






目录
DDD核心思想
- 在软件中,事物对应的是对象,行为对应的是方法,关系对应的是关联。
- 所以在领域驱动设计中,就将以上三个对应的关系,做成了一个领域模型。
- 然后通过这个领域模型对程序进行设计。在每次需求变更时,先将需求还原到领域模型中进行分析, 然后根据领域模型进行调整。
表现层/应用层/领域层/基础设施层
示意图
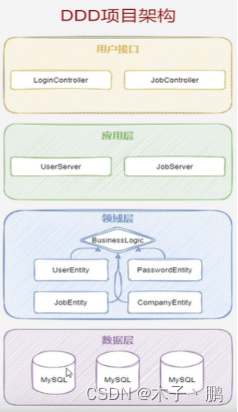
领域层
- 领域层包含了业务对象,基本上需要实现所有的业务逻辑。
- 像某些公司做的管理系统,如果要细分,用户管理是一个领域项目,项目管理是一个领域项目,活动 管理是一个领域项目。不过公司就那么大,人就那么多,项目进度也比较急,没有时间和精力去做那 么精细的划分。如果一个公司团队不够大,活分的不够细,搞这些东西就是再增加工作量,没有意义。
- 领域层中包含了实体,聚合根,值对象,充血模型。
表现层
- 表现层就是用户的接口,用户的输入和数据的展示。
- 像WebAPI,MVC,gRPC,SwaggerUI都属于表现层。
应用层
- 应用层就是系统的业务功能。
- 一般把增删改放到领域层,查询放到了应用层。
- 像贫血模型的转换就是在应用层进行处理的。
基础设施层
- 基础设施层就是提供增删改查的API接口。
- 像EFCore,Redis,MongoDB这些数据库的API接口都在基础设施层,也可以理解为数据库访问层。
聚合根/实体/值对象
什么是聚合根
- 在公司里面老板就是聚合根。
- 各个聚合之间需要通过聚合根的ID来关联具体的实体,如果需要访问其它聚合的实体,就需要先访问 聚合根,然后根据聚合根的ID在访问具体的实体。
总结
- 值对象是没有ID的,就是用来描述实体的状态。
- 实体是有ID的,用值对象来描述状态,用ID来区分不同的实体。
- 聚合根也是实体,但是聚合根的ID是全局唯一的,聚合根下面的实体ID在聚合根内也 是唯一的。

贫血模型/充血模型
贫血模型
是什么
贫血模型是只包含数据,不包含具体业务逻辑的类。
优点
贫血模型可以让各层之间进行单向依赖,对象只做数据的传输,并且不影响层次的划分。
缺点
- 贫血模型的对象不能描述一个完整的业务逻辑,需要一组相互协作的类来共同完成。
- 所以贫血模型的业务描述能力比较差,稍微复杂一点的业务逻辑,就可能需要很多的贫血模型对象去 表达。
充血模型
是什么
充血模型是既包含数据也包含业务逻辑的类。
优点
充血模型的对象表达能力强,比较适合复杂的业务逻辑,可复用的程度也比较高。
缺点
应该把什么样的业务逻辑放到充血模型中,这是非常模糊的,除非说你对业务非常精通。
为什么贫血模型受欢迎
- 大部分公司开发的系统,业务都没有那么复杂,都是基于SQL的CRUD操作。
- 所以只需要定义好贫血模型的对象,用来做数据的传输就行了。
- 如果非得要基于充血模型的对象来做,那你就要对业务非常精通。
什么场景下使用充血模型
- 在平时的开发中,大部分都是基于SQL模式的开发。
- 比如现在接到一个后端接口的开发需求时,就会去看接口需要的数据对应到数据库中需要哪些表。
- 然后定义好具体的Entity,Dto。最后往对应的Repository,Service,Controller中添加代码。
- 很多业务逻辑都包裹在一个非常大的SQL语句中,在Service中真正能做的事情变得非常少。
- 如果开发另一个业务模块的功能时,就只能重新再写个满足新需求的SQL语句。
- 所以在这种开发模式下,必须要理清所有的业务,甚至是精通业务,才能定义具体的领域模型。
- 这个时候领域模型就相当于可复用的业务中间层,在开发新的功能时,就可以进行复用。
服务/模块/聚合/工厂
服务(Services)
什么是服务
服务就是为了给领域模型提供一些简单的方法。
服务的特点
服务中的方法不属于任何实体和值对象,但是会涉及多个对象,所以它属于领域模型的范畴。
模块(Moudles)
- 对于比较复杂的应用程序,领域模型会越来越大,到最后就变得很复杂。
- 所以模块就是把相关的领域模型放在一起,形成模块化。
聚合(Aggregates)
聚合根,实体,值对象放在一起就是聚合。
工厂(Factories)
在比较大的系统中,实体和聚合都是很复杂的,所以需要通过工厂来创建对象。
Repository/UnitOfWork
Repository
是什么
Repository是仓储模型,主要用来封装各种数据库的API接口,也可以理解为数据库访问层。
特点
- Repository的主要功能是分离业务层和数据库访问层。
- 向Repository传入的Entity是个泛型,如果数据库中没有该Entity会在编译时就报错。
UnitOfWork
- 如果现在操作多个Repository,用UnitOfWork来保证数据库上下文DbContext具有原子性和一致性。
- 比如一个Repository用来新增一条数据,另一个Repository用来删除一条数据,然后调用SaveChanges 方法的时候如果某个Repository的操作失败了,所有的操作都会自动回滚。
- 还有一种场景比如用一个Repository来新增一条数据,需要先调用SaveChanges方法来保存数据。保 存成功之后会返回新增这条数据的主键ID,然后另一个Repository也需要新增一条数据,并且需要用 到刚才返回的主键ID去新增,这个时候如果调用SaveChanges方法进行数据保存时出错了,刚才新增 的那条返回主键ID的数据是不会被删除的。所以需要用到DbContext.Database.BeginTransaction来开启 事物进行包裹,保证数据库事物的一致性。
- 原子性就是要么都执行,要么都不执行。
- 一致性就是要么执行都成功,要么执行都失败。















 613
613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











