







目录
一、图的基本概念和术语
图: 多对多,必须有点,可以没有边。边有方向为有向图
完全图: 任意两个点之间都有边相连。
n个顶点的图,完全无向图有n(n-1)/2个边,完全有向图有n(n-1)个边。有向图的边也叫弧。弧用尖括号表示<>


两个顶点有连线,则点与线关联。


简单路径是对于一条路径单独而说的,就是不走多余的路的就是简单路径,起始点到终点不用重复经过任何顶点就是简单路径。
简单回路是简单路径的环状。
连通图是无向图,强连通图是有向图:任意两点之间存在路径就是连通(不是任意两点有连线,只要求存在路径,可以经过别的顶点),有向图是否连通要考虑方向。

图中拿出一部分边一部分点构成的就是子图。



生成树就是把无向图的点都保留,尽量删除较多边之后仍然连通的子图。

二、图的存储结构
图没有顺序存储结构,但可以借助二维数组来表示元素间的关系。
故介绍一种数组表示法和三种链式存储结构(多重链表),重点是邻接矩阵和邻接表。
1,邻接矩阵表示法
(1)无向图的邻接矩阵:对角线都是0;两个点互为邻接,故是对称矩阵;矩阵中第i行(列)中1的个数=该顶点的度;完全图的对角线为0,其余元素都为1。

(2)有向图的邻接矩阵:按行来看,顶点发出的弧记为1,否则为0,几条边就有几个1。(行为起点,列为终点,起点才会记录,所以可以是不对称的矩阵)
有向图的度=该顶点的行度+该顶点的列度

(3)网(有权图)的邻接矩阵:

(4)采用邻接矩阵表示法创建无向网:

极大值就是∞的意思,构造邻接矩阵时,有权值的地方更新为权值,其余保持不变(仍为∞)。根据输入的边所关联的顶点来确定顶点的下标,根据输入权值来修改邻接矩阵对应的元素值(对应权值)。





(5)零阶矩阵表示法的优缺点:
- 优点

- 缺点
行列固定,插入删除不方便;矩阵大小只跟顶点个数有关,跟边数无关,时间=空间效率O(n2)。

2,邻接表表示法

这里的一维数组(头结点)跟邻接矩阵不同在于:每个元素都有两个成员,分别是data域和firstarc(指针域指向第条个边边结点的地址);前述方法用邻接矩阵存放边,边用结点表示。表结点:数据域存放与头结点邻接的结点下标(从0开始),头结点有几个邻接的结点,就连几个表结点。有权值时,表结点增加一个域表示权值。
(1)无向图的邻接表: 表不唯一(邻接的点在表结点的顺序不唯一);空间效率O(n+2e);有几个表结头就是度为几;

(2)有向图的邻接表: 相对于无向图,只记录出度边。空间效率O(n+e)。出度边=该顶点的表结点个数,但是入度边需要遍历整个表。
或者只存储入度边(逆邻接表)。
(3)建立邻接表的算法:
-
定义结点类型和数组类型:

-
边结点的结构

-
图的结构定义

-
算法思想

-
算法(头插法)


(4)邻接表优缺点+和邻接矩阵的关系:
-
优点

-
缺点
对于有向图需要构建逆邻接表和邻接表搭配使用才能方便计算度。
不方便检查任意一对顶点间是否存在边。 -
关系


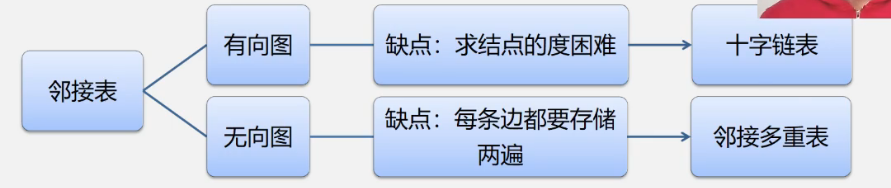
3,十字链表(好绕啊,头都晕了)
在邻接表基础上,对头结点增加入度指针域;对弧结点增加指针域,包含弧尾(箭头起点)+弧头(箭头终点)+下一条弧头相同的边(入度边)+下一条弧尾相同的边的指针(出度边)

