






目录
为什么要有ORM
就是为了解决传统OOP中的对象和关系型数据库的表互相不匹配的问题。
EFCore第一次慢
为什么第一次慢
- 每个DbContext对象,在第一次使用的时候,EFCore都会根据数据库中的信息在内存中生成一个映射 视图,这个操作很耗时。
- 比如CodeFirst在第一次启动的时候会对比程序中的实体和数据库中的表,生成实体和表的映射视图。
- 并且每次启动的时候,EFCore都需要重新编译本地代码,对性能也会有影响。
为什么要生成映射视图
在EFCore中要生成映射视图,是因为EFCore要将当前模型与旧模型进行快照对比,用来确定当前模型和旧模型之间的差异性,然后生成迁移的源文件。
解决方案
暖机操作
- 解决EFCore第一次慢的问题,可以在程序初始化时一次性触发所有的DbContext进行映射视图的生成 操作。
- 主要是调用了StorageMappingItemCollection的GenerateViews方法。
- 在.Net应用程序中,可以将暖机操作放到Application_Start中去执行。

禁用_MigrationHistory表的查询
- 也可以在EFCore中把对_MigrationHistory表的查询给禁用掉。
- CodeFirst第一次查询的时候会对_MigrationHistory表进行查询,主要是为了检查数据库的表和当前的 实体是否匹配,确保EF能够正常运行。
- 所以在生产环境中,可以把_MigrationHistory表的查询给禁用掉。
- Database.SetInitializer<DbContext>(null)。
DbContext
是什么
- DbContext是个数据库对象的上下文环境,里面内置了对象的跟踪,每一个DbContext对象就相当于开 启了一个数据库链接。
- 所以在一次HTTP的请求中,最好用的是同一个DbContext对象。如果是多个HTTP的请求或者是多个 线程最好创建多个DbContext对象,用完要把它尽快释放掉。
线程安全问题
为什么不安全
- DbContext对象线程不安全,是因为在DbContext对象执行AcceptAllChanges方法之前,会检测实体状 态的改变,所以在调用SaveChanges方法时会先和当前的DbContext对象上下文进行一一对应。
- 如果是异步多线程,当第一个线程创建了DbContext对象,然后进行了一些实体状态的修改,还没有 等AcceptAllChanges方法执行之前,第二个线程也进行了同样的操作。虽然第一个线程调用SaveChanges 方法可以成功,但是第二个线程肯定会报错,因为实体状态已经被第一个线程中的DbContext对象给 修改了。
解决方案
- 解决DbContext对象线程不安全的问题,首先DbContext对象在IOC容器中的注入方式必须是 AddScoped,表示DbContext对象在这一次请求中,只能被构造一次。
- 还可以在当前这个DbContext对象中,使用async和await来进行异步编程,使用await关键字来确保 所有的异步操作都是在调用另一个方法之前完成的。
- 如果不使用异步模型进行编程,可以考虑使用混合锁。但是在多线程并发的场景下,线程会进行排队, 会阻塞主线程。
注意事项
- 所以在使用DbContext对象时,需要注意两点。
- 第一点就是要保证多个线程不能访问同一个DbContext对象。
- 第二点就是同一个跟踪实体也不能被多个DbContext对象进行实体状态的修改。
两个DbContext对象如何保证安全性
- 两个DbContext对象如果表示的不是同一个数据库对象,也就是说不是同一个数据库,那就没有线程 安全问题。
- 如果表示的是同一个数据库对象,也就是说是同一个数据库,那还是使用async和await来进行异步编 程,增删改的操作肯定是要调用SaveChanges方法才能持久化保存到数据库当中,不管是哪个DbContext 对象先调用SaveChanges方法,那肯定都得在SaveChanges方法前面加上await关键字,await等待的 任务是新开启线程的执行,await后面的代码等到新开启线程的任务执行完毕以后再执行,所以下一个 await SaveChanges方法肯定是要等上一个await SaveChanges方法执行成功之后才执行。
- 如果两个DbContext对象是同一个数据库对象,并且还修改的是同一张表,这个时候需要考虑使用乐 观锁,乐观锁的事务隔离级别是Read committed,也就是读已提交,能避免脏读和丢失更新。
- 具体的实现也很简单,就是给当前的这张表再加一个字段用来存储版本号或者时间戳,在执行更新操 作的时候,如果现在储存的是时间戳,逻辑就是update table set 时间戳=新的时间戳 where 时间戳= 旧的时间戳,如果时间戳不对,就更新失败。
Linq和拉姆达表达式
- Linq和拉姆达表达式是完全一致的,没有优劣之分。
- Linq和拉姆达表达式只有左连接,需要指定DefaultIfEmpty方法。
- Linq可以理解为是一个封装,拉姆达表达式可以理解为是一个方法。
Linq to object/Linq to sql
