







C/C++、OS、网络面经
- Q. 结构体大小(深信服)
- Q. 什么是内存对齐?为什么要内存对齐?(深信服)
- Q. 能否用memcmp比较 struct中成员(深信服)
- Q. C语言中的堆和栈(深信服、雷火)
- Q. static关键字(深信服,雷火)
- Q. 静态成员函数删除static之后能正常运行吗(深信服)
- Q. 野指针是什么?(深信服、雷火)
- Q. 内存泄露是什么?有什么危害?如何避免?(雷火)
- Q6. 数组和链表分别用在什么场景
- Q7. 指针函数和函数指针
- Q. C++多态
- Q. 如何理解虚函数(深信服)
- Q. 虚函数在C++底层如何实现的(虚函数表)(深信服)
- Q. 介绍一下虚函数表(雷火)
- Q. C++构造函数和析构函数中可以调用虚函数吗?(雷火)
- Q. 为什么构造函数不可以是虚函数(鹅厂)
- Q. map底层是怎么实现的?冲突机制是怎样的?(深信服、鹅厂)
- Q. C++ set实现原理(深信服)
- Q. 为何map和set的插入删除效率比用其他序列容器高
- Q. 对map和set,为何每次insert之后,以前保存的iterator不会失效
- Q. 为何map和set不能像vector一样有个reserve函数来预分配数据
- Q. 当数据元素增多时(10000和20000个比较),map和set的插入和搜索速度变化如何?
- Q. vector和list的原理(深信服)
- Q. select、poll、epoll(深信服、雷火、鹅厂)
- Q12. 惊群问题
- Q. TCP头部中有哪些字段(雷火)
- Q. TCP头部多大?(雷火)
- Q. TCP三次握手、四次握手
- Q. 为什么A在WAIT-TIME状态必须等待2MSL的时间?
- Q. 为什么建立连接是三次握手,而关闭连接却是四次挥手呢?
- Q. TCP 为什么三次握手而不是两次握手?(鹅厂)
- Q. 三次握手最后一个包丢了会怎样?(鹅厂)
- Q. TCP四种定时器
- Q. TCP重传机制(雷火)
- Q. UDP、TCP(深信服)
- Q. TCP传输大数据(鹅厂)
- Q. TCP拥塞控制、流量控制(深信服、雷火)
- Q. 如何把UDP变得可靠起来(鹅厂)
- 介绍一下QUIC (鹅厂)
- Q. 快排优化、二路快排、三路快排
- Q. 头文件的作用,里面放什么?(深信服、雷火)
- Q17. 一个程序在执行main函数前干了啥
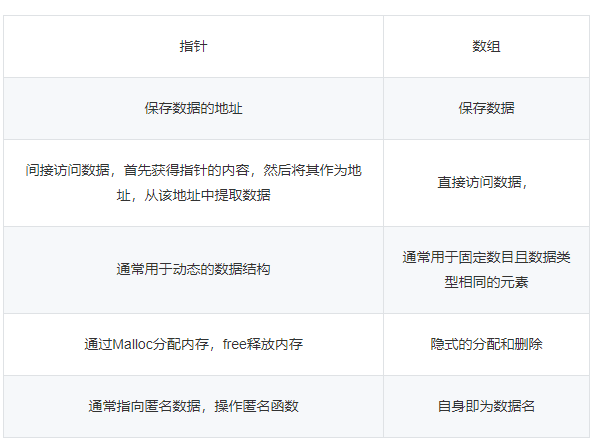
- Q18. new和malloc的区别
- Q19. 如果new之后用free会怎样
- Q. delete该用方括号的时候不用怎么样
- Q. 在类的成员函数中能不能调用delete this?(雷火)
- Q21. 访问数组下标为-1的位置会怎么样?(深信服)
- Q28. C++内联函数(深信服)
- Q29. 父类指针或引用指向子类对象,可以访问子类成员吗(深信服)
- Q30. 如何判断一段程序是由C编译程序还是C++编译程序编译的?(深信服)
- Q31. 两个栈实现队列(深信服)
- Q32. 最小时间复杂度匹配子串(深信服)
- Q33. 操作系统中的消费者/生产者模型(深信服)
- Q34. 互斥锁(深信服)
- Q35. 哈希表原理及冲突解决(深信服)
- Q. 哈希的时间复杂度(鹅厂)
- Q. 虚拟地址空间由哪些组成(深信服)
- Q. 一个指针为什么是四字节(深信服)
- Q. Int型指针指向char数组"abcd" 取int*的值是多少(深信服)
- Q. 大端小端?操作系统一般是大端还是小端?int i = 1 在内存中怎么存的?(雷火)
- Q. 带参宏定义(深信服)
- Q. C++ explicit关键字(深信服)
- Q. 对一个数组,频繁查找子区间的和(深信服)
- Q. 对一个矩阵,频繁查找子区域的元素和(深信服)
- Q. 互斥对象(深信服)
- Q. 关键字const(深信服)
- Q. 套接字编程(深信服)
- Q. 排序(雷火)
- Q. C++内存分布(雷火)
- Q. 进程地址空间是怎么样的?(雷火)
- Q. 说一说c++中四种cast转换(雷火)
- Q. 虚继承(雷火)
- Q. 请说一下C/C++ 中指针和引用的区别?(雷火)
- Q. 拷贝构造函数(雷火)
- Q. 拷贝构造函数参数是什么样的 (雷火)
- Q. 类没声明拷贝构造函数时有没有拷贝构造函数,深拷贝浅拷贝?简单分析一下深拷贝和浅拷贝区别(雷火)
- Q. 模板类是编译时确定还是运行时确定?(雷火)
- Q. 为什么C++调用C函数要用extern “C”?(雷火)
- Q. linux下可执行文件是什么格式?介绍一下这个文件格式(雷火)
- Q. 操作系统有哪些锁?(雷火、鹅厂)
- Q. 介绍一下C++的智能指针(雷火)
- Q. 请你回答一下智能指针有没有内存泄露的情况
- Q. 请你来说一下智能指针的内存泄漏如何解决
- Q. 智能指针怎样线程安全?(雷火、鹅厂)
- Q. web server里长链接怎么做的?(雷火)
- Q. MYSQL中怎么查看查询性能?
