






 本文探讨了如何运用自然语言处理技术解决从古典文学作品《红楼梦》中快速准确提取人物关系的问题,通过Python的request模块和Xpath解析实现小说文本爬取,构建红楼梦语料库,并详细描述了网络爬虫的原理和在获取古诗文网数据中的应用。
本文探讨了如何运用自然语言处理技术解决从古典文学作品《红楼梦》中快速准确提取人物关系的问题,通过Python的request模块和Xpath解析实现小说文本爬取,构建红楼梦语料库,并详细描述了网络爬虫的原理和在获取古诗文网数据中的应用。
介绍
红楼梦中包含了丰富的人物关系,人物关系作为作品的核心内容之一,在作品中扮演重要的角色。如何从这些中华典籍中快速准确的获取人物关系成为问题的关键。随着自然语言处理技术的发展,为解决这些问题提供了技术支撑,然而自然语言处理应用大都集中应用于英语或现代汉语上,但在古汉语的应用上还比较匮乏。
软件架构
src/spider.py 即为红楼梦全本文本信息的爬虫程序
第三章
第三章介绍了基于Python 中的 request模块和Xpath解析工具实现的小说自动爬取程序, 并对爬取到的小说文本进行预处理,最终建立起了红楼梦的语料库。
语料获取与预处理
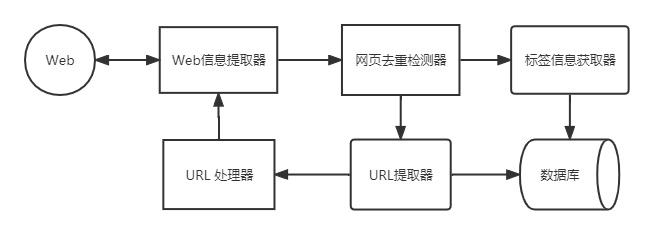
无论是利用人工编写的规则还是机器学习的技术,我们需要解决的第一步就是大量语料和数据的获取。好的样本需要具有足够的容量、全面的覆盖和均匀的分布,它们是影响算法有效性和最终结果的重要因素。目前很多自然语言处理研究所采用的语料库都是公开的第三方提供的开放语料库,但有些研究我们需要一些针对特定领域的语料来完成开发,例如本文研究的人物关系方面的抽取。这时可以使用网络爬虫工具对想获取的网页内容进行爬取,为研究提供源数据;并将从网页上爬取下来的 TXT 文本文件,进行一定的预处理,为后续工作做准备。主要是将其转换成我们需要的格式,并利于计算机识别。
网络爬虫是一种互联网机器人,用于自动在互联网上获取信息或数据。互联网中每个网页都有 URL,各网页上又有很多新的 URL 来指向其他网页,根据这个特点,我们就可以设计程序按照人工设定的规则对互联网上的内容信息按照 URL 的指向进行自动的爬取和收集。爬虫程序可根据一个定义好的初始 URL,对其页面上所有相关联的 URL 进行访问,同时可以抽取出我们需要的或有价值的信息。爬虫的工作流程[39]可描述如下:
- 选择初始 URL,人工定义和选取一个或多个 URL 链接作为执行爬虫程序的起始;
- 定义两个 URL 集合,一个为未抓取过的 URL 集合,一个为已抓取过的 URL 集合,将选择好的 URL 序列存储到 URL 未抓取集合中;
- 爬虫主调度程序从未抓取 URL 集合中选择一个 URL,根据网络协议对其进行解析,下载保存对应的页面;
- 将执行完页面抓取的 URL 添加到已抓取集合中;
- 分析爬取出的页面,将目标内容进行提取处理和储存,并把页面中出现的新的URL 进行去重和过滤后添加到未抓取集合,重复上述流程,直到达到用户设定的终止条件则结束爬取工作。
本文数据源自古诗文网,古诗文网收录了众多诗词歌赋以及古典小说,构建了较为全面的古诗文数据库,被众多传统文化爱好者所认可。 红楼梦现一般认为系清代作家曹雪芹创作的章回体长篇小说 。早期仅有前八十回抄本流传,原名《石头记》。程伟元搜集到后四十回残稿,邀请高鹗协同整理出版百二十回全本,定名《红楼梦》。亦有版本作《金玉缘》《脂砚斋重评石头记》。所以此书分为120回“程本”和80回“脂本”两种版本。新版通行本前八十回据脂本汇校,后四十回据程本汇校,署名“曹雪芹著,无名氏续,程伟元、高鹗整理”。为保证数据的严谨性与一致性,本文均采用小说的一百二十回“程本”版本。
url选取
