







C++基础
语言基础
1.const 常量 常指针 常引用(不能通过引用对目标变量的值进行修改,从而使引用的目标成为const)
2.引用 引用必须初始化
3.指针
常指针 指针的地址不能发生变化 (const在**右边).
指向常量的指针 指针所指的值不能发生变化 (const 在*左边)
4.static变量
5.面向对象
(1)函数重载
(2)运算符重载
成员函数重载 *this作为左操作数
友元函数重载 第一个形参作为左操作数 第二个形参作为右操作数
(3)友元函数(非成员函数) 关键字 friend
6.字符串(#include<.string>)
(1)定义与初始化
string s1;
string s2=s1;
string s3=“haha”;
string s4(10,‘c’);
(2)基础函数
empty,getline,size,s[n],连接操作(+)(必须有一侧是字符串对象另一侧可以使字符字面值/字符串字面值)
赋值,==,<,<=,>,>=
(3)while(getline(cin,str)) 跳出条件为eof或者读完
(4)string::npos 值为-1 结合算法库使用
(5)处理string中的字符 #inclde<.cctype>
具体函数不细说
7.数组
(1)初始化方式
静态初始化 int arr[10];
动态初始化 cin>>N;
int arr[N]=new int N;
动态初始化的意义就是可以由用户动态确定数组长度
显式初始化 int arr[3]={1,2,3};
8.容器
顺序容器 vector deque list forword_list array(c++11) string
关联容器 pair map set(集合)
容器适配器 stack(栈) priorityQueue(优先队列) queue(队列)
9.迭代器
操作标准库容器中的对象(因为只有少数可以使用下标获取元素)
(1)https://www.cnblogs.com/hdk1993/p/4419779.html
包括 end() begin() size()
每种容器所支持的迭代器类型
每种迭代器类型支持的操作等等
(2)迭代器失效
一些对容器的操作如删除元素或移动元素等会修改容器的内在状态,这会使得原本指向被移动元素的迭代器失效,也可能同时使其他迭代器失效
10.杂项
typedef 类型别名
#define INF INT_MAX (不用加分号)
默认初始化问题
(1)全局变量和static 变量会进行默认初始化
数字 字符转化
字符转数字 atoi, atof, atol, atoll 头文件 cstdlib 或者 char ch1=ch-‘0’;
数字转字符 如 char ch=6+‘0’;
C++ IO
1:键盘缓冲区 输入到黑框中的
2:输入流 [Enter]回车键键入后
cin: 从输入流中获取值 cin赋值时忽略空白字符
cin.ignore() 删除输入流当前指针中的一个字符
getline(cin,str1)从输入流中获取一行数据给对应的字符串 忽略结束字符(默认回车字符)
3.注意getline(cin,str1) 在cin后面会出现的问题 由于cin并不删除输入流中的回车字符 str1很可能出现空字符的问题
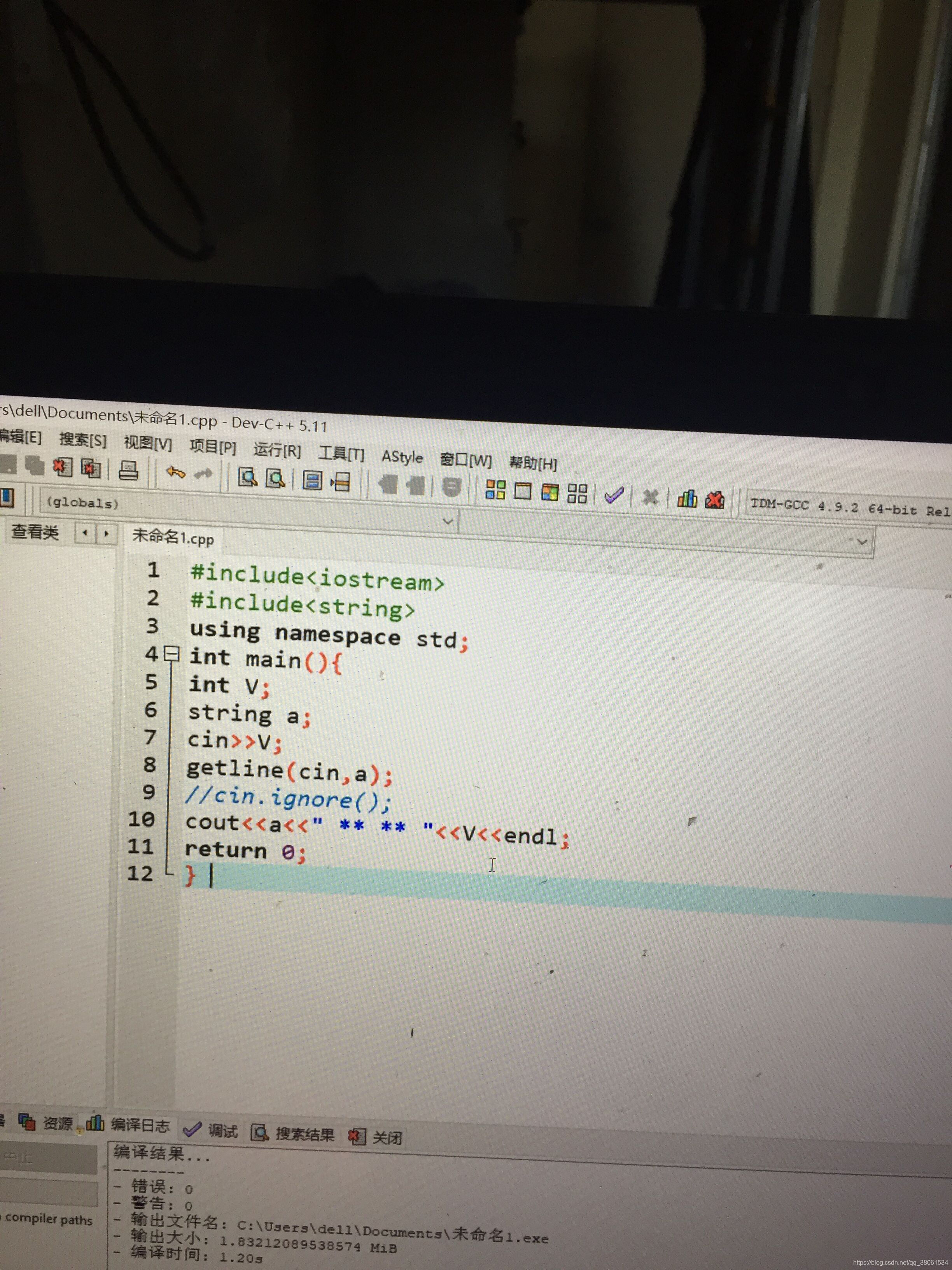
