







基本以 https://wmathor.com/index.php/archives/1438/ 和 https://github.com/jadore801120/attention-is-all-you-need-pytorch为教材进行学习。
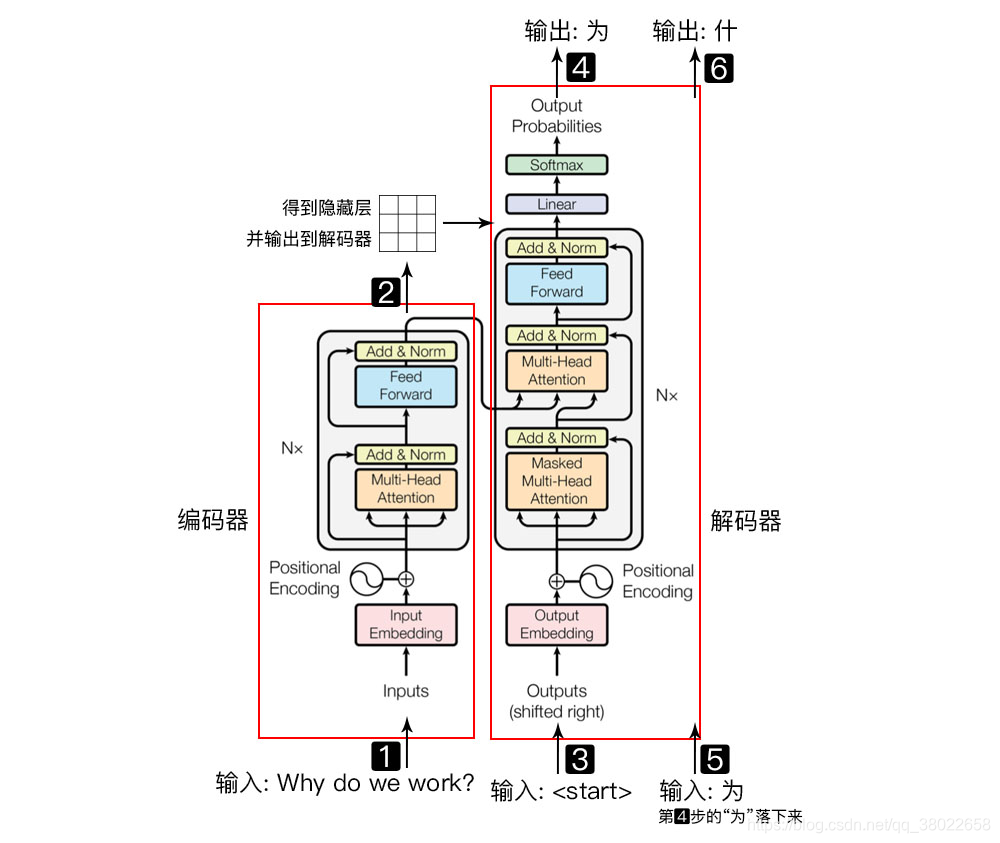
关键点:
1.encoder的隐藏层作为decoder的multi-head-attention的k,v矩阵的input,而decoder多头注意力的q矩阵的input由它自身的masked multi-head-attention经过LN和残差结构得到。
2.encoder的input是可以并行的,也因此要加一个positional encoding来提供顺序信息。但是decoder是不并行的,上一个的output输出后,作为下一次的output embedding输入
3.masked multi-head-attention 是多经过了一个右上全为false的对角矩阵,用来保证注意力仅在当前词之前的词之上
4.源码中出现了BPE (byte pair encoding)的部分,参考https://blog.csdn.net/foneone/article/details/103811328和https://blog.csdn.net/bf96163/article/details/105967287/文章,本质上是学习模块化频繁字符串来简化编
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









