






目录
一、为什么要使用索引
索引是数据结构,是数据库提高检索数据的常见手段。它是根据索引字段生成排好序数据文件。
二、什么是B+Tree索引
在讲解B+Tree索引之前,我们结合下面数据了解下二叉树、红黑树、B-Tree、Hash数据结构。
| A | B |
| 1 | 33 |
| 2 | 44 |
| 3 | 22 |
| 4 | 55 |
| 5 | 11 |
1、二叉树
规则:元素大的在右边、小的在左边。
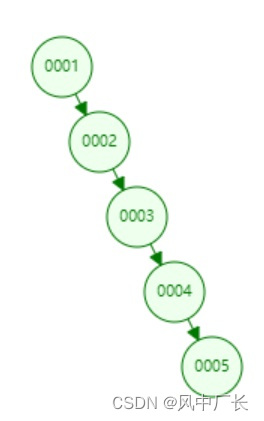
缺点:树的高度随着数据量的上升而增高。如果索引字段为自增ID、生成的二叉树类似链表。我们知道链表的的检索速度慢,所以二叉树性能低下。
2、红黑树
规则:元素大的在右边、小的在左边。
特点:相比二叉树,红黑树在树达到一定高度时会进行自我平衡,降低树的高度。所以相同的数据量,使用红黑树明显比二叉树性能会更好
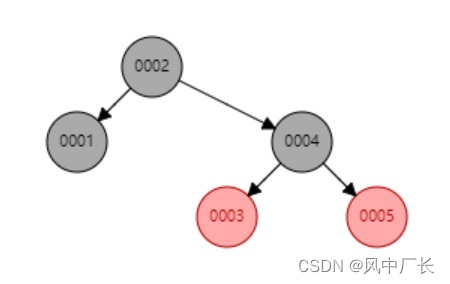
缺点:在百万级的数据中,树的高度依旧很高。检索数据能力欠缺。
3、Hash
对于Hash一般了解下,我们知道hash对索引进行一次计算就能定位到数据,性能很优秀。但是不支持范围查询,所以一般不使用。
4、B-Tree
上面说过红黑树虽然可以自我平衡,但是数据量增加树的高度还会很高。为了解决这个问题,思考是否在分配节点时分配大一点,使一个节点可以存放多个索引元素,相比红黑树一个节点放一个索引元素,变成了每个节点都可以存放多个元素。那么我们可以这么理解,树的高度不高也能存放很多索引元素,这种数据结构称之为B-Tree.
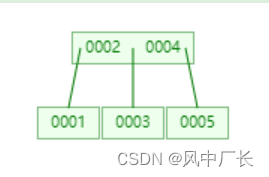
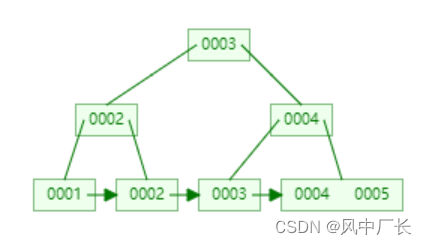
5、B+Tree
B+tree是B-tree的变种,比较类似。但是我们可以发现,非叶子节点的元素都冗余了一份数据在叶子节点种,并且叶子节点用指针连接,提高了区间的访问性能。还有一点和b-tree相比非叶子节点不存储data数据,这样可以存放更多的索引元素。
三、索引相关的知识点
(1)、聚集索引和非聚集索引
聚集索引(InnoDB):通俗的讲就是索引和数据文件在一起,找到了索引就找到了数据。在InnoDB存储引擎下,B+tree的叶子节点的data数据就存放完整的数据记录。
非聚集索引(MylSAM):就是索引和数据文件不在一起。在MylSAM存储引擎下,B+tree的叶子节点data数据存放的是指向数据文件的地址。
(2)、为什么推荐使用主键使用自增ID
通过B+Tree生成器分析,索引元素是从左到右排好序的,并且节点的存放的索引元素个数是有上限的,如果不使用自增的ID,且节点满了,当插入的元素刚好在满的节点上,试想会不会出现这样的一个现象,这个节点的元素会分裂并且移动到其他节点,从而带动每个节点移动,增加索引的维护成本。通过B+tree生成器可以知道按照自增插入,会一直添加到最左边,这样在很大的程度上可以避免分裂,从而提高性能。
一般推荐使用雪花ID,
(1)、ID是自增的
(2)、Long类型比字符串在比对数据时,速度更快。
(3)、为什么叶子节点非主键索引Data存放的是主键ID
在B+tree中,主键索引的叶子结点存放的是完整的数据记录,而非主键索引存放的是主键的ID。可以保证数据的一致性,存放主键ID相对于存放完整的数据记录,可以节省更多的磁盘空间。
(4)、什么是最左前缀匹配原则
最左前缀原则发生在联合索引中,它要求查询条件必须包含联合索引的第一个索引字段。因为生成B+Tree是按照联合索引字段先后顺序建立索引的。
(5)、什么是覆盖索引
SELECT查询语句中。查询的字段信息,都可以从索引文件中获取到,不要回表查询字段。
















 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











