






1、InnoDB存储引擎为什么会选择B+Tree作为索引
我们建立索引是为了啥?当然是为了能够快速匹配数据,这个时候k,v结构就特别符合我们的需求,当把id作为k,整行数据作为value,这样你查询的时候可以最快的速度取出数据。
什么样的数据结果能支持k-v存储呢?hash表和树(二叉树、红黑树、B树、B+树等)
当然除了键值对的形式外我们还需要让整个索引有序,这样可以方便查询范围(例如where id>1)。
既然我们确定了数据格式,下一步就需要找到合适的数据结构。Hash有个致命的缺点就是浪费内存。就像Figure 2这种极端情况下会额外浪费很多内存。而且Hash表中数据是无序的,更适用于等值查询,但是在实际工作环境中范围查找的数据更多,所以hash就不太适合。
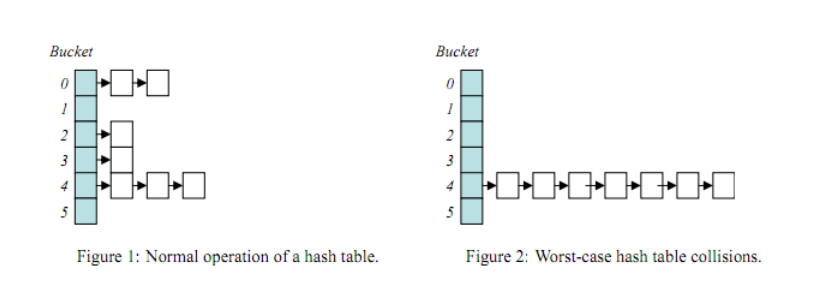
图片来源于(https://www.cnblogs.com/s-b-b/p/6208565.html)
接下来我们考虑采用树状存储结构,但是树又分很多种我们应该用哪个呢?
首先是考虑采用二叉树还是多叉树?
答案是采用多叉树!为什么呢?