本文先根据古诗文网红楼梦第一章页面(https://so.gushiwen.cn/guwen/ bookv_46653FD803893E4F923B7799A229D1E5.aspx),将其作为初始 URL。并将页面中“下一章”按钮中链接到的地址获取出来,将其放入等待抓取的 URL 队列中。再按照这一策略,从队列中不断抓取 URL,一直重复以上的操作,直至该页面没有下一章按钮为止。
网页下载
网页的下载功能是使用 Python 自带的 urllib 库实现,它所提供的功能就是操作一系列 URL。urllib 的 request 模块可以非常方便地获取到 URL 对应的网页内容,也可以说是将一个 GET 请求发送到指定页面,接着会返回 HTTP 的响应。网页下载器的作用体现在两个地方,一是对每个栏目页也就是初始 URL 对应页面进行下载以获取标题 URL,二是对每个标题 URL 对应正文页进行下载以获取文字信息。 由于该网站采取了反爬措施,则需要在代码中加入请求头headers,headers 是向 Request 对象添加的 HTTP 头,通过这种方式可以伪装成浏览器发送 GET 请求,最终将返回的网页信息以 HTML 的格式存储到 response 中,传送到网页解析器中。
网页解析
网页解析器的实现则需要借助一个工具——Xpath,它是一个强大而又灵活的 Python 第三方网页解析库,且可支持 Python 库中自带的 HTML 解析器 html.parser 和一些第三方的解析器。利用它就可以避免使用和编写繁杂的正则表达式,也能做到方便且高效的提取出网页内容信息。Xpath 对网页的解析是一种结构化解析,所谓结构化解析就是将整个网页文档看作是一棵 DOM 树,以树形结构进行上下级节点元素的遍历和访问。DOM是 W3C 官方定义的访问解析 HTML 网页的标准接口,它将整个网页文档当做一个 Document 对象,<html>标签作为根节点,其他标签作为子节点。图展示了 DOM 树的基本结构。根据对各栏目网页的 HTML 代码的观察,可以总结出新闻标题链接和正文部分的所在标签节点位置和范围,例如 URL 地址一般会位于<a>标签或<span>标签中,而大段文字部分则一般位于<div>标签中的<p>标签,在实际提取过程中,可以先根据标签的 id 标识或 class 类别确定大的范围,再找出对应提取部分的标签的准确位置,接着就可以根据这些标签解析出 URL 链接和网页正文部分。 找到红楼梦的文字内容和下一章连接的位置后,根据Xpath语法表达为:
results = tree.xpath('//body//div[@class="contson"]/p/text()')
url_next = tree.xpath('//body//div[@class="bookvmiddle"]/a[text()="下一章"]/@href')
该模块先以下载好的 HTML 或 XML 网页字符串,也就是参数 response 作为输入,并指定 html.parser 作为 HTML 解析器,以 utf-8 编码进行解析,以此创建 Xpath.tree对象,同时会将整个网页字符串加载为 DOM 树,接着就可以使用 find(查找第一个符合要求的节点)或 find_all(查找所有符合要求的节点)函数对 DOM 树中各节点进行搜索,查找到节点后可访问节点名称、属性以及文字,将指定标签或属性中的内容提取出来,分别存入 TXT 文件,最终得到源语料。
其他部分内容请详见论文
需要源码和论文的可以评论区留个言。


















 1520
1520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









