







 本文详细介绍了如何在百度智能云创建语音识别应用,获取AccessToken,并使用Post方法上传音频文件,获得语言识别结果。从创建应用到获取认证,再到具体代码实现,全程实战演示。
本文详细介绍了如何在百度智能云创建语音识别应用,获取AccessToken,并使用Post方法上传音频文件,获得语言识别结果。从创建应用到获取认证,再到具体代码实现,全程实战演示。
Python开发之路(2)— 使用百度API实现语音识别
一、在百度智能云创建语音识别应用
打开百度智能云:https://cloud.baidu.com/
登录控制台,选择语音技术:
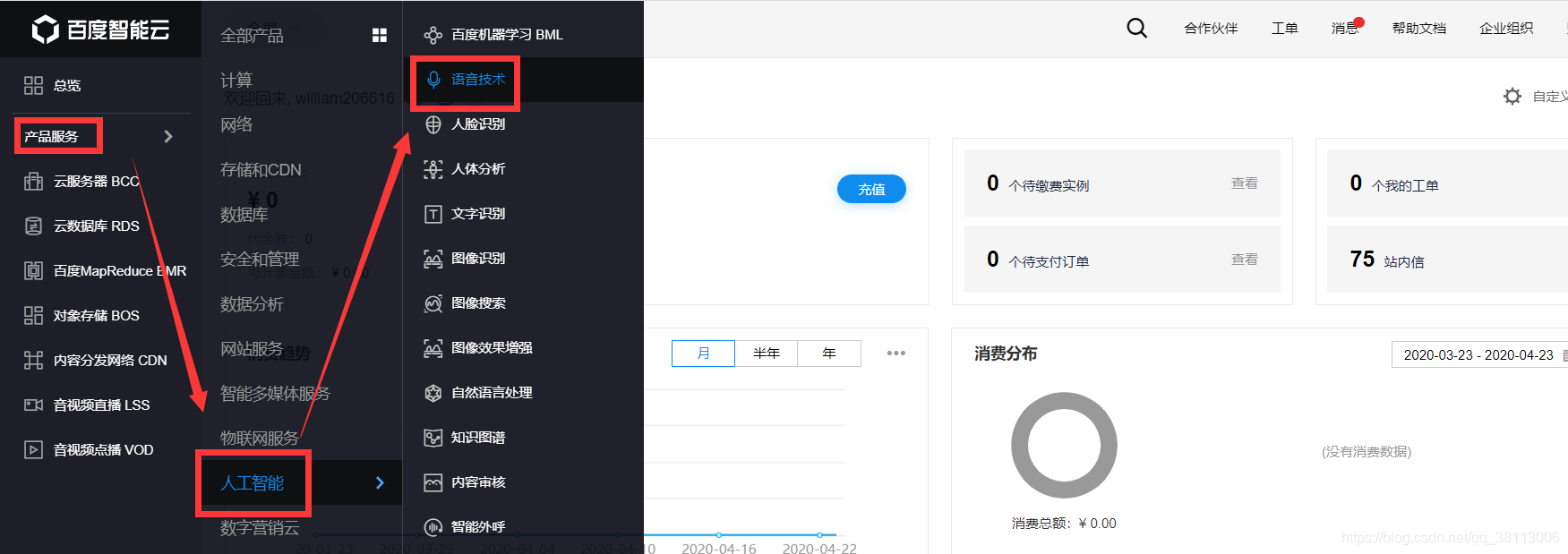
然后点击创建应用
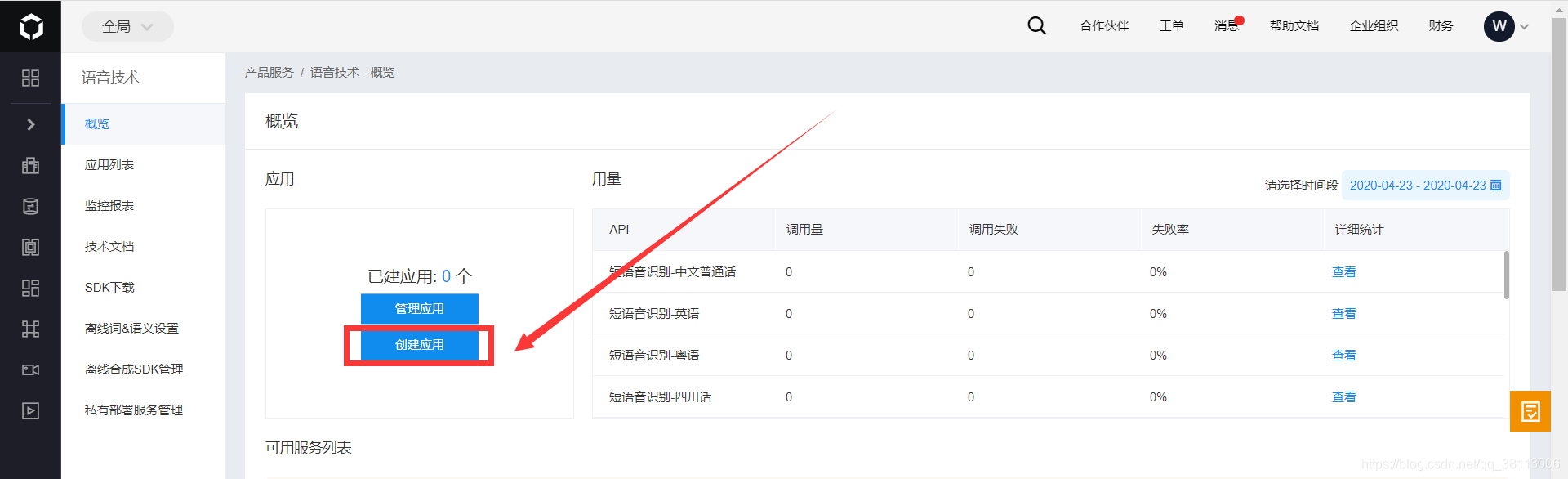
然后输入应用名称名称、选择应用类型,接口选择默认即可,输入描述,然后点击立即创建即可
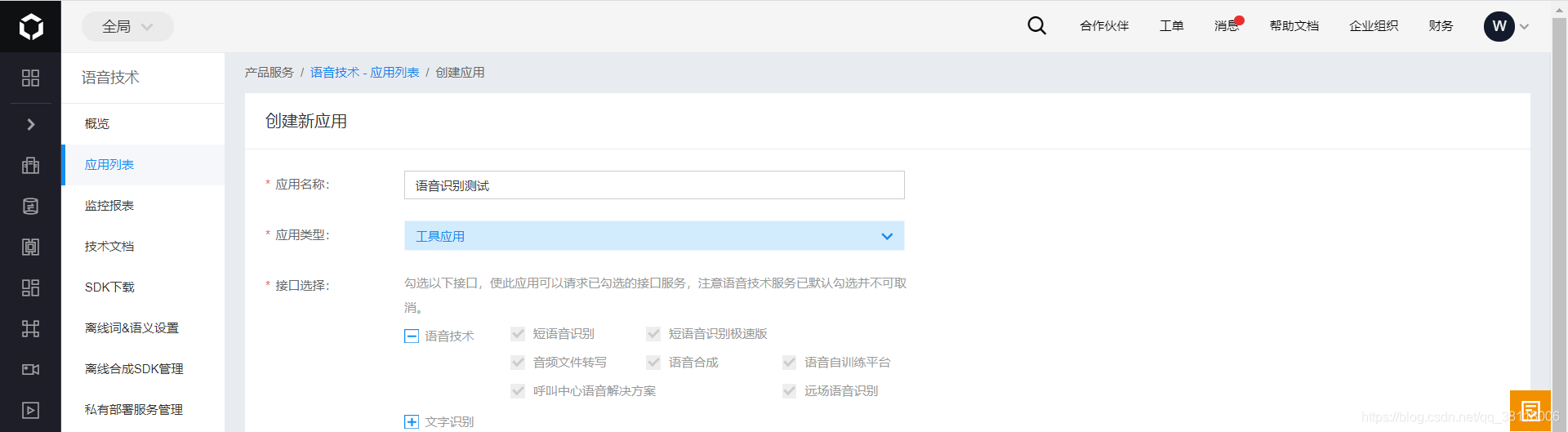
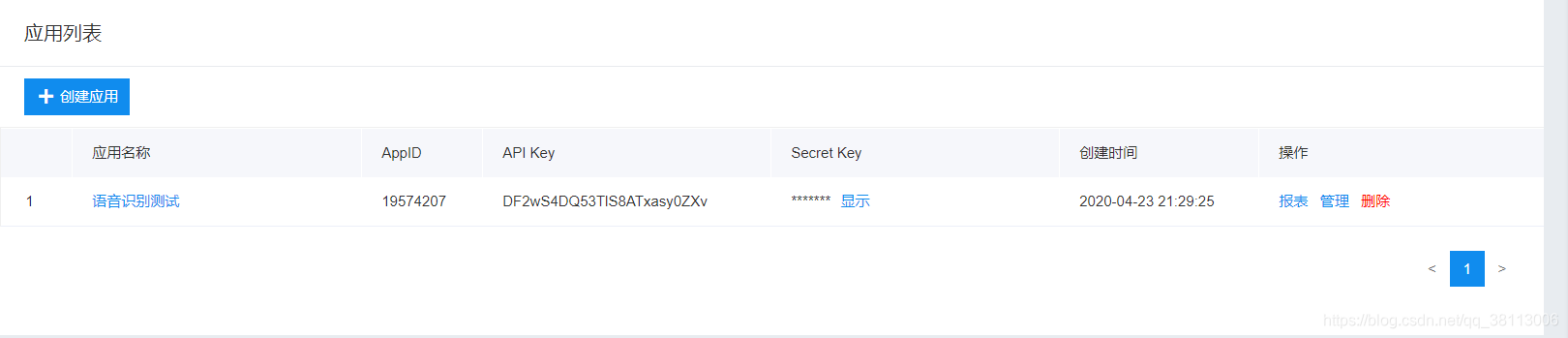
然后我们就可以看到创建好的应用
二、获取Access Token
首先导入requests包:
import requests
然后使用过程创建的项目的API Key和Secret_Key获取Access Token
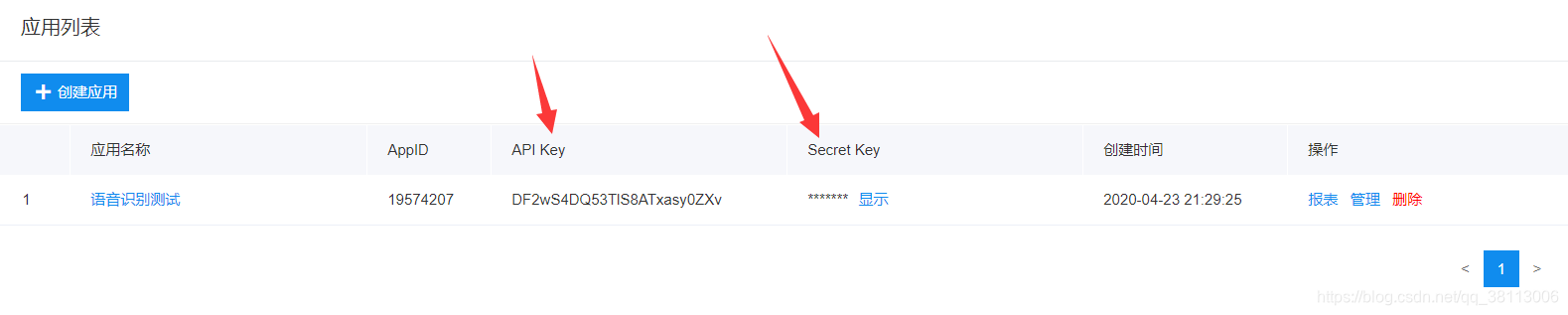
API_Key = "DF2wS4DQ53TlS8ATxasy0ZXv" # 官网获取的API_Key
Secret_Key = "GvADiMXnwATEhaiKuOXg3t37KnKClGWr" # 为官网获取的Secret_Key
#拼接得到Url
Url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id="+API_Key+"&client_secret="+Secret_Key
resp = request.urlopen(Url)
if resp:
result = json.loads(resp.read().decode('utf-8'))
print(result)
# 打印access_token
print(result['access_token'])
# 打印有效期
print(result['expires_in']/(60*60*24),"days")