- Linq to object 是Enumerable对象,IEnumerable类型的集合在处理数据时,都是内存的数据。
- Linq to sql 是Queryable对象,针对IQueryable类型的集合在处理数据时,可以是内存的数据,也可以 是来自数据库的数据。
IEnumerable/IQueryable
- IEnumerable类型的集合在调用Skip方法和Take方法之前数据就已经被加载到本地内存里面了。
- IQueryable类型的集合是将Skip方法,Take方法,编译成SQL语句之后再发送给数据库,所以它并不 是把所有的数据都加载到内存里面才进行条件过滤的。
- IEnumerable类型的集合主要针对的是内存数据的延迟查询。
- IQueryable类型的集合主要针对的是数据库的延迟查询。
- 如果分页查询的类型是IEnumerable类型的集合时,那么会先将所有的数据都查询到内存中,然后具体 的分页操作是在内存中完成的,但是遍历IEnumerable类型的集合时,如果在循环内进行Linq操作比 如调用FirstOrDefault方法那么还是会多次查询数据库。
延迟查询/立即查询
- AsEnumerable方法或者AsQueryable方法都表示延迟查询,调用AsEnumerable方法或者AsQueryable 方法的时候,对于数据库来说什么都没有发生。
- 只有对IEnumerable类型或者IQueryable类型的集合进行遍历时,或者将IEnumerable类型或者 IQueryable类型的集合返回给前端时,才会去从数据库中查询数据。如果在遍历IEnumerable类型或者 IQuerable类型的集合时,在循环内进行Linq操作比如调用FirstOrDefault方法那么还是会多次查询数 据库。
- 但是调用ToList方法的时候就是立即查询,会立即从数据库中查询数据,然后把数据加载到本地内存 中。
- 如果仅仅只是用来进行数据查询,也不需要对查询出来的数据在内存中对它进行额外的处理,就可以 调用AsEnumerable方法或者AsQueryable方法将集合类型转换为IEnumerable类型或者IQueryable类 型。
内置的扩展方法
Attach
Attach方法就是将数据附加到当前的DbContext对象中,支持实体的状态修改和添加新的实体。如果进行重置,状态就是UnChanged。
Include
- EFCore在调用Include方法进行查询时,数据库中的两张表必须得包含外键关系,然后在Include方法 中指定数据库中外键的名称对应的类属性名称。
- Include方法底层生成的SQL关键字就是LEFT JOIN。
查询优化
AsNoTracking
- 调用AsNoTracking方法进行查询的时候,不会对DbContext对象中的Entity对象进行追踪,也就是说 EFCore不会监听当前Entity对象的状态是否会发生变化。
- 所以在进行查询时速度会更快,但是如果对查询出来的数据进行了修改,那么在调用SaveChanges方 法时,修改的数据在数据库中是不会有任何的变化的。
AsNonUnicode
- 调用AsNonUnicode方法时,会把数据库默认的字符集转换为非Unicode字符集来进行查询,数据库一 般都是按照Unicode字符集来进行查询。
- 如果数据库存储的数据类型是varchar类型,varchar类型是非Unicode字符集,那么EFCore在调用 AsNonUnicode方法进行查询时,查询速度会变快。
- 如果数据库存储的数据类型是nvarchar类型,nvarchar类型是Unicode字符集。相比于非Unicode字 符集,Unicode字符集的范围更广,除了能存储简体中文和英文,还能存储繁体中文,韩文,日文。那 么EFCore在调用AsNonUnicode方法进行查询时,会强制把Unicode字符集转换为非Unicode字符集。 这就相当于把繁体中文强制转换为简体中文,数据可能就会出现乱码。
Find
- 一般通过某个实体的主键ID进行查询时,可以调用Find方法。
- EFCore中的Find方法会优先从缓存中进行查询,只有当该条数据被修改之后,在调用Find方法时才会 查询出修改后的数据。
延迟查询
如果仅仅只是用来进行数据查询,也不需要对查询出来的数据在内存中对它进行额外的处理,就可以调用AsEnumerable方法或者AsQueryable方法将集合类型转换为IEnumerable类型或者IQueryable类 型。
EFCore开启事物
BeginTransaction
- EFCore中调用SaveChanges方法本身就具有事务性。
- 如果需要多个SaveChanges方法形成一个事物,就可以使用DbContext.Database.BeginTransaction方法 来开启事物。
- 其中的Commit方法表示提交事物,Rollback方法表示回滚事物,Dispose方法表示销毁事物。
- 如果使用using进行包裹时,不需要手动调用Rollback方法和Dispose方法,会自动进行回滚事物和销 毁事物。
如果是同一个数据库但是有多个DbContext对象,其中一个DbContext对象开启了事务,其它DbContext 对象可以通过调用UseTransaction方法来实现共享事物。