- Q. Nagle算法(雷火)
- Q. shutdown()和close()有什么区别?(雷火)
- Q. C++11新特性(雷火)
- Q. 一般操作系统页的大小?(雷火)
- Q. 两个不同进程的指针有可能指向同一个地址吗?(雷火)
- Q. vector push_back时间复杂度?(雷火)
- Q. 为什么windows vector是1.5倍,linux是2倍(鹅厂)
- Q. 打怪掉装备,1000种掉落物,每个掉落物有自己的概率,加起来是1,怎么随机掉一个装备出来?(雷火)
- Q. 贪心算法的思路?DP和贪心不同?贪心的场景,DP的场景?(雷火)
- Q. 一个包含n个节点的四叉树,每个节点都有四个指向孩子节点的指针,这4n个指针中有多少个空指针?(雷火)
- Q. 有一个算法的递推关系式为:T(n) = 9 T(n / 3) + n,则该算法的时间复杂度为()(雷火)
- Q. 内核空间是使用虚拟内存还是物理内存?(雷火)
- Q. brk()是申请的连续还是非连续虚拟内存?申请2k的内存的具体过程?(雷火)
- Q. 实现auto_ptr(雷火)
- Q. 进程和线程的区别(雷火)
- Q. 物理内存、虚拟内存(雷火)
- Q. 线程的栈是怎么创建的?如果一个进程有100个线程,那么这个进程占多大物理空间?(雷火)
- Q. 怎么编程实现一个异步函数?(雷火)
- Q. 阻塞非阻塞的区别,阻塞IO和非阻塞IO在写文件描述符时有什么不同?(雷火)
- Q. C从源文件到可执行文件有哪些步骤?(雷火)
- Q. 协程(雷火、鹅厂)
- Q. 线程上下文(雷火)
- Q. 进程通信、线程通信(雷火)
- Q. 你认为MQ有什么用?(雷火)
- Q. 多进程编程,父进程打开了一个文件描述符,fork一个子进程,子进程调用read,此时父进程再调用read从哪开始读(雷火)
- Q. 函数返回值可以是引用么?(雷火)
- Q. 1个6L的水杯和一个5L的水杯,问能精确打多少升水?(雷火)
- Q. 在公司局域网上ping www.taobao.com没有涉及到的网络协议是()(雷火)
- Q. 说一下C++和C的区别
- Q. 给定三角形ABC和一点P(x,y,z),判断点P是否在ABC内,给出思路并手写代码
- Q. 请回答一下数组和指针的区别
- Q. 进程切换上下文细节(鹅厂)
- Q. 线程切换上下文细节(鹅厂)
- Q. 解释型语言和编译型语言的区别(鹅厂)
- Q. STL底层内存分配(鹅厂)
- Q. 12个瓶子,其中有一个不知道轻重,你如何查出来(鹅厂)
- Q. 某个线程CPU占比高,你如何排查出问题(鹅厂)
- Q. TCP/IP议栈的每一层的作用分别是什么?(鹅厂)
- Q. HTTPs 如何保证安全性?(鹅厂)
- Q. 平衡二叉树删除和插入的时间复杂度(鹅厂)
- Q. HTTP请求过程(鹅厂)
- Q. 1000个苹果分10个箱装(鹅厂)
- Q. 进程挂了共享内存是否还存在,为什么?(鹅厂)
- Q. 数据包MTU(最大传输单元)
- Q. 自旋锁、悲观锁、乐观锁(鹅厂)
- Q. volatile关键字(鹅厂)
- Q. 用户态和内核态(C++)
Q. 结构体大小(深信服)
Q. 什么是内存对齐?为什么要内存对齐?(深信服)
结构体的sizeof涉及到字节对齐问题
为什么需要字节对齐?计算机组成原理教导我们这样有助于加快计算机的取数速度,否则就得多花指令周期了。
字节对齐的细节和编译器的实现相关,但一般而言,满足三个准则:
1) 结构体变量的首地址能够被其最宽基本类型成员的大小所整除。
2) 结构体的每个成员相对于结构体首地址的偏移量(offset)都是最宽基本类型成员大小的整数倍,如有需要,编译器会在成员之间加上填充字节(internal adding)。
3) 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要,编译器会在最末一个成员后加上填充字节(trailing padding)。
关于pragma pack的使用
例如:
#pragma pack(1)
struct sample
{
char a;
double b;
};
#pragma pack()
注:若不用#pragma pack(1)和#pragma pack()括起来,则sample按编译器默认方式对齐(成员中size最大的那个)。即按8字节(double)对齐,则sizeof(sample)==16.成员char a占了8个字节(其中7个是空字节);若用#pragma pack(1),则sample按1字节方式对齐sizeof(sample)==9.(无空字节),比较节省空间啦,有些场和还可使结构体更易于控制。
应用实例
在网络协议编程中,经常会处理不同协议的数据报文。一种方法是通过指针偏移的方法来得到各种信息,但这样做不仅编程复杂,而且一旦协议有变化,程序修改起来也比较麻烦。在了解了编译器对结构空间的分配原则之后,我们完全可以利用这一特性定义自己的协议结构,通过访问结构的成员来获取各种信息。这样做,不仅简化了编程,而且即使协议发生变化,我们也只需修改协议结构的定义即可,其它程序无需修改,省时省力。下面以TCP协议首部为例,说明如何定义协议结构。其协议结构定义如下:
#pragma pack(1) // 按照1字节方式进行对齐
struct TCPHEADER
{
short SrcPort; // 16位源端口号
short DstPort; // 16位目的端口号
int SerialNo; // 32位序列号
int AckNo; // 32位确认号
unsigned char HaderLen : 4; // 4位首部长度
unsigned char Reserved1 : 4; // 保留6位中的4位
unsigned char Reserved2 : 2; // 保留6位中的2位
unsigned char URG : 1;
unsigned char ACK : 1;
unsigned char PSH : 1;
unsigned char RST : 1;
unsigned char SYN : 1;
unsigned char FIN : 1;
short WindowSize; // 16位窗口大小
short TcpChkSum; // 16位TCP检验和
short UrgentPointer; // 16位紧急指针
};
#pragma pack()
Q. 能否用memcmp比较 struct中成员(深信服)
不能,主要是考虑到是struct的字节对齐
Q. C语言中的堆和栈(深信服、雷火)
C语言程序经过编译连接后形成编译、连接后形成的二进制映像文件由栈,堆,数据段(由三部分部分组成:只读数据段,已经初始化读写数据段,未初始化数据段即BBS)和代码段组成
栈区
由编译器自动分配释放,存放函数的参数值、局部变量的值等。其操作方式类似于数据结构中的栈。每当一个函数被调用,该函数返回地址和一些关于调用的信息,比如某些寄存器的内容,被存储到栈区。然后这个被调用的函数再为它的自动变量和临时变量在栈区上分配空间,这就是C实现函数递归调用的方法。每执行一次递归函数调用,一个新的栈框架就会被使用,这样这个新实例栈里的变量就不会和该函数的另一个实例栈里面的变量混淆。
堆区
用于动态内存分配。一般由程序员分配和释放,若程序员不释放,程序结束时有可能由OS回收。
区别
(1)申请方式和回收方式不同
栈由系统自动分配,堆需程序员自己申请,并指明大小,并由程序员进行释放。
栈是向低地址扩展的数据结构,是一块连续的内存区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,当申请的空间超过栈的剩余空间时,将提示溢出。因此,用户能从栈获得的空间较小。
堆是向高地址扩展的数据结构(它的生长方向与内存的生长方向相同),是不连续的内存区域。因为系统是用链表来存储空闲内存地址的,且链表的遍历方向是由低地址向高地址。由此可见,堆获得的空间较灵活,也较大。
(2)申请后系统的响应
栈:只要栈的空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的free语句才能正确的释放本内存空间。另外,找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
对于堆来讲,频繁的malloc/free势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈就不会存在这个问题。
(3)存储内容
栈: 在函数调用时,第一个进栈的是主函数中函数调用后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。 当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
(4)存取效率
栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。
堆则是C/C++函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
Q. static关键字(深信服,雷火)
(1) 全局静态变量
在全局变量前加上关键字static,全局变量就定义成一个全局静态变量.