4.补充cin.get() 读取 任意字符 包括空白字符和文件结束符eof
注意: cin cin.get()不移动输入流指针 cin.ignore() getline(cin,str1) 移动一个
C++STL 与容器自身Api
顺序容器 Vector 支持随机访问迭代器
1:初始化
vector vec1(10,3)
vector vec2(20)
vector vec3(vec1)
vector vec4(vec1.begin(),vec1.end()-5)
c++11 列表初始化
2:重新分配值assgin
vec1.assign(arr,arr+3)
vec2.assign(temp.begin(),temp.end()) 半开区间[left,right)
vec3.assign(3,11) 重新分配3个11
3:增加值
无返回值 vec1.insert(vec1.begin(),3,0)
无返回值、vec2.insert(vec2.begin(),arr,arr+3)
返回值 为插入的第一个元素位置的迭代器 vec3.insert(vec3.begin,0)
push_back
4:删除元素 返回删除元素后一个元素的迭代器
vec1.erase(vec1.begin())
vec2.erase(vec2.begin(),vec2.begin()+2)
pop_back()
5:互换元素
vec1.swap(vec2)
6:注意点
注意删除或者添加元素后重新定位迭代器位置
it=list.erase(it);
顺序容器 List 支持双向迭代器
1:初始化
同vector
2:重新分配
同vector
3:添加元素
同vector
push_back
push_front
4:删除元素 erase返回删除后的下一个元素位置的迭代器 unique,remove,remove_if无返回值
(1)list1.erase(list1.begin())
(2)list2.earse(list2.begin(),list2.end())
(3)list1.unique()//或者加入一个一元谓词 是真正删除 无返回值
(4)list1.remove(val)
(5)list1.remove_if(UnPred)
(6) pop_back() pop_front()
5:倒置
list1.reverse()
6:互换
list1.swap(list2)
7:排序
list1.sort() 升序
list2.sort(comp)
8: 合并
list1.merge(list2)
合并后的结果在list1中
顺序容器string
1:额外的初始化与赋值
(1)string s(s2,pos) 从s2的pos位置到末尾位置
(2)string s(s2,pos,len) 从s2的pos位置拷贝len个字符
s2可以是字符数组也可以是字符串
(3)string s=s2.substr(pos) 指定位置到末尾
(4)string s=s2.substr(pos,len) 指定位置len个字符
2:改变string的顺序容器版本
assign,insert,erase 同vector
3:改变string的其他方法
(1) str.append(args) str.assgin(args)
