







目录
数据
《红楼梦》txt文本文件
人物出场频次
1.统计人物出场频次
import jieba as j
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
# 人物名称列表
names = ['贾母', '贾珍', '贾蓉', '贾赦', '贾政', '贾琏', '袭人', '王熙凤', '紫鹃', '翠缕', '香菱', '豆官', '薛蝌',
'薛蟠','贾宝玉', '林黛玉', '平儿', '薛宝钗', '晴雯', '林之孝']
txt = open('红楼梦.txt','r',encoding='utf-8').read()
words = j.lcut(txt) # 进行分词,并返回一个包含所有分词结果的列表
counts = {}
for word in words:
# 忽略长度为1的词(可能是单个字符或标点)。
if len(word)==1:
continue
# 如果词是人物名称的别名或昵称,则将其转换为标准名称
elif word in ['老太太','老祖宗','史太君','贾母']:
word = "贾母"
elif word in ['贾珍','珍哥儿','大哥哥']:
word = "贾珍"
elif word in ['老爷','贾政']:
word = "贾政"
elif word in ['贾宝玉','宝玉','宝二爷']:
word = '贾宝玉'
elif word in ['风辣子','王熙凤','熙凤']:
word = "王熙凤"
elif word in ['紫鹃','鹦哥']:
word = "紫鹃"
# 检查转换后的word是否在names列表中,并`counts`字典中增加相应的计数。
if word in names:
counts[word] = counts.get(word, 0) + 1
# 排序并打印结果
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(len(items)):
word, count = items[i]
print('{0:<10}{1:>5}'.format(word, count))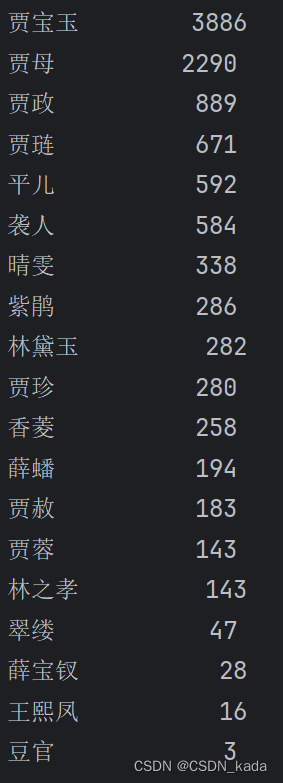
2.词云图绘制
# 人物出场的频次
import jieba as j
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from collections import Counter
# 人物名称列表
names = ['贾母', '贾珍', '贾蓉', '贾赦', '贾政','贾琏', '袭人', '王熙凤', '紫鹃', '翠缕', '香菱', '豆官', '薛蝌', '薛蟠',
'贾宝玉', '林黛玉', '平儿', '薛宝钗', '晴雯', '林之孝']
# 转换列表以便统一名称
name_map = {
"老太太": "贾母",
"老祖宗": "贾母",
"史太君": "贾母",
"珍哥儿": "贾珍",
"大哥哥": "贾珍",
"老爷": "贾政",
"宝二爷": "贾宝玉",
"宝玉": "贾宝玉",
"熙风": "王熙凤",
"风辣子": "王熙凤",
"鹦哥": "紫鹃"
}
# 读取文本
txt = open('红楼梦.txt', 'r', encoding='utf-8').read()
# 分词和计数
words = j.lcut(txt)
word_counts = Counter()
for word in words:
if len(word) == 1 or not any(char.isalpha() for char in word):
continue # 忽略单字和非字母字符
word = name_map.get(word, word)
if word in names:
word_counts[word] += 1
# 将Counter对象转换为字典
word_dict = dict(word_counts)
# 创建一个词云对象
wc = WordCloud(font_path='C:\\Windows\\Fonts\\STXINWEI.TTF', # 指定字体文件路径,确保支持中文
scale=32,
background_color='white', # 背景颜色
max_words=20, # 最大显示的词数
max_font_size=100, # 字体最大值
min_font_size=10, # 字体最小值
width=250, # 词云图的宽度
height=150, # 词云图的高度
colormap='viridis'# 使用不同的颜色映射
)
# 生成词云
wc.generate_from_frequencies(word_dict)
# 显示词云图
plt.figure(figsize=(10, 5))
p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3517
3517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