运行,可以得到

我们将其封装成一个函数:
def get_token():
API_Key = "DF2wS4DQ53TlS8ATxasy0ZXv" # 官网获取的API_Key
Secret_Key = "GvADiMXnwATEhaiKuOXg3t37KnKClGWr" # 为官网获取的Secret_Key
#拼接得到Url
Url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id="+API_Key+"&client_secret="+Secret_Key
try:
resp = request.urlopen(Url)
result = json.loads(resp.read().decode('utf-8'))
# 打印access_token
print("access_token:",result['access_token'])
return result['access_token']
except request.URLError as err:
print('token http response http code : ' + str(err.code))
三、通过Post将上传音频文件,获得语言识别结果
通过查阅百度语音识别的技术文档,我们有两种方法将文件上传:

因为第二种更简单,我们使用第2种方法,首先打开我们需要识别的音频文件,获取里面的数据
# 打开需要识别的语音文件
speech_data = []
with open("01.wav", 'rb') as speech_file:
speech_data = speech_file.read()
length = len(speech_data)
if length == 0:
print('file 01.wav length read 0 bytes')
我们将Url里的参数设置好:
# 3、设置Url里的参数
params = {'cuid': "12345678python", # 用户唯一标识,用来区分用户,长度为60字符以内。
'token': token, # 我们获取到的 Access Token
'dev_pid': 1537 } # 1537 表示识别普通话
# 将参数编码
params_query = parse.urlencode(params)