全局静态变量静态存储区,在整个程序运行期间一直存在。
初始化:未经初始化的全局静态变量会被自动初始化为0(自动对象的值是任意的,除非他被显式初始化);
作用域:全局静态变量在声明他的文件之外是不可见的,准确地说是从定义之处开始,到文件结尾。
(2)局部静态变量
在局部变量之前加上关键字static,局部变量就成为一个局部静态变量。
内存中的位置:静态存储区
初始化:未经初始化的局部静态变量会被自动初始化为0(自动对象的值是任意的,除非他被显式初始化);
作用域:作用域仍为局部作用域,当定义它的函数或者语句块结束的时候,作用域结束。但是当局部静态变量离开作用域后,并没有销毁,而是仍然驻留在内存当中,只不过我们不能再对它进行访问,直到该函数再次被调用,并且值不变
(3)静态函数
在函数返回类型前加static,函数就定义为静态函数。函数的定义和声明在默认情况下都是extern的,静态函数只是在声明他的文件当中可见,不能被其他文件所用
静态函数的实现使用static修饰,那么这个函数只可在本cpp内使用,不会同其他cpp中的同名函数引起冲突;
warning:不要在头文件中声明static的全局函数,不要在cpp内声明非static的全局函数,如果你要在多个cpp中复用该函数,就把它的声明提到头文件里去,否则cpp内部声明需加上static修饰;
(4)类的静态成员
在类中,静态成员可以实现多个对象之间的数据共享,并且使用静态数据成员还不会破坏隐藏的原则,保证了安全性。因此,静态成员是类的所有对象中共享的成员,而不是某个对象的成员。对多个对象来说,静态数据成员只存储一处,供所有对象共用
(5) 类的静态函数
静态成员函数和静态数据成员一样,它们都属于类的静态成员,它们都不是对象成员。因此,对静态成员的引用不需要用对象名。
在静态成员函数的实现中不能直接引用类中说明的非静态成员,可以引用类中说明的静态成员(这点非常重要)。如果静态成员函数中要引用非静态成员时,可通过对象来引用。 从中可看出,调用静态成员函数使用如下格式:<类名>::<静态成员函数名>(<参数表>)
Q. 静态成员函数删除static之后能正常运行吗(深信服)
首先给出答案是:不能
举个例子
//定义Student类
#include <iostream>
class Student
{
public:
//定义构造函数
Student(int n,int a,float s):num(n),age(a),score(s){ }
void total();
//声明静态成员函数
// 删除static前 static float average();
float average();
private:
int num;
int age;
float score;
//静态数据成员,累计学生的总分
static float sum;
//静态数据成员,累计学生的人数
static int count;
};
//在全局作用域对静态数据成员初始化,如果不赋予初值,则使用其默认值零
float Student::sum;
int Student::count;
//定义非静态成员函数
void Student::total()
{
//累加总分
sum+=score;
//累计已统计的人数
count++;
}
//定义静态成员函数
float Student::average()
{
return(sum/count);
}
int main()
{
Student stud[3]={
//定义对象数组并初始化
Student(1001,18,70),
Student(1002,19,78),
Student(1005,20,98)
};
int n;
std::cout<<"please input the number of students: ";
//输入需要求前面多少名学生的平均成绩
std::cin>>n;
//调用3次total函数
for(int i=0;i<n;i++)
{
stud[i].total();
}
//调用静态成员函数
std::cout<<"the average score of "<<n<<" students is "<<Student::average( )<<std::endl;
return 0;
}
运行之后显示报错,错误指在std::cout<<"the average score of "<<n<<" students is "<<Student::average( )<<std::endl;,错误信息为 cannot call member function ‘float Student::average()’ with
下面我们给出个总结性的答案:
因为c++里静态函数即可以使用类名::静态方法名的方式访问,也可以使用对象.静态方法名的方式访问。
所以,
如果代码里都是使用对象.静态方法名来访问静态成员函数的,则删除后程序能正常运行。
如果代码里有使用类名::静态方法名来访问静态成员函数的,则删除后程序不能通过编译。
最后我们来说说理由:
先看这篇博客 关于错误信息:cannot call member function ’ ’ without object,也就说当静态成员函数删除static后就成为了普通成员函数,这时需要定义一个对象才能调用成员函数。
到这为止就说明了为什么不能运行的理由了。
当然如果你好奇为什么变成静态成员函数就可以不用定义一个对象就能调用的话继续看哦!
看看这篇博客 C++静态成员变量和静态成员函数使用总结
就是说静态成员函数在类没有实例化的时候就存在,所以可以直接用类名::静态方法名调用
Q. 野指针是什么?(深信服、雷火)
野指针”的成因主要有:
1)指针变量没有被初始化。任何指针变量刚被创建时不会自动成为NULL指针,它的缺省值是随机的,它会乱指一气。所以,指针变量在创建的同时应当被初始化,要么将指针设置为NULL,要么让它指向合法的内存
char *p; //此时p为野指针
2)指针p被free或者delete之后,没有置为NULL,让人误以为p是个合法的指针
char *p=new char[10]; //指向堆中分配的内存首地址,p存储在栈区
cin>> p;
delete []p; //p重新变为野指针
3)指针操作超越了变量的作用范围
char *p=new char[10]; //指向堆中分配的内存首地址
cin>> p;
cout<<*(p+10); //可能输出未知数据
Q. 内存泄露是什么?有什么危害?如何避免?(雷火)
什么是内存泄漏(memory leak)?
指由于疏忽或错误造成程序未能释放已经不再使用的内存的情况。内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,失去了对该段内存的控制,因而造成了内存的浪费。
对于C和C++这种没有Garbage Collection 的语言来讲,我们主要关注两种类型的内存泄漏:
- 堆内存泄漏(Heap leak)。对内存指的是程序运行中根据需要分配通过malloc,realloc new等从堆中分配的一块内存,再是完成后必须通过调用对应的 free或者delete 删掉。如果程序的设计的错误导致这部分内存没有被释放,那么此后这块内存将不会被使用,就会产生Heap Leak.
