labelTrainEqNumPost = 0
for val in labelTrainSet.keys():
labelTrainEqNumPost += equalNums(labelTestSet.get(val), voteLabel(labelTrainSet.get(val))) + 0.0
# 划分后正确的比例
labelTestRatioPost = labelTrainEqNumPost / labelTest.size
# 如果没有评估数据 但划分前的精度等于最小值0.5 则继续划分
if dataTest is None and labelTrainRatioPre == 0.5:
decisionTree = {bestFeatName: {}}
for featValue in dataTrainSet.keys():
decisionTree[bestFeatName][featValue] = createTreePrePruning(dataTrainSet.get(featValue), labelTrainSet.get(featValue)
, None, None, names, method)
elif dataTest is None:
return labelTrainLabelPre
# 如果划分后的精度相比划分前的精度下降, 则直接作为叶子节点返回
elif labelTestRatioPost < labelTestRatioPre:
return labelTrainLabelPre
else :
# 根据选取的特征名称创建树节点
decisionTree = {bestFeatName: {}}
# 对最优特征的每个特征值所分的数据子集进行计算
for featValue in dataTrainSet.keys():
decisionTree[bestFeatName][featValue] = createTreePrePruning(dataTrainSet.get(featValue), labelTrainSet.get(featValue)
, dataTestSet.get(featValue), labelTestSet.get(featValue)
, names, method)
return decisionTree 5.总结:
比较未剪枝决策树和经过预剪枝的决策树可以看出(预剪枝优缺点),预剪枝使得决策树的很多分支都没有展开,这降低了过拟合的风险,也显著减少了训练时间和测试时间的开销。但是,有些分支当前的划分也许不能提升泛化性能,但其后续划分却可能可以提升泛化性能,预剪枝基于“贪心”本质禁止这些分支展开,带来了欠拟合风险。
6.参考教材:
机器学习实战















 1484
1484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