4,邻接多重表
几条边就几个边结点。每个结点两个指针域,分别指向与对应指针域前面结点相关联的。对于网增加权值信息。


三、图的遍历

访问过程可能会重复访问,

辅助数组相当于地图上打勾表示已经看过
1,深度优先搜索遍历(DFS)
DFS算法思想: 一条道走到黑。连通图的深度优先遍历类似树的先根遍历。

DFS时间复杂度:

邻接矩阵表示图的深度优先算法:
设辅助数组初始元素都为0,访问邻接矩阵时,首先对起点a处一行元素从左往右找第一个不为0的元素b(说明是邻接点),然后判断辅助数组相应元素b是否为1,为1说明已经访问过,为0则可以访问,并更新数组该值为1;然后转到邻接矩阵中b的那一行,从左往右找出第一个未被访问的邻结点,依次进行;直到某个元素处已经没有未被访问的邻结点,就后退一个结点,找其下一个未被访问的邻结点,然后重复深度访问,直到退回到邻结点。

对于非连通图,先深度遍历一个子图,再在下一个子图中任选一个未被访问的结点继续深度遍历
2,广度优先搜索遍历 (BFS)
一次访问该结点处所有邻结点(一层一层,一圈一圈的放大已访问范围)

邻接表表示图的广度优先遍历:
用队列存储存储第一个要访问的呃结点,然后将一维数组相应位置置为1之后,头结点出队;由头结点出发找与其相连的所有表结点(表结点中记录了与其邻接的结点)将所有表结点入队之后,将一维数组相应处置1;将第二个被访问的结点出队,找到该结点在邻接表中作为头结点的所有表结点入队,重复操作,直到队列为空。

时间效率:

两种算法比较:

四、图的应用(重要)
1,最小生成树
生成树: 一个图的所有顶点连在一起(连通子图)却不构成回路(其实就是树结构)
一个图的生成树不唯一;n个顶点的生成树有n-1条边,反过来不成立。
无向图的生成树: 对图遍历经过的边连起来。可分为深度优先生成树和广度优先生成树。

最小生成树:

MST性质: 把权值最小的边包含在最小生成树中


Prim算法: 先将一个顶点并入U,在U和V-U中有相连的所有边中找权值最小的边,并将该边及顶点并入U。

kruscal算法: 先将所有顶点加入生成树,然后将边按权值排序,选最小的边加入生成树(且不能构成环)

比较:

2,最短路径

dijkstra算法:(好复杂)找一个顶点分别到其余顶点的距离最小的路径
初始化时,先找到所有能从源点v0直接到达的结点路径vk(vk代表≥1个结点),无法直接到达则记为∞;找到源点v0直接相连路径中最短的一条u(u∈vk,将其加入S,代表已找到最短路径),然后对剩余在T中的结点路径进行调整,看经过v0到u这个最短路径能否找到其他结点的更短的路径,修改路径值(此时只看权值,可以不是直达,v0到u就是一个过渡的量)



Floyd算法:所有顶点之间最短路径(可以对每个顶点用dijkstra算法,不过太复杂)
加入新顶点后,看剩下每一个顶点经过新顶点后到别的顶点的路径会不会变小


3,拓扑排序
有向无环图:在有向图的基础上不构成环
AOV解决拓扑排序,AOE解决关键路径问题

AOV网的特点:

拓扑排序: 将有向无环图变成拓扑序列


AOV网的拓扑序列不唯一,序列中任一点的前驱结点必然排在其前面。在对AIV网进行拓扑排序的过程中,若网中所有顶点都在拓扑序列中,则AOV网中必然无环(若网中有环,则无法将网中所有顶点加入拓扑序列)
4,关键路径

源点:工程开始(入度为0)
汇点:工程结束(出度为0)
关键路径:源点到汇点路径长度最长的路径,路径长度为路径上各活动持续时间之和。

先求事件和活动的最早+最晚发生时间,然后计算时间余量来找到关键活动,再求关键路径
ve从前往后推事件发生的最小值,多条弧汇入时取最大;vl从后往前推事件发生的最大值,多条弧头(箭头)时取最小
活动的最早时间=弧尾事件(起始点)的最早时间
活动的最晚时间=弧头事件的最晚时间-活动时间(做差)
(弧头是箭头,是终点;弧尾是起点,有点混)


















 6038
6038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