- 系统资源泄露(Resource Leak)。主要指程序使用系统分配的资源比如 Bitmap,handle ,SOCKET等没有使用相应的函数释放掉,导致系统资源的浪费,严重可导致系统效能降低,系统运行不稳定。
Q6. 数组和链表分别用在什么场景
数组应用场景:
数据比较少;经常做的运算是按序号访问数据元素;数组更容易实现,任何高级语言都支持;构建的线性表较稳定。
链表应用场景:
对线性表的长度或者规模难以估计;频繁做插入删除操作;构建动态性比较强的线性表。
Q7. 指针函数和函数指针
指针函数
其本质是一个函数,而该函数的返回值是一个指针
指针函数多用于链表、树的结构,用于返回一个指向目标节点的指针
函数指针
其本质是一个指针变量,该指针指向这个函数。总结来说,函数指针就是指向函数的指针。
声明格式:类型说明符 (*函数名) (参数)如下:
int (*fun)(int x,int y);
函数指针是需要把一个函数的地址赋值给它,有两种写法:
fun = &Function;
fun = Function;
取地址运算符&不是必需的,因为一个函数标识符就表示了它的地址,如果是函数调用,还必须包含一个圆括号括起来的参数表。
调用函数指针的方式也有两种:
x = (*fun)();
x = fun();
两种方式均可,其中第二种看上去和普通的函数调用没啥区别,如果可以的话,建议使用第一种,因为可以清楚的指明这是通过指针的方式来调用函数。当然,也要看个人习惯,如果理解其定义,随便怎么用都行啦。
Q. C++多态
多态是C++特性之一,多态性就是使用相同的接口实现不同的方法。多态性分为静态多态性和动态多态性。
在C++中,多态性的实现和联编(或称绑定)这一概念有关。一个源程序经过编译、链接,成为可执行文件的过程是把可执行代码联编在一起的过程。其中在编译时完成的联编称为静态联编(前期联编);而在运行时完成的联编称为动态联编(后期联编)。

静态多态性
静态多态性又可以称为编译时多态性,在C++中,静态多态性是通过函数重载和模板实现的。
例如函数重载机制,编译器会根据调用函数时实参的使用来确定调用的是哪个函数,如果有合适的函数可以调用就调,没有的话就会发出警告或者报错;而模板类和模板函数也是在编译时判断typename来调用不同的函数/类。
动态多态性
动态多态性又称为运行时多态性,它是在程序运行时根据基类的引用(指针)指向的对象来确定自己具体该调用哪一个类的虚函数。动态多态性是通过虚函数实现的。
动态多态的条件:
- 基类中必须包含虚函数,并且派生类中一定要对基类中的虚函数进行重写。
- 通过基类对象的指针或者引用调用虚函数。
虚函数
- 虚函数在C++中指被virtual关键字修饰的函数。
- 允许父类的指针调用子类的虚函数,子类当中的函数需要对父类的函数实现重写,注意重写的概念与重载不同,重写需要子类函数的函数名、参数、返回值均与父类函数相同,才可以实现重写(协变和析构函数除外)。
(这里解释一些什么是协变:基类(或者派生类)的虚函数返回基类(派生类)的指针(引用)) - 在子类中实现父类中的虚函数时,会告诉编译器不要静态链接到该函数,而是在程序中根据调用对象的类型来选择调用的函数,称为动态联编或后期绑定,也就是说一个类的虚函数的调用不是在编译时刻确定的,而是在运行时刻确定的。
- 如果子类的函数有virtual修饰,但是父类没有,会造成函数隐藏。
- 父类的析构函数应当是虚函数,这样的话在调用析构时,会先调用到对应子类的析构函数,再调用父类的析构函数。此时子类的析构函数和父类的析构函数由于函数名不同,看似不符合上面的重写规则,可以理解为在编译的时候对析构函数做了特殊的处理,可以达到依次析构的目的。
哪些函数不能定义为虚函数?
1)友元函数,它不是类的成员函数
2)全局函数
3)静态成员函数,它没有this指针
3)构造函数,拷贝构造函数,以及赋值运算符重载(可以但是一般不建议作为虚函数)
纯虚函数
- 在很多情况下,一个父类生成对象是不合理的,例如:动物作为父类不应该生成对象,但是作为动物的子类猫狗等可以生成对象。为了解决这个问题便引入纯虚函数。
- 编译器要求所有子类必须对纯虚函数有自己的实现方式,以实现多态性。
- 包含纯虚函数的类称为抽象类,抽象类不能生成对象。纯虚函数在派生类中重新定义以后,派生类才能实例化出对象。
- 定义纯虚函数的目的在于,使派生类仅仅只是继承函数的接口。
- 纯虚函数提供一个合理的缺省实现。所以类纯虚函数的声明就是在告诉子类的设计者,“你必须提供一个纯虚函数的实现,但我不知道你会怎样实现它”。
- 定义一个函数为虚函数不代表它没有实现,定义为纯虚函数才代表没有实现。
在成员函数(必须为虚函数)的形参列表后面写上=0,则成员函数为纯虚函数。
抽象类
- 带有纯虚函数的类称为抽象类,抽象类不能生成对象。
- 抽象类的主要作用是提供接口,这个接口是其所有子类的公共根,用来规范子类的函数定义,函数的具体实现将在每个子类中分别进行。
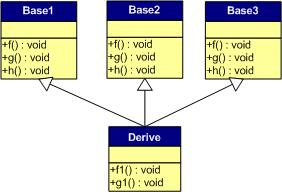
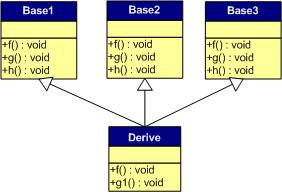
派生类虚表:
- 先将基类的虚表中的内容拷贝一份
- 如果派生类对基类中的虚函数进行重写,使用派生类的虚函数替换相同偏移量位置的基类虚函数
- 如果派生类中新增加自己的虚函数,按照其在派生类中的声明次序,放在上述虚函数之后
Q. 如何理解虚函数(深信服)
C++通过虚函数(virtual function)机制来支持动态联编(dynamic binding),并实现了多态机制。多态是面向对象程序设计语言的基本特征之一。在C++中,多态就是利用基类指针指向子类实例,然后通过基类指针调用子类(虚)函数从而实现“一个接口,多种形态”的效果。
Q. 虚函数在C++底层如何实现的(虚函数表)(深信服)
C++通过虚函数表和虚函数表指针来实现virtual function机制,具体而言:
- 对于一个class,产生一堆指向virtual functions的指针,这些指针被统一放在一个表格中。这个表格被称为虚函数表,英文又称做virtual table(vtbl)。
- 每一个对象中都添加一个指针,指向相关的virtual table。通常这个指针被称作虚函数表指针(vptr)。出于效率的考虑,该指针通常放在对象实例最前面的位置(第一个slot处)。每一个class所关联的type_info信息也由virtual table指出(通常放在表格的最前面)。
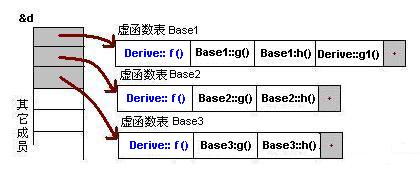
Q. 介绍一下虚函数表(雷火)
C++的虚函数(Virtual Function)是通过一张虚函数表(Virtual Table)来实现的。简称为V-Table。在这个表中,主要是一个类的虚函数的地址表,这张表解决了继承、覆盖(override)的问题,保证其能真实的反应实际的函数。这样,在有虚函数的类的实例中这张表被分配在了这个实例的内存中,所以当我们用父类的指针操作一个子类的时候,这张虚函数表就显得尤为重要了,他就像一个地图一样,指明了实际所应该调用的函数。
虚函数表创建的时间:在一个类构造的时候,创建这张虚函数表,而这个虚函数表是供整个类所共有的。虚函数表存储在对象最开始的位置。
- 无继承
- 一般继承(无虚函数覆盖)
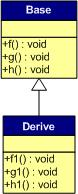
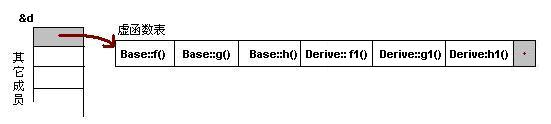
- 一般继承(有虚函数覆盖)
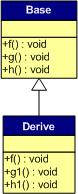
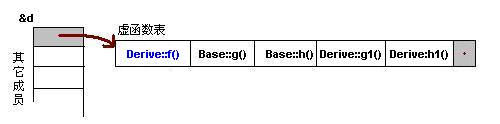
- 多重继承(无虚函数覆盖)

- 多重继承(有虚函数覆盖)
Q. C++构造函数和析构函数中可以调用虚函数吗?(雷火)
结论:
(1)从语法上讲,调用完全没有问题。