TransactionScope
- 除了使用DbContext对象开启事物,还可以使用TransactionScope对象来开启事物。
- TransactionScope对象在不同的数据库上下文中是不支持的。
- 所以TransactionScope对象不支持分布式事物。
- 分布式事物可以考虑使用Saga。
同一个上下文开启事物

多种数据库访问技术同一个上下文开启事物
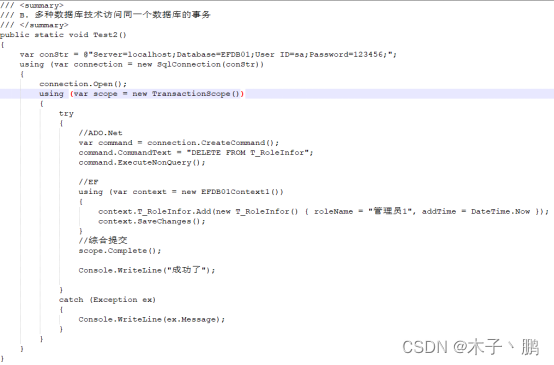
同一个数据库不同的上下文开启事物

EFCore表关系
Fluent API
在EFCore中,可以通过Fluent API来实现表与表之间的关系映射。
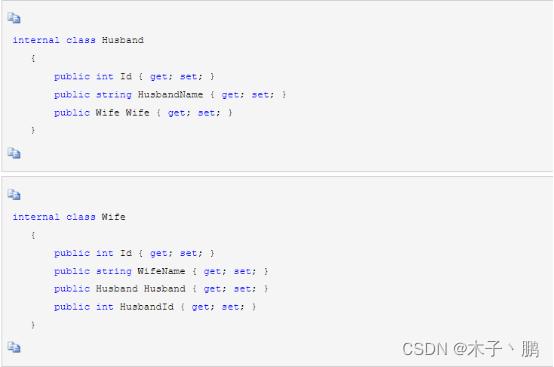
一对一
- 比如夫妻关系就是一对一。
- 丈夫实体中指定妻子的引用,妻子实体中指定丈夫的引用。
通过调用Fluent API中的HasOne方法和WithOne方法来实现一对一。

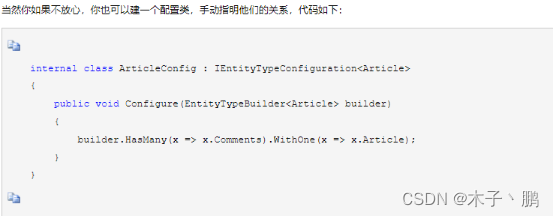
一对多
- 比如一个文章对应多个评论的关系就是一对多。
- 文章实体中用集合指定多条评论,评论实体中指定文章的引用。
- 通过调用Fluent API中的HasMany方法和WithOne方法来实现一对多。

多对多
- 比如老师和学生的关系就是多对多。
- 老师实体中用集合指定多个学生,学生实体中也用集合指定多个老师。
- 通过调用Fluent API中的HashMany方法和WithMany方法来实现多对多。
- 如果当前执行Add-Migration进行数据迁移。
- 然后执行Update-Database -v(-v表示显示详情信息)更新数据库。
- EFCore就会默认生成一张关系表,关系表的名字一般是两表的名字相加(StudentTeacher)。

