







AUC含义的通俗理解
假设有一个分类器,并且该分类器可以得到将一个样本预测为正的概率,并将此概率称为这个样本的得分。
首先说一下AUC的含义:随机给定一个正样本和一个负样本,用一个分类器进行分类和预测,该正样本的得分比该负样本的得分要大的概率。
那么应该如何理解这个含义呢?首先我们要知道ROC曲线是怎么画出来的。而AUC即ROC曲线下面的面积。
1. 混淆矩阵
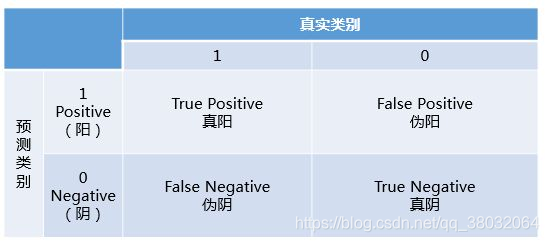
(图源:https://www.zhihu.com/question/39840928)
从这个矩阵中我们引入了真阳率(True Positive Rate, TPR)以及假阳率(False Positive Rate, FPR)的概念:
T
P
R
=
T
P
T
P
+
F
N
TPR=\frac{TP}{TP + FN}
TPR=TP+FNTP
F
P
R
=
F
P
F
P
+
T
N
FPR=\frac{FP}{FP + TN}
FPR=FP+TNFP
仔细看这两个公式,发现其实TPR就是TP除以TP所在的列,FPR就是FP除以FP所在的列,二者意义如下:
- TPR的意义是所有真实类别为1的样本中,预测类别为1的比例。
- FPR的意义是所有真实类别为0的样本中,预测类别为1的比例。
2. ROC曲线的绘制
假设我们有如下几个数据,其中p表示真实的正样本,n表示真实的负样本,得分为某一分类器将此样本预测为正样本的概率。我们将其按照得分由大到小排序,并将正负样本按照得分从小到大分别编号。

