






机器学习笔记
特征选择(来自周志华老师的机器学习)
Relief与Relie-F
Relief是为二分类问题设计的
Relief是一种过滤式特征选择方法。
(过滤式方法先对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关.这相当于先用特征选择过程对初始特征进行"过滤",再用过滤后的特征来训练模型)
Relief设计了一个"相关统计量"来度量特征的重要性.该统计量是一个向量,其每个分量分别对应于一个初始特征,而特征子集的重要性则是由子集中每个特征所对应的相关统计量分量之和来决定.于是,最终只需指定一个阈值
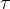 然后选择比
大的相关统计量分量所对应的特征即可;也可指定欲选取的特征个数k, 然后选择相关统计量分量最大的k 个特征.
然后选择比
大的相关统计量分量所对应的特征即可;也可指定欲选取的特征个数k, 然后选择相关统计量分量最大的k 个特征.
Relief的关键是如何确定相关统计量,给定训练集{(x1,y1),(x2,y2),...(xm,ym)}.对每个示例xi,Relief 先在xi的同类样本中寻找其最近邻,称为"猜中近邻" (near-hit) ,再从xi的异类样本中寻找其最近邻
,称为"猜错近邻" (near-miss) ,然后,相关统计量对应于属性 分量为
![]()

从式
(1
1.
3) 可看出,若 Xi 与其猜中近邻  在属性
上的距离小于
Xi 其猜错近邻
在属性
上的距离小于
Xi 其猜错近邻 的距离 ,则说明属性j 对区分同类与异类样本是有益的,于是 增大属性 j所对应的统计量分量;反之,若
Xi 与其猜中近邻
在属性
上的 距离大于 Xi 与其猜错近邻
的距离,则说明属性
起负面作用,于是减小 属性 j所对应的统计量分量.最后,对基于不同样本得到的估计结果进行平均,就得到各属性的相关统计量分量,分量值越大,则对应属性的分类能力就越强.
的距离 ,则说明属性j 对区分同类与异类样本是有益的,于是 增大属性 j所对应的统计量分量;反之,若
Xi 与其猜中近邻
在属性
上的 距离大于 Xi 与其猜错近邻
的距离,则说明属性
起负面作用,于是减小 属性 j所对应的统计量分量.最后,对基于不同样本得到的估计结果进行平均,就得到各属性的相关统计量分量,分量值越大,则对应属性的分类能力就越强.
Relie-F是Relief的扩展变体,能处理多分类问题。
假定数据集D中的样本来自
 个类别。对示例xi,若它属于第k类(k∈{1,2,...,
}),则Relie-F先在第k类的样本中寻找xi的最近邻示例
并将其作为猜中近邻,然后在第k类之外的每个类中找到一个xi的最近邻示例作为猜错近邻,记为
个类别。对示例xi,若它属于第k类(k∈{1,2,...,
}),则Relie-F先在第k类的样本中寻找xi的最近邻示例
并将其作为猜中近邻,然后在第k类之外的每个类中找到一个xi的最近邻示例作为猜错近邻,记为 (l=1,2,...,
;l
(l=1,2,...,
;l
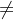 k
).
k
).
相关统计量对应于属性j的分量为
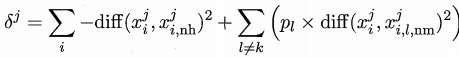
其中pl为第l类样本在数据集D中所占的比例。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