args可以是 string
string,pos,len
n,c
b,e迭代器范围
(2)string.replace(pos,len,args) 下标
args可以是 string
string pos len
n,c
(3)str.replace(b,e,args) 迭代器
args可以是 string
n,c
b2,e2
(4)s.erase(pos,len) 下标
(5)s.insert(pos,len)下标
args可以是:string
string,pos,len
n,c
4:字符串搜索
find(c,pos)
find_first_of(c,pos)
find_first_not_of(c,pos)
pos不写默认为0位置;
注:find区分大小写,std::search不区分大小写
5:字符串分割(利用字符串流与getline函数)
string str,temp;
getline(cin,str);
istringstream s(str);
while(getline(s,temp,‘0’)){
cout<<temp<<endl;
}
注意引用头文件sstream
6.getline函数
关联容器 map(不用算法库算法 用自身的api即可)
1.pair类型 头文件<.utility> pair first(键) pair second(值)
2.value_type,key_type,mapped_type
对应 pair<const string,int>
string
int
3.默认升序
4.添加元素
(1)
map<string,int> mymap;
mymap.insert(pair<string,int>(“Hello”,1));
返回值: pair<map<string,int>::iterator,bool>
若原来map中含有指定的key值 迭代器指向这个元素位置 bool值为false
若原map中不含指定的key值 迭代器
(2) mymap[“Hello”]=2;
5.迭代器不支持算数运算
6.删除元素
void erase(迭代器p) 返回p的后一个位置的迭代器
void erase(beg,end)返回end
size_type erase(key)//返回删除元素的个数
循环删除指定元素的时候 要先存it的位置再让it++,再删除it位置的元素
删除一定要关注迭代器是否会失效的问题
7.下标操作
insert如果map已经有了此关键字则什么都不做
下标则会更改值
8.find与count
size_type count(key) 计数的数目
iterator find(key) 存在返回指向元素的迭代器 不存在返回尾后迭代器
9:empty()
10:clear()
11:自定义关联容器的顺序
重载<运算符
仿函数
<.functional>中的less<.T>与greater<.T>
12.应用 单词计数程序
#include<utility>
#include<iostream>
#include<algorithm>
#include<vector>
#include<map>
using namespace std;
int main(){
map<string,int> mymap;
vector<string> strs={"hello ","my","dick","my","dick","dick"};