我们还需要一个概念:阈值。我们设定这个阈值,并将得分小于等于这个阈值的所有样本预测为负,大于这个阈值的样本预测为正。
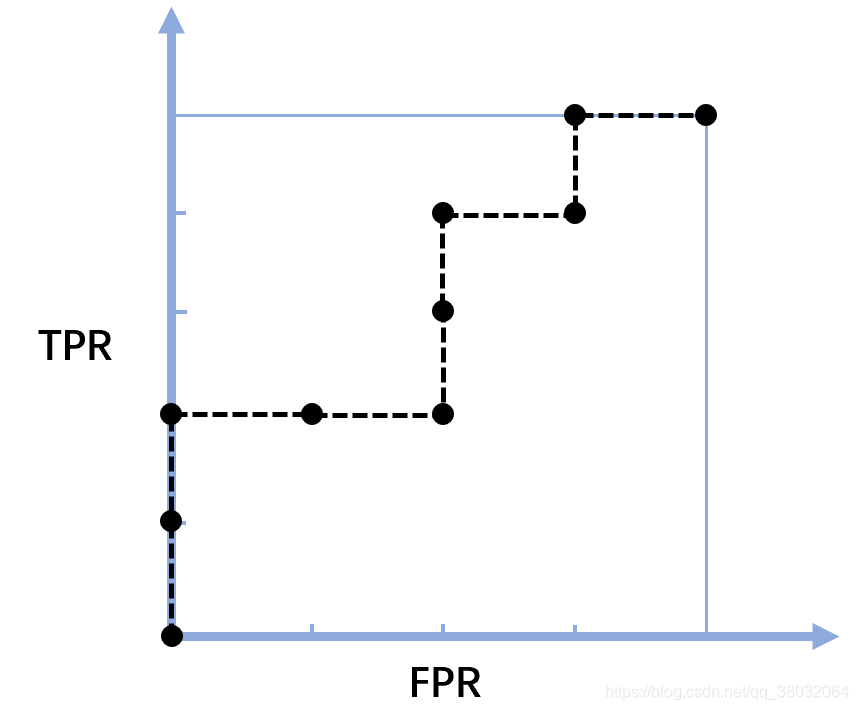
我们建立TPR和FPR的坐标。最开始,我们令这个阈值为0,则所有的样本都被预测为正,此时TPR和FPR都是1,则我们在图像上(1,1)这个地方描一个点。之后,我们按照所有样本的得分从小到大依次将其设置为阈值,即下一次阈值设置为0.2,此时只有样本n1被预测为负,其他样本均被预测为正,此时的TPR还是1,而FPR则变为了0.75,我们在(0.75,1)的地方描一个点。下一次阈值设置为0.35,此时样本p1和n1被预测为负,其余样本被预测为正,此时TPR变为0.8,FPR仍为0.75,我们在(0.75,0.8)的地方描一个点。以此类推,直到最后将所有样本都预测为负,画出ROC曲线。
3. AUC含义的理解
注:下面的说明不是严格的证明,只是帮助通俗理解。
那么,应该怎么将AUC的值与概率联系起来呢?首先,我们知道整个区域的面积是1。假设正样本的数量为
M
M
M,负样本数量为
N
N
N,并且在改变阈值的过程中,每当一个样本从被预测为正,变为被预测为负,则:
- 若此样本为正样本,则TPR将减小 1 M \frac{1}{M} M1
- 若此样本为负样本,则FPR将减小 1 N \frac{1}{N} N1
由于每让一个样本的预测结果发生变化,都画出了一条线段,因此让每个样本对应一条线段,负样本对应上方水平的线段,正样本对应右侧垂直的线段。于是可以将整个区域划分为
M
×
N
M\times N
M×N个小区域,每个区域可以由一条垂直的线段和一条水平的线段通过平移组成,那么这个区域就可以代表这两条线段对应的一个正样本和一个负样本组成的样本对,如下图。
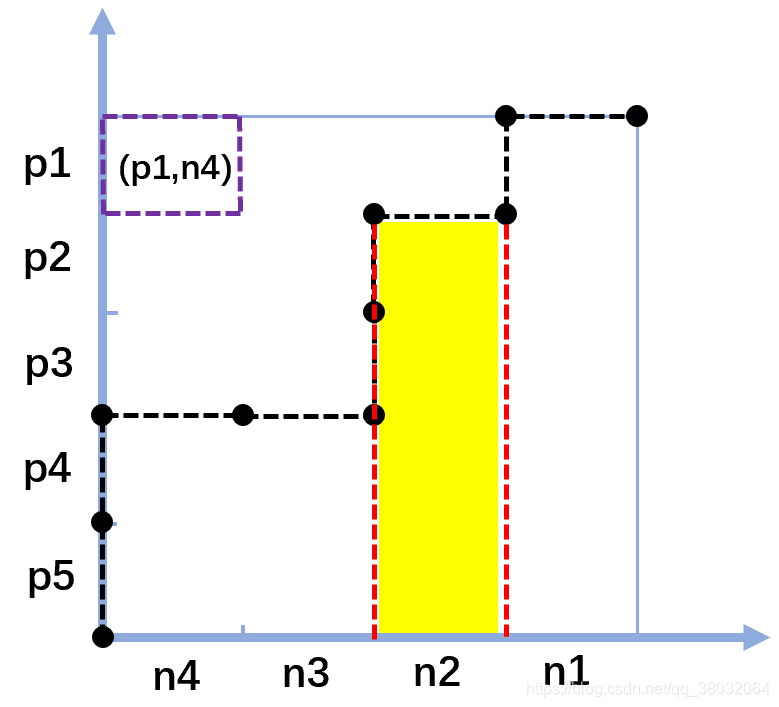
那么我们来理解一下图中黄色区域代表什么?这个黄色部分代表的其实是所有得分比n2的得分高的正样本与n2组成的样本对。也就是说黄色的部分由4个小块组成,每个小块是一个样本对,在这个样本对中,正样本的得分比负样本得分高。
所以,我们可以得到结论,ROC曲线下面的所有小块代表的样本对都是正样本得分比负样本得分高的样本对。而我们也可以证明ROC上面的所有小块代表的样本对都是正样本得分比负样本得分低的样本对。
现在,你能否理解AUC的含义了呢:随机给定一个正样本和一个负样本,用一个分类器进行分类和预测,该正样本的得分比该负样本的得分要大的概率。
而根据这一含义,我们也可以确定,AUC越大(越接近1),模型的分类效果越好。
另外,在知乎上看到了另一条比较好的回答,也在此记录一下:
对于二类分类问题,我们先画roc曲线,曲线的每一个点表示一个阈值,分类器给每个样本一个得分,得分大于阈值的我们认为是正样本,小于阈值的认为是负样本。那么纵坐标是正样本的召回率,横坐标是1-负样本的召回率。从原点开始画roc曲线,阈值从1开始递减,随着阈值的降低,正样本的召回率肯定是在增加的,而负样本的召回率在降低。如果正样本的召回率增加的速度大于负样本的召回率的下降,说明我们的分类器效果是不错的。roc曲线下面的面积就是auc。
作者:sean
链接:https://www.zhihu.com/question/39840928/answer/122890730
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

















 1523
1523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









