







2.1 内置序列类型概述
容器序列:list、tuple 和 collections.deque 这些序列能存放不同类型的数据。
扁平序列:str、bytes、bytearray、memoryview 和 array.array,这类序列只能容纳一种类型。
可变序列:list、bytearray、array.array、collections.deque 和 memoryview。
不可变序列:tuple、str 和 bytes。
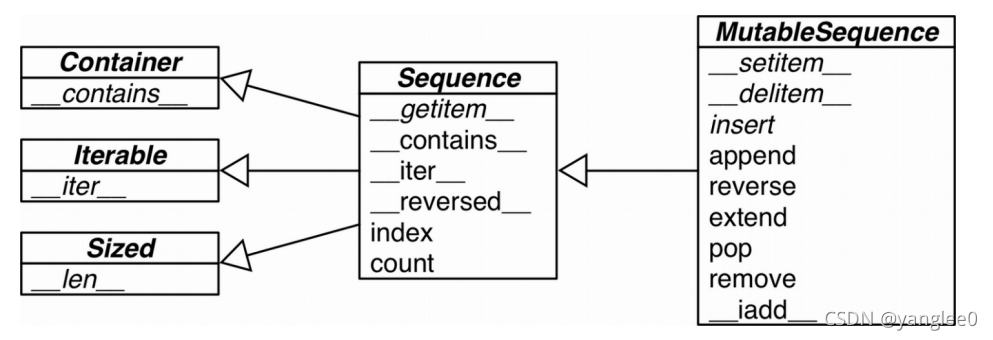
下图为可变序列(MutableSequence)和不可变序列(Sequence)的差异
列表推导是一种构建列表的方法,它异常强大,列表推导为我们打开生成器表达式(generator expression)的大门,后者具有生成各种类型的元素并用它们来填充序列的功能。
2.2 列表推导和生成器表达式
列表推导是用来构建列表的,
生成器表达式是用来构建其他任何类型的序列。
2.2.1 列表推导和可读性
列表推导示例:更加具有可读性。

2.2.2 列表推导同filter和map的比较
filter 和 map 合起来能做的事情,列表推导也可以做,而且还不需要借助难以理解和阅读的 lambda 表达式。

之后会在第五章项目描述。
扩展:如何用列表推导来计算笛卡儿积:两个或以上的列表中的元素对构成元组,这些元组构成的列表就是笛卡儿积。
2.2.3 笛卡儿积
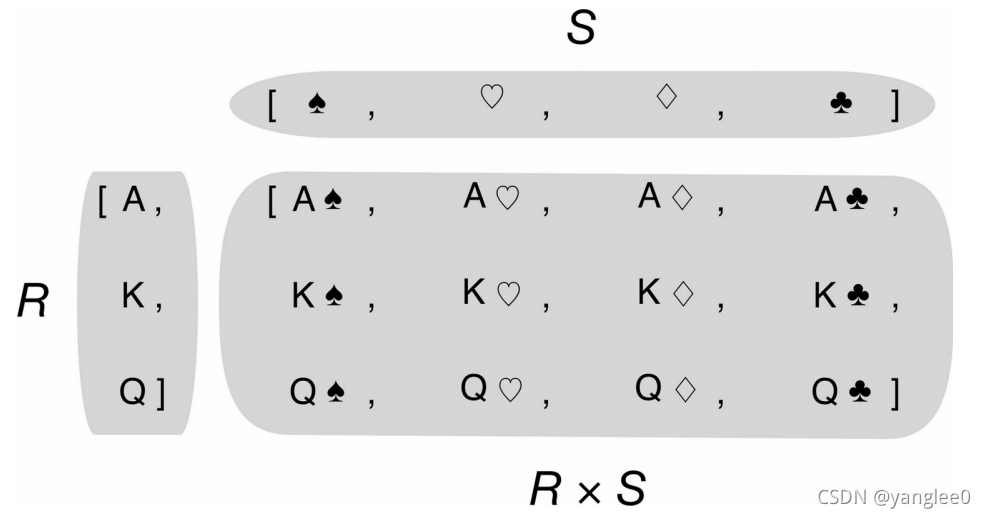
用列表推导可以生成两个或以上的可迭代类型的笛卡儿积。笛卡儿积是一个列表,列表里的元素是由输入的可迭代类型的元素对构成的元组,因此笛卡儿积列表的长度等于输入变量的长度的乘积。如下图:
列表推导的作用只有一个:生成列表。如果想生成其他类型的序列,生成器表达式就派上了用场。
2.2.4 生成器表达式
生成器表达式背后遵守了迭代器协议,可以逐个地产出元素,这种方式更加节省内存。
生成器表达式的语法跟列表推导差不多,只不过把方括号换成圆括号而已。