# 拼接成一个我们需要的完整的完整的url
Url = 'http://vop.baidu.com/server_api' + "?" + params_query
然后我们设置header,即请求头,我们使用的文件格式为wav,百度语音识别只支持16000采样率
# 4、设置请求头
headers = {
'Content-Type': 'audio/wav; rate=16000', # 采样率和文件格式
'Content-Length': length
}
这样就可以发送post请求了,将音频数据直接放在body中就好
# 5、发送请求,音频数据直接放在body中
# 构建Request对象
req = request.Request(Url, speech_data, headers)
# 发送请求
res_f = request.urlopen(req)
# 打印结果
result = json.loads(res_f.read().decode('utf-8'))
print(result)
print("识别结果:",result['result'][0])
录音程序可以参考上一篇博客:Python开发之路(1)— 使用Pyaudio进行录音和播音
不过要注意百度语音识别的对文件的要求

运行程序,可以看到,返回了识别到的结果

最后贴上完整代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: William
# encoding:utf-8
import json
from urllib import request,parse
def get_token():
API_Key = "DF2wS4DQ53TlS8ATxasy0ZXv" # 官网获取的API_Key
Secret_Key = "GvADiMXnwATEhaiKuOXg3t37KnKClGWr" # 为官网获取的Secret_Key
#拼接得到Url
Url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id="+API_Key+"&client_secret="+Secret_Key
try:
resp = request.urlopen(Url)
result = json.loads(resp.read().decode('utf-8'))
# 打印access_token
print("access_token:",result['access_token'])
return result['access_token']
except request.URLError as err:
print('token http response http code : ' + str(err.code))
def main():
# 1、获取 access_token
token = get_token()
# 2、打开需要识别的语音文件
speech_data = []
with open("01.wav", 'rb') as speech_file:
speech_data = speech_file.read()
length = len(speech_data)
if length == 0:
print('file 01.wav length read 0 bytes')
# 3、设置Url里的参数
params = {'cuid': "12345678python", # 用户唯一标识,用来区分用户,长度为60字符以内。
'token': token, # 我们获取到的 Access Token
'dev_pid': 1537 } # 1537 表示识别普通话
# 将参数编码
params_query = parse.urlencode(params)
# 拼接成一个我们需要的完整的完整的url
Url = 'http://vop.baidu.com/server_api' + "?" + params_query
# 4、设置请求头
headers = {
'Content-Type': 'audio/wav; rate=16000', # 采样率和文件格式
'Content-Length': length
}
# 5、发送请求,音频数据直接放在body中
# 构建Request对象
req = request.Request(Url, speech_data, headers)
# 发送请求
res_f = request.urlopen(req)
result = json.loads(res_f.read().decode('utf-8'))
print(result)
print("识别结果:",result['result'][0])
if __name__ == '__main__':
main()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