如果采用二叉树,那么当数据量越大的时候,这棵树就越深,树越深IO的次数就会越多(提高系统效率的两种方式:1、减少IO次数 2、减少IO量)
根据上述分析得出我们需要得出结论:我们需要找一个有多个分支且有序的多叉有序树。
此时发现B树很符合我们的要求
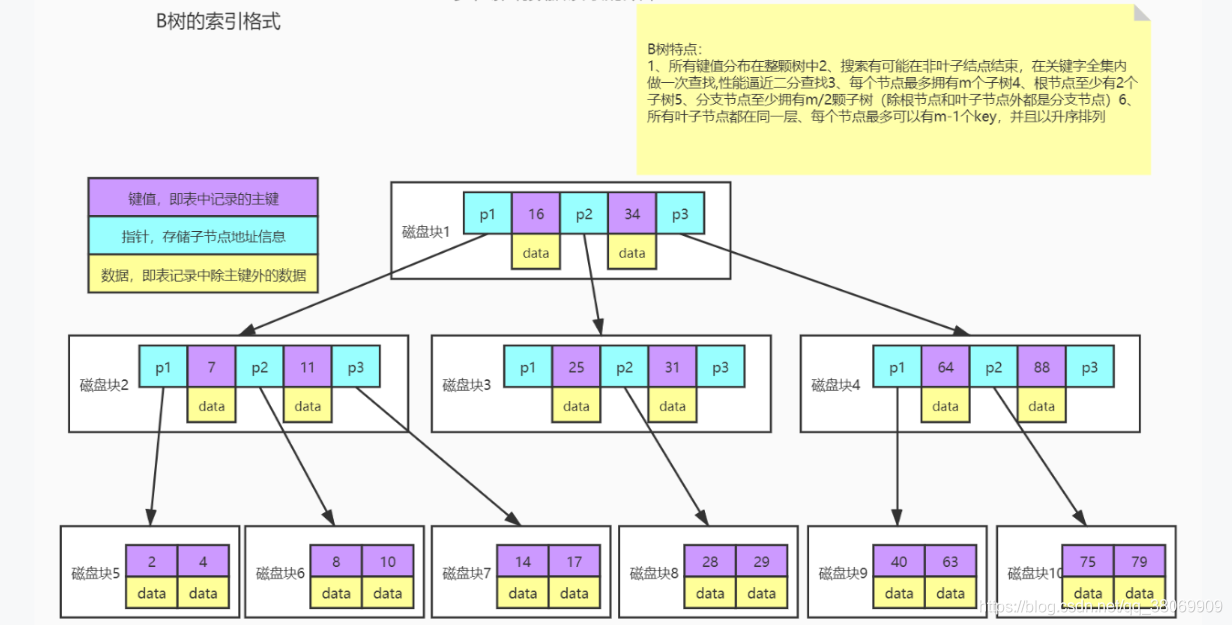
B树有两个缺点:
1、每个节点都有key,同事也包含data,每个页的存储空间是有限的,如果data比较大的话会导致每个节点存储的key数量变小
2、当存储的数据量很大的时候会导致深度较大,增大查询时磁盘IO次数,进而影响查询性能
为了解决这个data太大导致树的深度变深问题,我们找到了B+树的数据结构
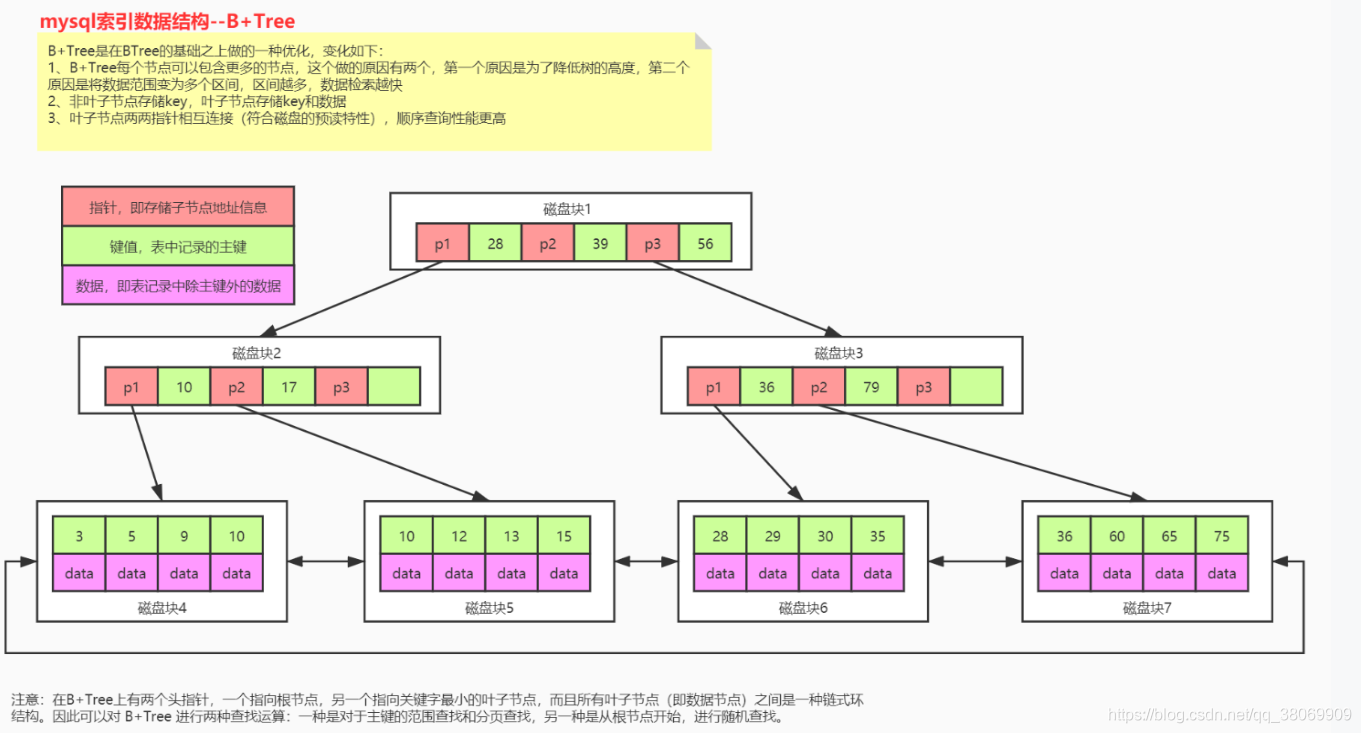
B+树缺点:有数据冗余
B+树很好的解决了B树出现的问题,因为B+树的所有数据都是存储在根节点上,这样第二层就能存更多的数据了。














 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