2.3 元组不仅仅是不可变的列表
除了用作不可变的列表,它还可以用于没有字段名的记录。
2.3.1 元组和记录
元组其实是对数据的记录:包括数据和位置。因为可以把元祖当做一些字段的集合。

2.3.2 元组拆包
拆包的两种应用:
上节中的最后一张图,把元组 (‘Tokyo’, 2003, 32450, 0.66, 8014) 里的元素分别赋值给变量 city、year、pop、chg 和 area,而这所有的赋值我们只用一行声明就写完了。
同样,在后面一行中,一个 % 运算符就把 passport 元组里的元素对应到了 print 函数的格式字符串空档中。这两个都是对元组拆包的应用。
元组拆包在被可迭代对象中的元素数量中,必须要跟接受这些元素的元组的空档数一致。如果不一致,也可以用*来忽略多余的元素。
1、拆包形式之一:平行赋值。

2、占位符:_
比如 os.path.split() 函数就会返回以路径和最后一个文件名组成的元组 (path, last_part):

3、除此之外,在元组拆包中使用 * 也可以帮助我们把注意力集中在元组的部分元素上。用*来处理剩下的元素。
在 Python 中,函数用 *args 来获取不确定数量的参数算是一种经典写法了。

2.3.3 嵌套元组拆包
接受表达式的元组可以是嵌套式的,例如 (a, b, (c, d))。只要这个接受元组的嵌套结构符合表达式本身的嵌套结构,Python 就可以作出正确的对应。

2.3.4 具名元组(给元祖命名)
collections.namedtuple 是一个工厂函数,它可以用来构建一个带字段名的元组和一个有名字的类。



2.3.5 作为不可变列表的元组
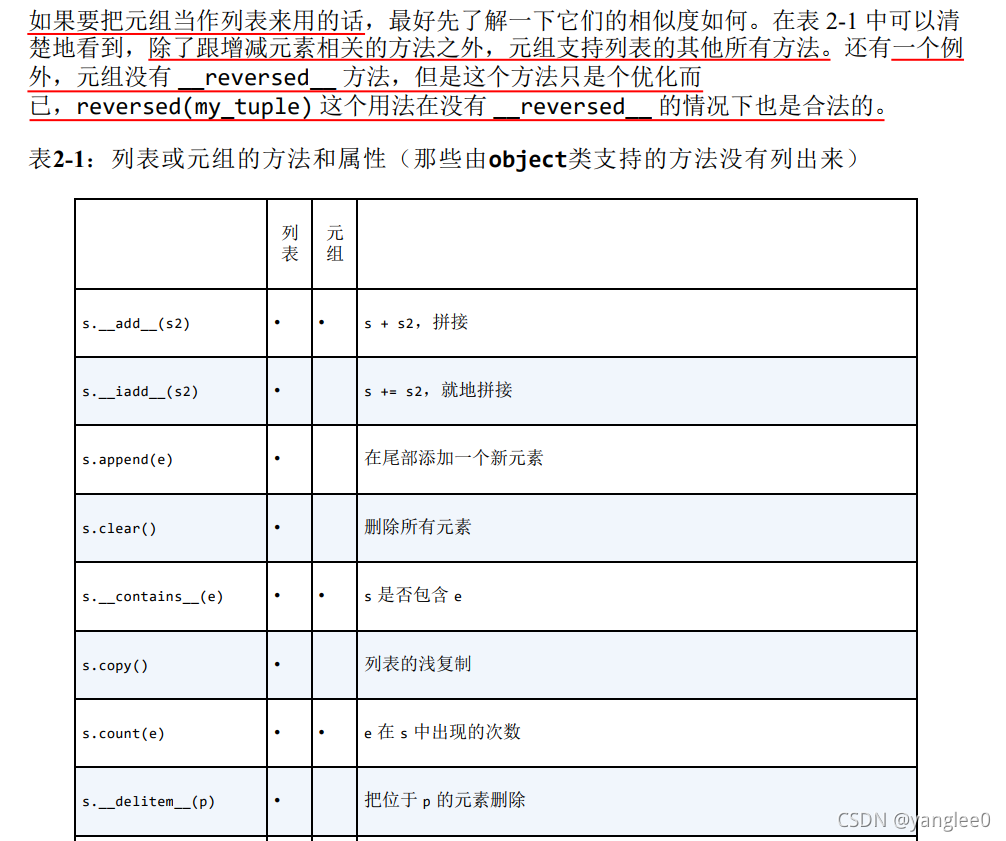
等等方法














 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