for(int i=0;i<strs.size();i++){
auto it=mymap.insert(pair<string,int>(strs[i],1));
if(it.second==false){
++mymap[strs[i]];
}
}
auto it=mymap.begin();
for(;it!=mymap.end();it++){
cout<<it->first<<" "<<it->second<<endl;
}
return 0;
}
容器适配器 优先队列(堆)
1:empty()
2:pop()
3:push()
4:size()
5:top()
底层用vector表示一个二叉堆 只有在pop与push时才会调整堆
上滤 下滤操作
优先队列自定义优先级 方法与关联容器的自定义排序3种方法正好相反
容器适配器 stack
1:empty()
2:size()
3:pop()
4:top()
5:push()
容器适配器 队列
1:back()
2:empty()
3:size()
4:front()
5:pop()
6:push()
C++算法库(#include<.algorithm>)
**注意:**其中unaryPred为一元谓词 comp为二元谓词
1:查找指定的值 返回值为第一个等于val的迭代器
find(beg,end,val)
find_if(beg,end,unaryPred)
2:计数
count(beg,end,val)
count_if(beg,end,unaryPred)
3:替换元素 没有返回值
replace(beg,end,oldval,newval)
replace_if(beg,end,unaryPred,newval)
4.查找子序列
search(beg1,end1,beg2,end2) 返回第二范围在第一个范围中第一次出现位置的迭代器
find_first_of(beg1,end1,beg2,end2) 查找第二个范围中任意元素第一次在第一范围中出现的位置 的迭代器
5.排列组合函数
全排列升序next_permutation(beg,end)
全排列降序 prev_permutation(beg,end)
do{}while(排列组合函数名(beg,end))
6.排序
sort( beg,end) 升序
sort(beg,end,comp)(“>“ 降序)
7.翻转
reverse(beg,end) 没有返回值
8.重排 返回最后一个没有remove(重排)的元素的后一个位置的迭代器 没找到就返回尾后迭代器
remove(beg,end,val)
remove_if(beg,end,unaryPred)
注意与容器自身api 的 earse的区别
unique(beg,end)
配合earse才真正删除元素
注意排序与不排序的区别
9.最值 返回指向最值元素位置的迭代器
min_element(beg,end)
max_element(beg,end)
10.有序序列的集合运算 返回结果集的尾后迭代器
(1)判断B是否是A的子集 bool
includes(beg1,end1,beg2,end2)
(2)并集 (新的容器接收结果)
set_union(beg,end,beg2,end2,dest.begin())