(2) 但是从效果上看,往往不能达到需要的目的。
理由:
构造函数的顺序是从基类开始构造->子类,如果在基类中调用虚函数,由于构造函数基类中仅存在自身,不会根据虚函数表的规则去调用。也就是在基类构造的过程中还没有构造派生类,虚函数表中派生类的函数并未加入进来,所以查找函数的时候只能找到基类的调用函数
Q. 为什么构造函数不可以是虚函数(鹅厂)
从存储空间角度看
虚函数相应一个指向vtable虚函数表的指针,这大家都知道,但是这个指向vtable的指针事实上是存储在对象的内存空间的。
问题出来了,假设构造函数是虚的。就须要通过 vtable来调用。但是对象还没有实例化,也就是内存空间还没有,怎么找vtable呢?所以构造函数不能是虚函数。
从使用角度
虚函数的作用在于通过父类的指针或者引用来调用它的时候可以变成调用子类的那个成员函数。
而构造函数是在创建对象时自己主动调用的,不可能通过父类的指针或者引用去调用(没有存在的必要)。因此也就规定构造函数不能是虚函数。
Q. map底层是怎么实现的?冲突机制是怎样的?(深信服、鹅厂)
map成员
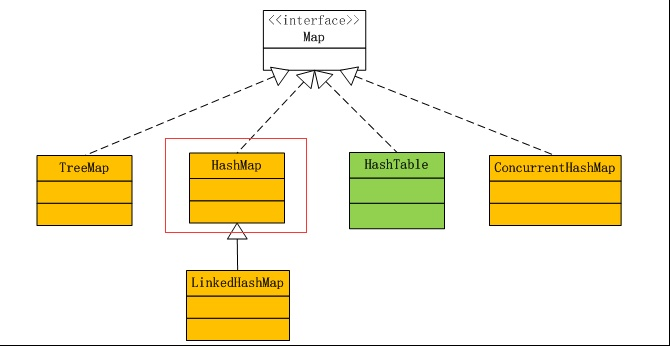
- TreeMap是基于树(红黑树)的实现方式,即添加到一个有序列表,在 O ( l o g n ) O(logn) O(logn)的复杂度内通过key值找到value,优点是空间要求低,但在时间上不如HashMap。C++中Map的实现就是基于这种方式
- HashMap是基于HashCode的实现方式,在查找上要比TreeMap速度快,添加时也没有任何顺序,但空间复杂度高。C++ unordered_map就是基于该种方式。
- HashTable与HashMap类似,只是HashMap是线程不安全的,HashTable是线程安全的,现在很少使用
- ConcurrentHashMap也是线程安全的,但性能比HashTable好很多,HashTable是锁整个Map对象,而ConcurrentHashMap是锁Map的部分结构
HashMap详解
HashMap简称哈希表,下面介绍下主要思想和流程。
HashMap在添加值时需要给定两个参数,一个是key,一个是value. 为了能很快的通过key值找到对应的value,因此有必要建立一个key值和内存指针的映射,举个简单的例子,如果说key值是int型,那么其实最简单的方式就是定义一个数组,以这个key值作为下标,value作为内存中的值。然而由于key值可能会很大,或者是string或着其他类型的值,因此就不能单纯的简单对应了,这时候就需要做一个转换。这个在Java和C#中是通过一个int HashCode()的函数实现的。具体的实现可能是通过地址、字符串或数字算出来的值,然后如果是自己定义的对象,则需要自己实现HashCode()和equal()。
注意,hashcode的实现需要满足以下要求:
- 如果两个对象equals相等,那么这两个对象的HashCode一定也相同
- 如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置
那么在计算出hashcode之后再怎么做呢,由于hashcode算出来的值可能很大,定义一个大小能包含所有hashcode的数组显然是不合理的。在实际的实现是这样的,事先定义一个大小为2的幂次方的数组(稍后解释为什么是2的幂次方)。为了能保证所有的hashcode都能对应到数组的下标,可以采用hashcode对数组大小(一般称为bucket)取余的方式。而具体的实现就是:
static int indexFor(int h,int length) {
return h & (length-1);
}
通过按位与运算巧妙的求得了余数,并且很大程度上减少了运算效率。但由于可能会有多个key值对应同一个index,为了避免冲突,其实每个数组元素里存储的是链表结构。当添加函数检测到index对应的元素已经有值了以后,它就会将key值和value作为子节点添加到该index所在元素的尾部节点。如果检测到key值相同,则更新value。
当链表的长度大于8后,会自动转为红黑树,方便查找。如果HashMap里的元素越来越多,那么冲突的概率会越来越大,因此有必要即时的对数组长度扩容。当HashMap中的元素个数超过数组大小(数组总大小length)*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过16*0.75=12(这个值就是代码中的threshold值,也叫做临界值)的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。扩容的操作是这样的:
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
这个就表示,每次扩容都是在原有的基础上 × 2 \times 2 ×2,这也就是为什么大小是2的幂次的原因。

红黑树
关于红黑树的细致内容可以参阅 红黑树
这里主要讲一下红黑树和AVL树的区别:
AVL树是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过1)。不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而旋转又非常耗时,由此我们可以知道AVL树适合用于插入与删除次数比较少,但查找多的情况。
由于维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树。当然,如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树。
平衡二叉树追求绝对平衡,条件比较苛刻,实现起来比较麻烦,每次插入新节点之后需要旋转的次数不能预知。
红黑树通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍,因此,红黑树是一种弱平衡二叉树(由于是弱平衡,可以看到,在相同的节点情况下,AVL树的高度低于红黑树),相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,我们就用红黑树。
红黑树放弃了追求完全平衡,追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。
Q. C++ set实现原理(深信服)
C++ STL 的 set 和 map 容器底层都是由红黑树(RB tree)来实现的
Q. 为何map和set的插入删除效率比用其他序列容器高
很简单,因为对于关联容器来说,不需要做内存拷贝和内存移动。说对了,确实如此。map和set容器内所有元素都是以节点的方式来存储,其节点结构和链表差不多,指向父节点和子节点。因此插入的时候只需要稍做变换,把节点的指针指向新的节点就可以了。删除的时候类似,稍做变换后把指向删除节点的指针指向其他节点就OK了。这里的一切操作就是指针换来换去,和内存移动没有关系。
Q. 对map和set,为何每次insert之后,以前保存的iterator不会失效
看见了上面答案的解释,你应该已经可以很容易解释这个问题。
iterator这里就相当于指向节点的指针,内存没有变,指向内存的指针怎么会失效呢(当然被删除的那个元素本身已经失效了)。
相对于vector来说,每一次删除和插入,指针都有可能失效,调用push_back在尾部插入也是如此。因为为了保证内部数据的连续存放,iterator指向的那块内存在删除和插入过程中可能已经被其他内存覆盖或者内存已经被释放了。即使是push_back,容器内部空间可能不够,需要一块新的更大的内存,只有把以前的内存释放,申请新的更大的内存,复制已有的数据元素到新的内存,最后把需要插入的元素放到最后,那么以前的内存指针自然就不可用了。