-
指定生成的第三张表名
-

导航属性
- 在EF的主外键关系表里面,主表包含子表的集合,叫做导航属性,子表里面包含主表的引用实例。
- 所以在查询的时候可以通过Include方法把外键表的数据也查询出来,Include方法底层生成的SQL关 键字就是LEFT JOIN。
CodeFirst命令
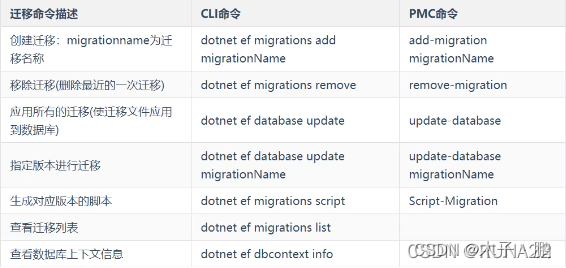
数据迁移
- 执行add-migration -c ProtocolMappingDBContext命令,系统最终会在文件的名字前面加入时 间串,主 要就是用来做数据迁移。
- add-migration命令会在Migrations文件夹下面生成一个Migration类的子类,该类会记录当前对数据库 和对数据库的表都进行了哪些操作。
- 执行remove-migration -c ProtocolMappingDBContext命令,会回撤上一步的添加,如果一直执行会回撤 到最初始的状态。
- 执行update-database -c ProtocolMappingDBContext命令,默认会根据最新生成的Migration类来更新 数据库。
增量脚本
- 最开始的时候执行add-migration init(定义的初始化的名称) script-migration命令,用来生成增量脚本。
- 后面执行add-migration updatePda(本次增量脚本的名称) script-migration init(上一次更新的脚步名称), 用来生成增量脚本。
- 也可以执行
script-migration
-from:"20210628091755_InitProtocolMappingEntity"
-to:"20210817025328_modificationDB" -c ProtocolMappingDBContext 命令,用来生成增量 脚本。
如果需要进行初始化把-from后面具体生成的Migration类的名称,换成0就可以了。
还可以执script-Migration -to:"20210817012626_modificationDB" -c ProtocolMappingDBContext命令, 把-from取消掉,默认会使用上一次生成的Migration类的名称。
常用命令
- 最开始的时候执行add-migration init(定义的初始化的名称) script-migration命令,用来生成增量脚本。
- 后面执行add-migration updatePda(本次增量脚本的名称) script-migration init(上一次更新的脚步名称),用来生成增量脚本。
读写分离
示意图
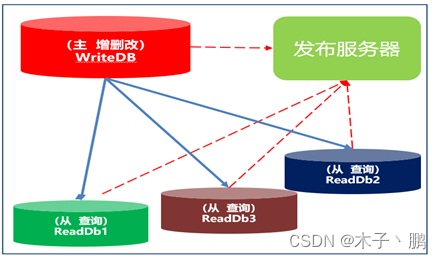
理解
- 主库第一次发布,是把数据的结构,通过镜像文件发布到发布服务器。
- 多个从库订阅发布服务器,通过镜像拷贝把数据库结构生成从库数据库。
- 后面主库的更新,新增,修改,删除操作都会生成日志到发布服务器。
- 从库在发布服务器订阅得到日志之后,通过日志恢复数据。
EFCore连接多个数据库
示意图
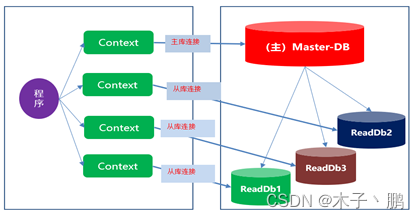
多个Context对应多个数据库
- 多个Context对应多个连接,需要建立多个Context类文件。
- 数据库读写分离之后是无法确定从库数量的,每增加一个从库,就需要修改一次代码,这是需要避免 的。
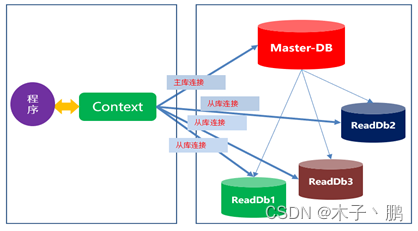
一个Context对应多个数据库
如果是增删改,就使用主库的数据库连接,如果是查询就使用从库中任意一个数据库连接。
实现思路
抽象工厂
示意图


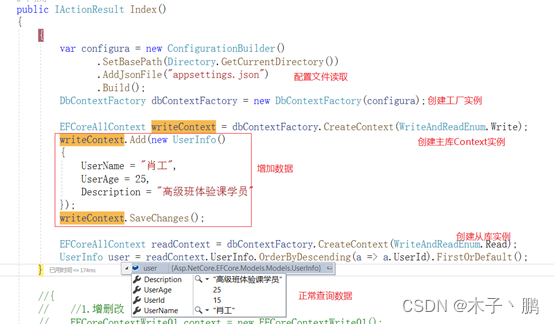
弊端
工厂模式确实能够创建不同的Context实例,但是确增加了创建工厂的成本,可以通过IOC容器来创建工厂的实例。
抽象工厂+依赖注入



EF和EFCore的区别
在EFCore中主要实现了批量更新
EFCore和ADO.Net区别
- 原生的ADO.Net对内存的消耗比较小。
- EFCore对内存的消耗比较大,因为会在内存中生成实体和数据库表的映射视图,性能比原生的ADO.Net 稍微低一些。
- 用原生的ADO.Net灵活性也比较高,SQL语句编写起来比较灵活,适合一些小项目。
- EFCore对底层的SQL语句封装的比较狠,各种扩展方法支持增删改查,开发效率比较高。
- 如果项目比较大,用原生的ADO.Net去开发,一个非常简单的SQL语句都有可能需要去编写,而且大 部分编写的SQL语句可能除了表名和字段名不相同,SQL的关键字都是相同的,写的多了是非常累人 的。如果数据库中某张表的某个字段名被修改了,用原生的ADO.Net开发的项目,需要改动的地方是 非常多的。
EFCore扩展ADO.Net

















 3437
3437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