(3)交集 (新的容器接收结果)
set_intersection(beg,end,beg2,end2,dest.begin())
(4)差集 (在A不在B的集合)(新的容器接收结果)
set_difference(beg,end,beg2,end2,dest.begin())
(5)对称集(并集-交集)(新的容器接收结果)
基础数据结构
算法基础
1:时间复杂度
一般只研究最坏的时间复杂度 大O算法来衡量
常用数据结构的操作的时间复杂度
1>数组
2>链表
3>优先队列
建堆的时间复杂度
4>
5>
6>
7>
2:空间复杂度
顺序表
数组与vector
随机存取的效率高
栈 stack
队列
queue单向队列
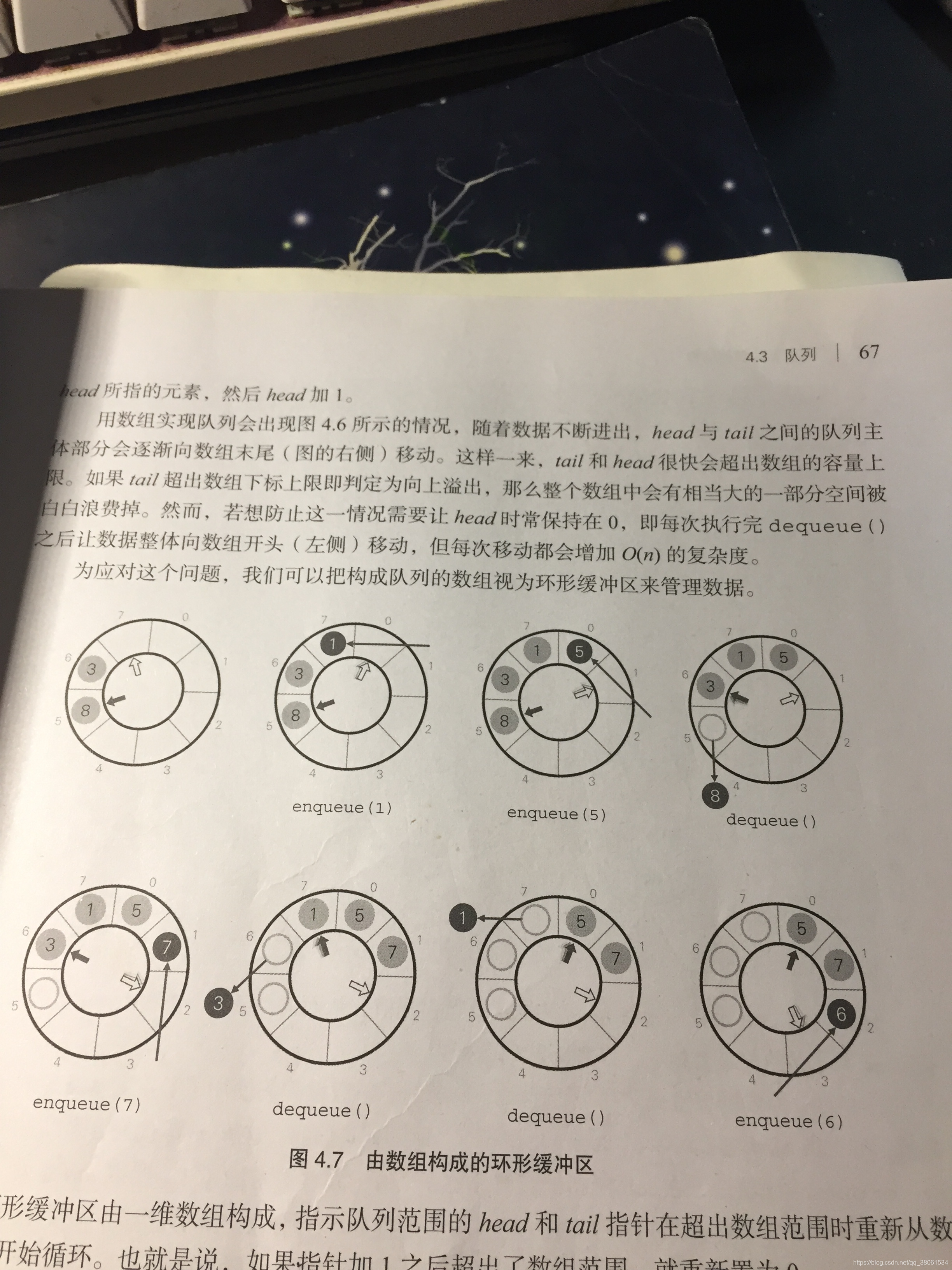
队列底层api实现:(用数组实现版本)
注意点:
1:head=tail表示空
2:head=(tail+1)%M 表示队列满了
3.由于是循环队列注意%M
#include<iostream>
#define MAX 8
using namespace std;
int Q[MAX];
int head,tail;
void init(){
head=tail=0;
}
bool isFull(){
return head==(tail+1)%MAX;
}
bool isEmpty(){
return head==tail;
}
void push(int i){
if(isFull()){
cout<<"wrong operation!"<<endl;
}
else{
Q[tail]=i;
if((tail+1)==MAX){
tail=0;
}
else{
tail++;
}
}
}
void pop(){
if(isEmpty()){
cout<<"wrong operation!"<<endl;
}
else{
if((head+1)==MAX){
head=0;
}
else{
head++;
}
}
}
int main()
{
init();
for(int i=0;i<6;i++){
push(i);
}
push(10);
//push(11);
for(int i=0;i<6;i++){
pop();
}
pop();
return 0;
}
链表
双向链表List
单项链表forword_list
循环双向链表底层api实现:
#include<iostream>
using namespace std;
class Node{
public:
Node* prev;
Node* next;
int key;
};
Node* head;
void init(){
head=new Node();
head->prev=NULL;
head->next=NULL;
}
void insert(int x){
Node* node1=new Node();
node1->key=x;
if(head->prev==NULL){
head->prev=node1;
head->next=node1;
node1->prev=head;
node1->next=head;
}
else{
node1->prev=head;
node1->next=head->next;
head->next->prev=node1;