Q. 为何map和set不能像vector一样有个reserve函数来预分配数据
map和set内部存储的已经不是元素本身了,而是包含元素的节点
Q. 当数据元素增多时(10000和20000个比较),map和set的插入和搜索速度变化如何?
在map和set中查找是使用二分查找,如果有10000个元素,最多比较的次数为 l o g 2 10000 log_210000 log210000,最多为14次;如果是20000个元素,最多不过15次。 当数据量增大一倍的时候,搜索次数只不过多了1次,多了1/14的搜索时间而已
Q. vector和list的原理(深信服)
Vector底层实现为:顺序表,相当于一个数组,但是与数组的区别为:内存空间的扩展
STL内部实现时,首先分配一个非常大的内存空间预备进行存储,即capacity()函数返回的大小,当超过此分配的空间时再整体重新放分配一块内存存储(通常会是两倍)
List底层实现为:带头节点的双向循环链表(优点:增删速度快,时间复杂度为O(1))
vector中的iterator在使用后就释放了,但是链表list不同,它的迭代器在使用后还可以继续用
使用场景
vector拥有一段连续的内存空间,因此支持随机访问,如果需要高效的随即访问,而不在乎插入和删除的效率,使用vector
list拥有一段不连续的内存空间,如果需要高效的插入和删除,而不关心随机访问,则应使用list
Q. select、poll、epoll(深信服、雷火、鹅厂)
- epoll_wait epoll_create epoll_ctl
- epoll原理详解及epoll反应堆模型
(缓冲区水位) - select 和 epoll的区别总结(重点关注LT和ET的区别)
- select,poll,epoll优缺点及比较
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
select(轮询)
该模型轮询各socket,不管socket是否活跃,随着socket数的增加,性能逐渐下降。
调用时轮询一次所有描述字,超时再轮询一次。如果没有描述字准备好,则返回0;中途错误返回-1;有描述字准备好,则将其对应位置为1,其他描述字置为0,返回准备好的描述字个数。
select 选择句柄的时候,是遍历所有句柄,也就是说句柄有事件响应时,select需要遍历所有句柄才能获取到哪些句柄有事件通知,因此效率是非常低。但是如果连接很少的情况下, select和epoll相比, 性能上差别不大。
poll
poll的机制与select类似,与select在本质上没有多大差别,管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是poll通过一个pollfd数组向内核传递需要关注的事件,故没有描述符个数的限制
epoll(触发)
设想一个场景:有100万用户同时与一个进程保持着TCP连接,而每一时刻只有几十个或几百个TCP连接是活跃的(接收TCP包),也就是说在每一时刻进程只需要处理这100万连接中的一小部分连接。那么,如何才能高效的处理这种场景呢?进程是否在每次询问操作系统收集有事件发生的TCP连接时,把这100万个连接告诉操作系统,然后由操作系统找出其中有事件发生的几百个连接呢?实际上,在Linux2.4版本以前,那时的select或者poll事件驱动方式是这样做的。
这里有个非常明显的问题,即在某一时刻,进程收集有事件的连接时,其实这100万连接中的大部分都是没有事件发生的。因此如果每次收集事件时,都把100万连接的套接字传给操作系统(这首先是用户态内存到内核态内存的大量复制),而由操作系统内核寻找这些连接上有没有未处理的事件,将会是巨大的资源浪费,select和poll就是这样做的,因此它们最多只能处理几千个并发连接。
而epoll不这样做,epoll在Linux内核中申请了一个简易的文件系统,把原先的一个select或poll调用分成了3部分:
epoll_create,调用epoll_create时建立一个epoll对象(在epoll文件系统中给这个句柄分配资源)epoll_ctl,调用epoll_ctl时,如果增加socket句柄,则检查在红黑树中是否存在,存在立即返回,不存在则添加到树干上,然后向内核注册回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表里epoll_wait,调用epoll_wait时立刻返回准备就绪链表里的数据即可
【什么叫申请了一个简易的文件系统?】
在内核里,一切皆文件,epoll就是使用了一个文件描述符来管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中。当你调用epoll_create时,就会在这个虚拟的epoll文件系统里创建一个file结点。当然这个file不是普通文件,它只服务于epoll
这样只需要在进程启动时建立 1 个epoll对象,并在需要的时候向它添加或删除连接就可以了,因此,在实际收集事件时,epoll_wait的效率就会非常高,因为调用epoll_wait时并没有向它传递全部的连接,内核也不需要去遍历全部的连接。
详细过程
当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关,即用于存储以后epoll_ctl传来的socket的红黑树和用于存储准备就绪的事件的双向链表。
struct eventpoll {
...
/*红黑树的根节点,这棵树中存储着所有添加到epoll中的事件,
也就是这个epoll监控的事件*/
struct rb_root rbr;
/*双向链表rdllist保存着将要通过epoll_wait返回给用户的、满足条件的事件*/
struct list_head rdllist;
...
};
所有添加到epoll中的事件都会与设备驱动程序建立回调关系,也就是说相应事件的发生时会调用这里的回调方法。这个回调方法在内核中叫做ep_poll_callback,它会把这样的事件放到上面的rdllist双向链表中。
在epoll中对于每一个事件都会建立一个epitem结构体,如下所示:
struct epitem {
...
