







10分钟速成数据结构
1基本概念
(1)数据结构是算法的基石,把算法比喻成舞者,数据结构就是舞者的彩带。
(2)时间复杂度:执行算法的时间成本(谁可以在更短的时间完成一件事),一般有大O表示法:O(n),完整的表达为T(n)=O(n)。常见的时间复杂度按照从低到高的顺序,包括O(1)、O(logn)、O(n)、 O(nlogn)、O(n2)等(为了便于记忆,可参照下图数学函数曲线,O(nlogn)斜率较O(logn)、O(n)大)。

(3)空间复杂度:执行算法的空间成本(谁可以使用最小的物理内存空间完成一件事)一般也是用大O表示法:O(f(n)),完整表达:S(n)=O(f(n)),f(n)为算法所占存储空间的函数。常见的空间复杂度按照从低到高的顺序,包括O(1)、O(n)、O(n2)等。其中递归算法的空间复杂度和递归深度成正比O(n)。
如何推导时间复杂度:
- 如果运行时间是常数,则常用O(1)表示 例:T(n)=8 记为T(n)=O(1)
- 只保留函数中的最高项,例:T(n)=8n 记为T(n)=O(n)
- 只保留最高项,舍去最高项的后面项,例:T(n)=2n^2 + 2n
记为T(n)=O(n^2)
一些经验性的结论:
- 一个顺序结构的代码,时间复杂度是O(1)。
- 二分查找,或者更通用的说是采用分而治之的方法,时间复杂度通常都是O(logn)。
- 一个简答的for循环,时间复杂度是O(n)。
- 两个顺序执行的for循环(即两个独立的for循环),时间复杂度是O(n)+O(n)=O(2n),即O(n)。
- 两个嵌套的for循环,时间复杂度是O(n^2)。
2数组
数组就是一段连续的空间结构

3链表
如果说数组是正规军(连续),那么链表就是“地下党”,地下党是单线联系,只有找到第一个人,才能接着找下一个人

单线链表:

双向链表:

4数组VS链表

总结:数组对查找和更新支持更加友好,链表对插入和删除更加友好
5栈
栈(stack)是一种线性数据结构,它就像一个上图所示的放入乒乓球的圆筒容器,栈中的元素只能先入后出(First In Last Out,简称FILO)。最早进入的元素存放的位置叫作栈底(bottom),最后进入的元素存放的位置叫作栈顶(top)。栈涉及的操作最多的就是出栈(pop)和入栈(push)。

6队列
队列(queue)是一种线性数据结构,它的特征和行驶车辆的单行隧道很相似。不同于栈的先入后出,队列中的元素只能先入先出(First In First Out,简称FIFO)。队列的出口端叫作队头(front),队列的入口端叫作队尾(rear)。与栈类似,队列这种数据结构既可以用数组来实现,也可以用链表来实现。用数组实现时,为了入队操作的方便,把队尾位置规定为最后入队元素的下一个位置。

入队和出队有一点区别:
(1)入队

(2)出队
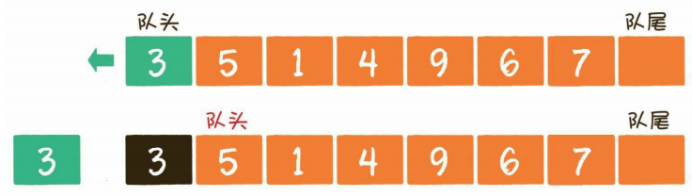
如果像这样不断出队,队头左边的空间失去作用,那队列的容量岂不是越来越小了?
(3)循环队列
用数组实现的队列可 以采用循环队列的方式来维持队列容量的恒定。
我们可以把数组的首部放入队尾元素,直到(队尾下标+1)%队列长度=队头下标,即认为队列已满,这就是典型的循环队列。

7栈和队列的应用
 队列:
队列:

(1)双端队列

(2)优先级队列
谁的优先级高就谁先出队

8散列表
散列表也叫作哈希表(hash table),这种数据结构提供了键(Key)和值(Value)的映射关系。只要给出一个Key,就可以高效查找到它所匹配的Value,时间复杂度接近于O(1)。
散列表的底层也是通过数组来实现,只是数据是基于下标的,要想查找快,就需要使用数组这样的结构,但是若需要根据字符串key来查找,而不是索引下标,就需要一个中转站来把key转换成内存中对应的下标,进而找到存储的value,这个中转站就是哈希函数。

(1)hash冲突
以Java中的hashMap为例,每一个Java中的对象都有hashcode(int型)作为地址,需要插入元素时,put方法调用,其计算的方法是如下图的方法计算数组下标,hash中优化了此计算方式,采用移位运算来改善。

(2)解决hash冲突
解决哈希冲突的方法主要有两种,一种是开放寻址法,一种是链表法。
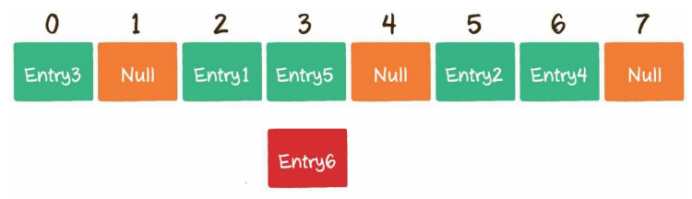
开放寻址法的原理很简单,当一个Key通过哈希函数获得对应的数组下标已被占用时,我们可以“另谋高就”,寻找下一个空档位置。如下图,若entry6的hashcode映射的下标为3,3已经有元素了,就继续找4,4为null则放入。 在Java中ThreadLocal中就是使用的开放寻址法。
链表法应用于HashMap中的,当某个元素的hashcode映射的下标与内存的中数组下标有冲突(原有下标已有内容),链表法就是在冲突的下标下,挂载一个链表结构的entry,因此HashMap中每一个entry除了是键值对,也有保存下一个entry的信息。