head->next=node1;
}
}
Node * find(int x){
Node * temp=head->next;
while(temp!=head){
if(temp->key==x){
return temp;
}
temp=temp->next;
}
}
void delete(int x){
Node * temp=find(x);
}
int main(){
return 0;
}
树
0:几种结构的汇总{
(1)集合结构
(2)线性结构
(3)树形结构
(4)图结构
}
1:普通树
(1)容易混的概念
树的度:结点度的最大值
结点的深度:根到Ni的路经长
结点的高度:Ni到一个树叶的最长路径
树的深度(树的高度):结点中深度最大的;
(2)普通树的存储
1>孩子兄弟表示法 **
2>双亲表示法 **
struct Node{int p;} Node T[MAX_SIZE]
3>孩子表示法
struct Node{
int p;
vector vec;
}
Node T[MAX_SIZE]
注:p表示度,vec存储的孩子编号
4>图表示树
(3)树的性质
度总和+1=总节点数
2:二叉树
(1)二叉树的存储
二叉树的性质:
叶子节点个数等于度为2的节点个数+1
(2)几种特殊的二叉树
完全二叉树( 完全二叉树从根结点到倒数第二层满足完美二叉树,最后一层可以不完全填充,其叶子结点都靠左对齐)
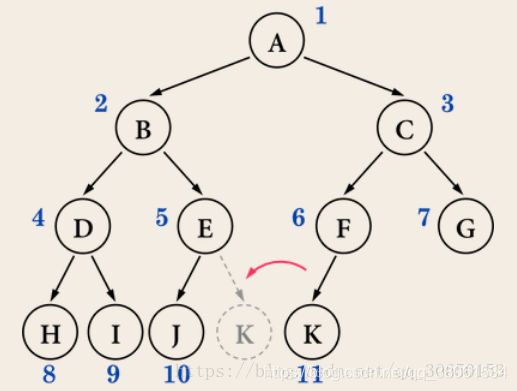
完美二叉树 (树是满的,还是二叉的 )
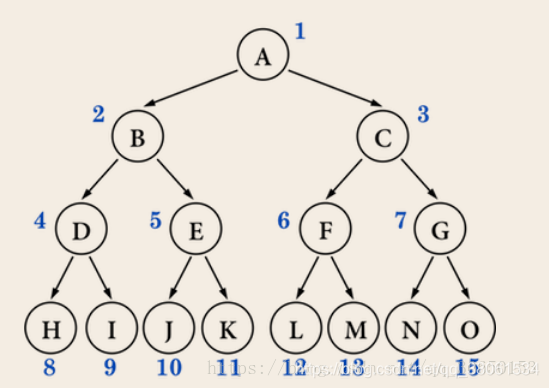
完满二叉树 (所有非叶子结点的度都是2 )

注意:
完全二叉树的性质:
1>每个节点存储自身的键值
2>对二叉树自上而下 按层次编号1~N
那么有如下的特点:
在编号范围内,i/2 为父节点
2i 为左孩子
2i+1 为右孩子
(3)二叉树的遍历
#include<iostream>
using namespace std;
class Node{
public:
int l,r;
Node(){
this->l=-1;
this->r=-1;
}
};
Node T[7];
void prev(int root){
if(root==-1) return;
cout<<root<<" ";
prev(T[root].l);
prev(T[root].r);
}
void mid(int root){
if(root==-1) return;
mid(T[root].l);
cout<<root<<" ";
mid(T[root].r);
}
void next(int root){
if(root==-1) return;
next(T[root].l);
next(T[root].r);
cout<<root<<" ";
}
int main(){
T[1].l=2;
T[1].r=5;
T[2].l=3;
T[2].r=4;
T[4].r=6;
prev(1);
cout<<endl;
mid(1);
cout<<endl;
next(1);
cout<<endl;
return 0;
}
注意:给出三种遍历次序后可以得到的信息如下:
1>先序或者后序可以得到根节点是哪一个