//红黑树节点
struct rb_node rbn;
//双向链表节点
struct list_head rdllink;
//事件句柄等信息
struct epoll_filefd ffd;
//指向其所属的eventepoll对象
struct eventpoll *ep;
//期待的事件类型
struct epoll_event event;
...
}; // 这里包含每一个事件对应着的信息。
当调用epoll_wait检查是否有发生事件的连接时,只是检查eventpoll对象中的rdllist双向链表是否有epitem元素而已,如果rdllist链表不为空,则这里的事件复制到用户态内存(使用共享内存提高效率)中,同时将事件数量返回给用户。因此epoll_wait效率非常高。
epoll_ctl在向epoll对象中添加、修改、删除事件时,从rbr红黑树中查找事件也非常快,也就是说epoll是非常高效的,它可以轻易地处理百万级别的并发连接。

具体函数
epoll_create
int epoll_create(int size);
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大。需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值。
epoll_ctl
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
第一个参数epfd是epoll_create的返回值,第二个参数表示动作,用三个宏来表示:
EPOLL_CTL_ADD:注册新的fd到epfd中;
EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
EPOLL_CTL_DEL:从epfd中删除一个fd;
第三个参数是需要监听的fd,第四个参数是告诉内核需要监听什么事件。
epoll_wait
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create时的size
我们调用epoll_ wait时就相当于以往调用select/poll,但是这时却不用传递socket句柄给内核,因为内核已经在epoll_ctl中拿到了要监控的句柄列表。
QQ:select、poll、epoll,问哪个可移植性更好(雷火)
select的可移植性更好,在某些Unix系统上不支持poll
QQ:epoll水平触发、边缘触发(雷火)
LT 模式(水平触发,默认)只要有数据都会触发,缓冲区剩余未读尽的数据会导致epoll_wait返回。LT模式服务编写上的表现是:只要数据没有被获取,内核就不断通知你,因此不用担心事件丢失的情况。
ET模式(边缘触发)只有数据到来才触发,不管缓存区中是否还有数据,缓冲区剩余未读尽的数据不会导致epoll_wait返回;其效率非常高,在并发、大流量的情况下,会比LT少很多epoll的系统调用,因此效率高。 但是对编程要求高,需要细致的处理每个请求,否则容易发生丢失事件的情况。

QQ:epoll为什么要有ET触发模式?
如果采用LT模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率.。而采用ET这种边缘触发模式的话,当被监控的文件描述符上有可读写事件发生时,epoll_wait会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符。
QQ. 对比
select 的几大缺点是:
(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
(2)同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
(3)select支持的文件描述符数量太小了,默认是1024
epoll是如何解决上面三个问题的呢?
epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用schedule_timeout()实现睡一会,判断一会的效果)。
对于第三个缺点,epoll没有这个限制,它所支持的fd上限是最大可以打开文件的数目,这个数字一般远大于1024
select、poll、epoll之间的区别总结[整理] + 知乎大神解答
那是不是epoll一定比select高效啊
不是的,select适用于连接少,活动连接多的情况;而epoll适用于连接多,活动连接少的情况
QQ. epoll的timeout精度是最高的吗?是(不是)的话,为什么?(雷火)
是,epoll_wait(timeout)的误差一般是1/1000,主要是因为epoll中有一个专门用于存储准备就绪事件的链表,当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。有数据就返回,没有数据就sleep。
QQ. epoll的时间复杂度(雷火)
主要考虑epoll在底层实现建立了一个红黑树用于存放socket,而红黑树搜索、插入和删除时间复杂度都是 O ( l o g N ) O(logN) O(logN)
QQ. epoll_wait这个函数具体是干什么的(雷火)
epoll_wait用于等待事件的产生,其运行的原理是等侍注册在epfd上的socket fd的事件的发生,如果发生则将发生的soket fd和事件类型放入到events数组中。并且将注册在epfd上的socket fd的事件类型给清空,所以如果下一个循环你还要关注这个socket fd的话,则需要用epoll_ctl(epfd,EPOLL_CTL_MOD,listenfd,&ev)来重新设置socket fd的事件类型。这时不用EPOLL_CTL_ADD,因为socket fd并未清空,只是事件类型清空。这一步非常重要。
Q12. 惊群问题
Q. TCP头部中有哪些字段(雷火)

Q. TCP头部多大?(雷火)
TCP头部的最后一个选项字段是可变长的可选信息。这部分最多包含40字节,因为TCP头部最长是60字节(其中还包含前面讨论的20字节的固定部分)。
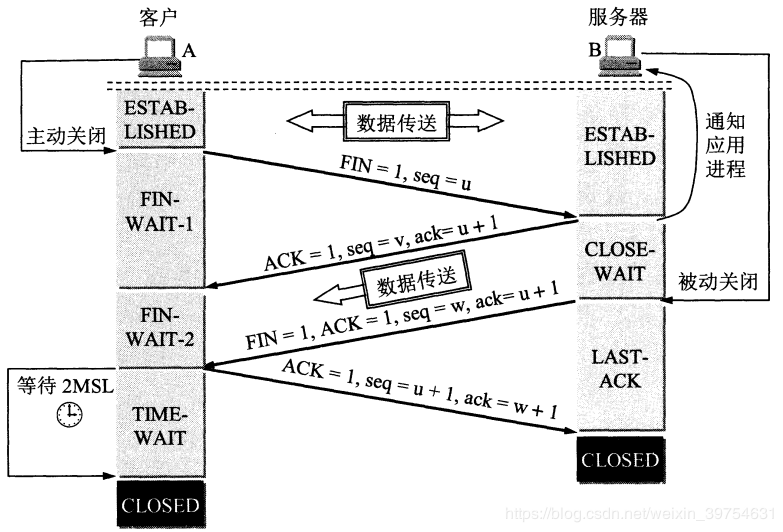
Q. TCP三次握手、四次握手
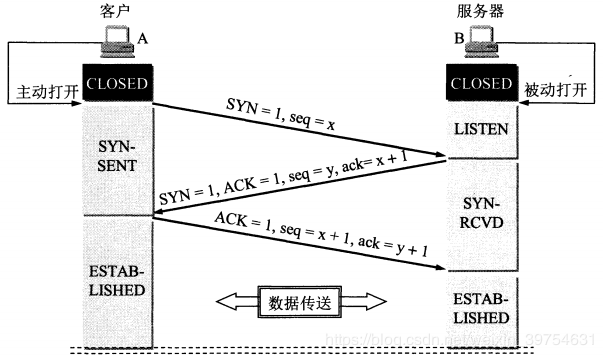
Q. 为什么A在WAIT-TIME状态必须等待2MSL的时间?
- 为了保证A发送的最后一个确认报文段能够达到B。这个ACK报文段可能丢失,因而使处在LAST-ACK状态的B收不到A发送的FIN+ACK报文段的确认。B会超时重传这个ACK+FIN报文段,而A就能在这个时间内收到这个重传的报文。接着A在再重传一次确认报文,并且重启2MSL计时器。使A和B都能正常的进入释放连接状态。
- 防止已经关闭的连接报文段出现在新的连接中。客户端发送完最后一个确认报文后,在这个2MSL时间中,就可以使本连接持续的时间内所产生的所有旧报文段都从网络中消失。这样新的连接中不会出现旧连接的数据报文。