Java8的版本实现教之前版本有很大的区别,除了在冲突索引数组后加链表,超过8个,则使用红黑树来继续存储该冲突的entry。HashMap在扩容的时候,需要重新计算hash映射的下标值以及重新创建hash数组(大小为原来的两倍),负载因子(加载因子)为0.75。
综上:散列表是数组与链表的结合。
9树
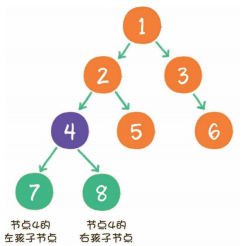
除了上面的逻辑关系的线性结构,还有逻辑关系的非线性结构:树(一对多的关系)我们需要理清这些概念:根节点、子树、父节点、(孩)子节点(左子节点,右子节点)、树的高(深)度、兄弟节点、叶子节点。
 叶子节点就是没有孩子节点的节点。
叶子节点就是没有孩子节点的节点。
(1)二叉树(binary tree)
二叉树(binary tree)是树的一种特殊形式。二叉,顾名思义,这种树的每个节点最多有2个孩子节点。注意,这里是最多有2个,也可能只有1个,或者没有孩子节点。
1)满二叉树
一个二叉树的所有非叶子节点都存在左右孩子,并且所有叶子节点都在同一层级上,那么这个树就是满二叉树。即二叉树所有分支都是满的,叫满二叉树。

2)完全二叉树
对一个有n个节点的二叉树,按层级顺序编号,则所有节点的编号为从1到n。如果这个树所有节点和同样深度的满二叉树的编号为从1到n的节点位置相同,则这个二叉树为完全二叉树。
简单点说就是在下图中,二叉树编号从1到12的12个节点,和前面满二叉树编号从1到12的节点位置完全对应。因此这个树是完全二叉树。

完全二叉树的条件没有满二叉树那么苛刻:满二叉树要求所有分支都是满的;而完全二叉树只需保证最后一个节点之前的节点都齐全即可。
(2)二叉树的应用
二叉树是属于逻辑结构中的非线性结构,他可以基于物理结构(数组,链表)来具体表示:可以使用链式方式表示:每个节点包含三部分:1具体的数据data,2指向左节点的指针,3指向右节点的指针。

用数组表示

(补充:按层级顺序放的意思是指把上图按4层划分,第一层:1,第二层:2,3,第三层:4,5,空,6,第六层:空,8,然后依次按层级顺序摆放到数组中)使用数组存储时,会按照层级顺序把二叉树的节点放到数组中对应的位置上。如果某一个节点的左孩子或右孩子空缺,则数组的相应位置也空出来。为什么这样设计呢?因为这样可以更方便地在数组中定位二叉树的孩子节点和父节点。)
假设一个父节点的下标是parent,那么它的左孩子节点下标就是2×parent + 1;右孩子节点下标就是2×parent + 2。反过来,假设一个左孩子节点的下标是leftChild,那么它的父节点下标就是 (leftChild-1)/ 2。 显然我们用数组表示一个稀疏的二叉树是比较浪费空间的,应该适用于二叉堆。
二叉查找树(二叉排序树),二叉树包含许多特殊的形式,每一种形式都有自己的作用,但是其最主要的应用还在于进行查找操作和维持相对顺序这两个方面,查询时间复杂度为O(logn)。
二叉查找树在二叉树的基础上增加了以下几个条件。
(1)如果左子树不为空,则左子树上所有节点的值均小于根节点的值
(2)如果右子树不为空,则右子树上所有节点的值均大于根节点的值
(3)左、右子树也都是二叉查找树

这样的二叉查找树会出现一个问题?下面请试着在二叉查找树中依次插入9、8、7、6、5、4,看看会出现什么结果。

这样的二叉查找树会极大的增加查找时间,导致某个节点太“长”,这就涉及二叉树的自平衡了。二叉树自平衡的方式有多种,如红黑树、AVL树、树堆等。
(3)二叉树的遍历
二叉树遍历从节点位置划分为:前序遍历、中序遍历、后序遍历、层序遍历
从宏观的角度看划分为:深度遍历(前序遍历、中序遍历、后序遍历),广度遍历(层序遍历)
1)深度优先遍历:
所谓深度优先,顾名思义,就是偏向于纵深,“一头扎到底”的访问方式。可能这种说法有些抽象,看下图:(黑色数字代表输出顺序)

2)广度优先遍历:
如果说深度优先遍历是在一个方向上“一头扎到底”,那么广度优先遍历则恰恰相反:先在各个方向上各走出1步,再在各个方向上走出第2步、第3步……一直到各个方向全部走。

关于深度优先遍历与广度优先遍历的具体实现,如有兴趣可以查看:数据结构与算法|深度&广度优先遍历算法简单示例
(4)二叉堆
二叉堆就是完全二叉树,他分为最大堆和最小堆,最大堆:他的任意父节点都大于或等于左右子节点,最小堆:他的任意父节点都小于等于他的左右节点。

二叉堆的根节点叫作堆顶。最大堆和最小堆的特点决定了:最大堆的堆顶是整个堆中的最大元素;最小堆的堆顶是整个堆中的最小元素。
推荐学习的数据结构网站:(各种算法数据演示,快速帮助理解)
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
参考资料
- 魏梦舒版《漫画算法》
- 苏勇版 拉勾《300分钟搞定算法面试》















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