2>中序遍历可以得到根的左半部分节点有哪些 右半部分有哪些
3>给出遍历的次序可以确定一棵二叉树的样子
(4)二叉树与树与森林的转化(了解)
https://blog.csdn.net/linraise/article/details/11745559
(5)二叉搜索树
特点:
根比左孩子大,比右孩子小
并且每一个子树都是一个二叉搜索树
表示一棵二叉搜索树:
struct Node{
Node* left,*parent,*right;
};
1>在二叉搜索树中插入一个值
2>在二叉搜索树中查找一个值
3>中序遍历(从小到大的序列) 前序遍历
4>搜索一个节点的后序节点(比当前节点大且值相差最小的一个节点)
总结来说如果存在右子树 后序节点调用getMinmum即可
如果不存在 那么就向上查询第一个存在左子节点的父节点即为所求;
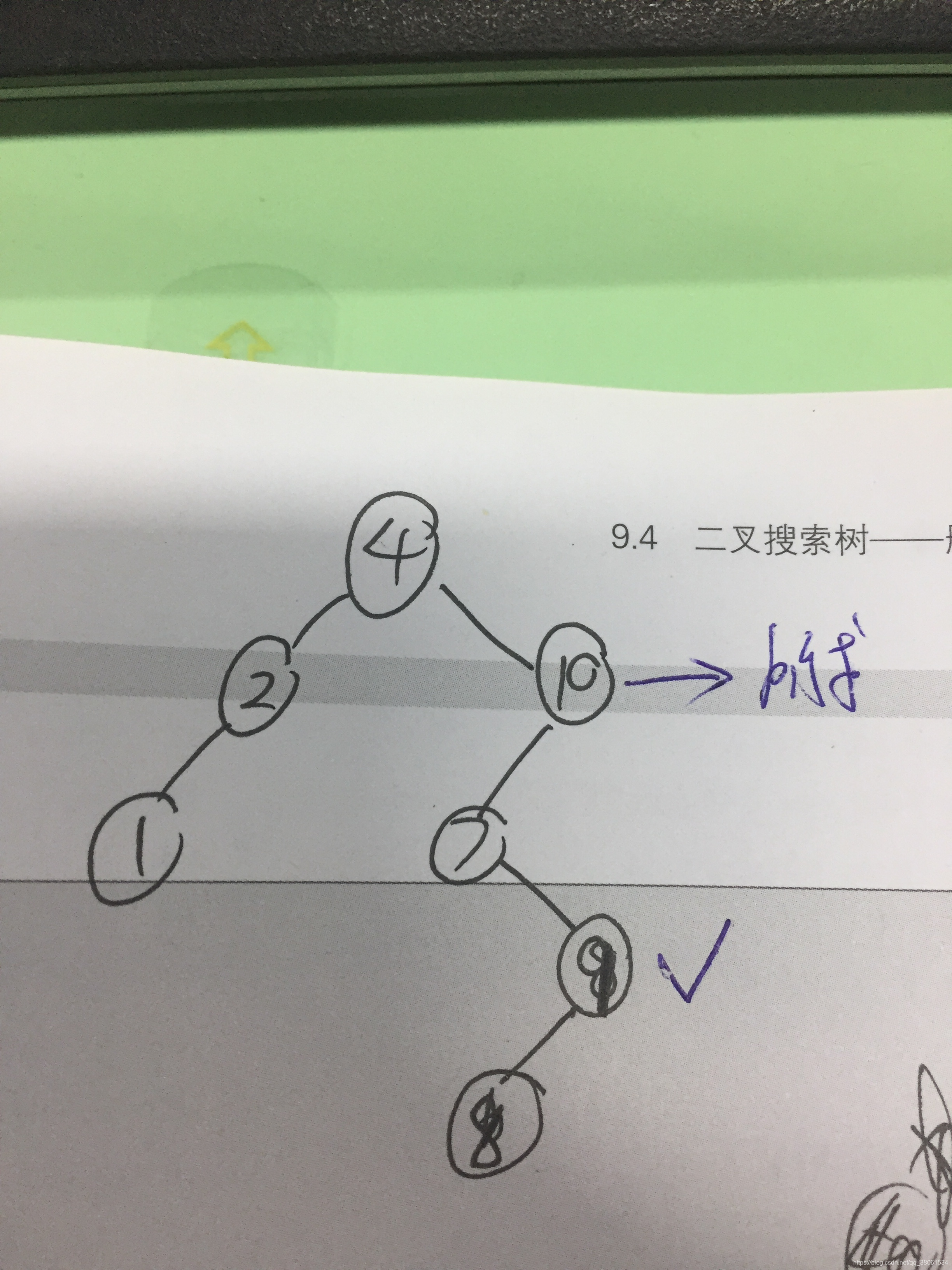
getSuccessor(x)
if x.right!=NULL
return getMinimum(x.right)
y=x.parent;
//右子树不为空时就要去父节点的右孩子去找
y=x.parent;
//如果存在父节点并且此节点就是父节点的右节点时 再往
while y!=NULL && y.right==x
x=y;
y=y.parent;
return y
5>求二叉搜索树的最小值
6>删除一个节点
https://blog.csdn.net/isea533/article/details/80345507
没有孩子时:
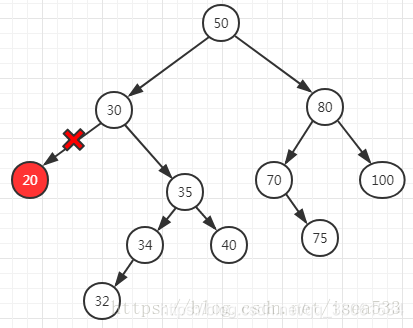
有一个孩子时
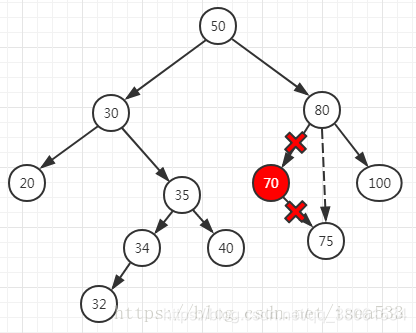
有两个孩子时

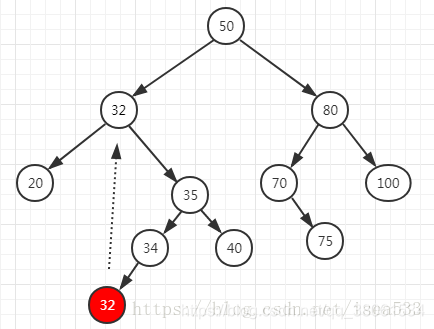
(6)几种高级二叉树
1>红黑树
2>哈弗曼树
3>b树与b- b+树
3.二叉堆
完美二叉树按照从上到下 按层次编号1~N
这样的对应关系即可以成为二叉堆:
即有如下性质:
在编号范围内,i/2 为父节点
2i 为左孩子
2i+1 为右孩子
两种特殊二叉堆:
1>大顶堆(根比孩子大或等于)
普通二叉堆应用如下算法:
A[N]//存储1~N节点的键值
maxHeapify(A,i)
l=left(i)
r=right(i)
获取l,r,i中的拥有最大值的节点temp
swap(A[temp],A[i])
maxHeapify(A,temp)// 递归调用
buildMaxHeap(A){
for i= N/2 downto 1
maxHeapify(A,i)
}
总结起来就是这样:
让下标最大的非叶节点s(N/2)自底向上(到1)的使用maxHeapify(A,i)即可
这样可以保证每次maxHeapify(A,i)时 i的左子树和右子树必然是最大堆(局部满足最大堆)
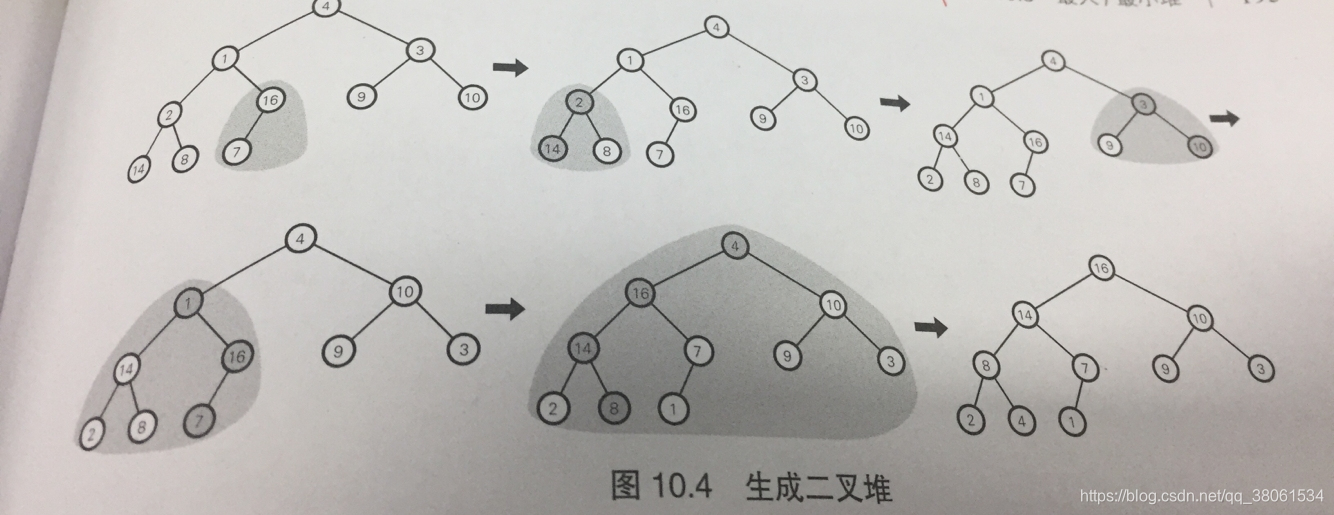
2>小顶堆(根比孩子小或等于)
4.优先级队列
1>最大优先级队列(最大堆实现)
(1)插入元素
(2)更改元素值
值改大了要上滤
值改小了调用maxHeapify
(3)取值并删除对应的元素
调换头与尾的位置 并 maxHeapify
#include<iostream>
#include<algorithm>
#define MAX 1<<20
using namespace std;
int N=0;
vector<int> A(100,0);
void maxHeapify(vector<int> &A,int i){
int l=2*i;
int r=2*i+1;
if(l>N) return;
int max_num=0;
if(A[i]<A[l]) {
max_num=l;
}
else{
max_num=i;
}
if(A[max_num]<A[r]){
max_num=r;
}
if(max_num==i) return;
swap(A[max_num],A[i]);
maxHeapify(A,max_num);
}
void increaseValue(vector<int> &A,int i,int key){
bool flag=true;
if(key<=A[i]) flag=false;
A[i]=key;
if(flag){
while((i/2>0)&&(A[i]>A[i/2]))
{
swap(A[i],A[i/2]);
i=i/2;
}
}
else{
maxHeapify(A,i);
}
}
void insertMaxHeap(vector<int> &A,int key){
A[++N]=-MAX;
increaseValue(A,N,key);
}
void print(){
for(int i=1;i<=N;i++){
cout<<A[i]<<" ";
}
}
int pop(vector<int> &A){
int max=A[1];
A[1]=A[N];
N--;
maxHeapify(A,1);
return max;
}
int main(){
insertMaxHeap(A,5);
insertMaxHeap(A,7);
insertMaxHeap(A,3);
insertMaxHeap(A,2);
insertMaxHeap(A,6);
insertMaxHeap(A,8);
print();
cout<<endl;
increaseValue(A,1,1);
print();
cout<<endl;
cout<<"p1:"<<pop(A)<<endl;
print();
cout<<"p2:"<<pop(A)<<endl;
return 0;
}
2>最小优先级队列
并查集
图
1.认识图
1>4种图:
有向图,无向图,加权有向图,加权无向图
2>图记作:G(V,E) |V|标识定点数 |E|代表边数
3>有向无环图记作DAG
4>连通图:任意两个顶点都有路径可以走
5>子图:边属于原图边集合,顶点属于原图点集合
6>基本算法
dfs,bfs
2.图的存储
1>邻接矩阵 int G[SIZE].[SIZE]
2>邻接表 vector G[SIZE]
3>
3.dfs(栈)
4.bfs(队列)
基础算法
排序算法
下面这个链接的描述十分清晰:
https://www.cnblogs.com/onepixel/articles/7674659.html
(1)














 100
100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