Q. 为什么建立连接是三次握手,而关闭连接却是四次挥手呢?
这是由于服务端的LISTEN状态下收到SYN报文的建立连接请求后。它能够把ACK和SYN(ACK起应答作用。而SYN起同步作用)放在一个报文里来发送给客户端。
但关闭连接的时候,当服务端收到客户端的FIN报文段的时候,表示客户端没有数据发送给服务端了,但是服务端可能还有数据要发送给客户端,这时TCP连接处于半连接状态。当服务端没有数据再发送给客户端的时候就会向客户端发送一个FIN报文表示服务端要关闭连接,ACK和FIN一般不会分开发送。这个过程也是由于TCP的通信方式是全双工的,发送和接收方都需要发送FIN和ACK。
Q. TCP 为什么三次握手而不是两次握手?(鹅厂)
为了实现可靠数据传输, TCP 协议的通信双方, 都必须维护一个序列号, 以标识发送出去的数据包中, 哪些是已经被对方收到的。 三次握手的过程即是通信双方相互告知序列号起始值, 并确认对方已经收到了序列号起始值的必经步骤
如果只是两次握手, 至多只有连接发起方的起始序列号能被确认, 另一方选择的序列号则得不到确认
Q. 三次握手最后一个包丢了会怎样?(鹅厂)
Server 端
第三次的ACK在网络中丢失,那么Server 端该TCP连接的状态为SYN_RECV,并且会根据 TCP的超时重传机制,会等待3秒、6秒、12秒后重新发送SYN+ACK包,以便Client重新发送ACK包。
而Server重发SYN+ACK包的次数,可以通过设置/proc/sys/net/ipv4/tcp_synack_retries修改,默认值为5
如果重发指定次数之后,仍然未收到 Client 的ACK应答,那么一段时间后,Server自动关闭这个连接。
Client 端
在Linux C 中,Client 一般是通过 connect() 函数来连接服务器的,而connect()是在 TCP的三次握手的第二次握手完成后就成功返回值。也就是说 Client 在接收到SYN+ACK包,它的TCP连接状态就为 established (已连接),表示该连接已经建立。那么如果 第三次握手中的ACK包丢失的情况下,Client向Server端发送数据,Server端将以RST包响应,方能感知到Server的错误。
Q. TCP四种定时器
(1)重传定时器:
重传定时器:为了控制丢失的报文段或丢弃的报文段,也就是对报文段确认的等待时间。当TCP发送报文段时,就创建这个特定报文段的重传定时器,可能发生两种情况:若在定时器超时之前收到对报文段的确认,则撤销定时器;若在收到对特定报文段的确认之前定时器超时,则重传该报文,并把定时器复位;
重 传 时 间 = 2 ∗ R T T 重传时间=2*RTT 重传时间=2∗RTT
RTT的值应该动态计算。常用的公式是: R T T = p r e v i o u s R T T ∗ i + ( 1 − i ) ∗ c u r r e n t R T T RTT=previous RTT*i + (1-i)* current RTT RTT=previousRTT∗i+(1−i)∗currentRTT
i 的值通常取90%,即新的RTT是以前的RTT值的90%加上当前RTT值的10%.
Karn算法:对重传报文,在计算新的RTT时,不考虑重传报文的RTT。因为无法推理出:发送端所收到的确认是对上一次报文段的确认还是对重传报文段的确认。干脆不计入。
(2)坚持定时器:
专门对付零窗口通知而设立的
先来考虑一下情景:发送端向接收端发送数据包知道接受窗口填满了,然后接受窗口告诉发送方接受窗口填满了停止发送数据。此时的状态称为“零窗口”状态,发送端和接收端窗口大小均为0。直到接受TCP发送确认并宣布一个非零的窗口大小。但这个确认会丢失。
我们知道TCP中,对确认是不需要发送确认的。若确认丢失了,接受TCP并不知道,而是会认为他已经完成了任务,并等待着发送TCP接着会发送更多的报文段。但发送TCP由于没有收到确认,就等待对方发送确认来通知窗口大小。双方的TCP都在永远的等待着对方。
要打开这种死锁,TCP为每一个链接使用一个持久计时器。当发送TCP收到窗口大小为0的确认时,就坚持启动计时器。当坚持计时器期限到时,发送TCP就发送一个特殊的报文段,叫做探测报文。这个报文段只有一个字节的数据。他有一个序号,但他的序号永远不需要确认;甚至在计算机对其他部分的数据的确认时该序号也被忽略。
探测报文段提醒接受TCP:确认已丢失,必须重传。
坚持计时器的值设置为重传时间的数值。但是,若仍没有收到从接收端来的响应,则需发送另一个探测报文段,并将坚持计时器的值加倍和复位。重复此过程,直到这个值增大到门限值(通常是60秒)为止。在这以后,发送端每个60秒就发送一个探测报文,直到窗口重新打开。
(3)保活计时器
保活计时器使用在某些实现中,用来防止在两个TCP之间的连接出现长时间的空闲。假定客户打开了到服务器的连接,传送了一些数据,然后就保持静默了。也许这个客户出故障了。在这种情况下,这个连接将永远的处理打开状态。
要解决这种问题,在大多数的实现中都是使服务器设置保活计时器。每当服务器收到客户的信息,就将计时器复位。通常设置为两小时。若服务器过了两小时还没有收到客户的信息,他就发送探测报文段。若发送了10个探测报文段(每一个75秒)还没有响应,就假定客户除了故障,因而就终止了该连接。这种连接的断开当然不会使用四次握手,而是直接硬性的中断和客户端的TCP连接。
(4)时间等待计时器
时间等待计时器是在四次握手的时候使用的。
四次握手的简单过程是这样的:假设客户端准备中断连接,首先向服务器端发送一个FIN的请求关闭包(FIN=final),然后由established过渡到FIN-WAIT1状态。服务器收到FIN包以后会发送一个ACK,然后自己有established进入CLOSE-WAIT. 此时通信进入半双工状态,即留给服务器一个机会将剩余数据传递给客户端,传递完后服务器发送一个FIN+ACK的包,表示我已经发送完数据可以断开连接了,就这便进入LAST_ACK阶段。客户端收到以后,发送一个ACK表示收到并同意请求,接着由FIN-WAIT2进入TIME-WAIT阶段。服务器收到ACK,结束连接。此时(即客户端发送完ACK包之后),客户端还要等待2MSL(MSL=maxinum segment lifetime最长报文生存时间,2MSL就是两倍的MSL)才能真正的关闭连接。
Q. TCP重传机制(雷火)
Q. UDP、TCP(深信服)
tcp 传输控制协议
- 它是面向连接可靠的传输协议
- 通信流程是先建立好连接,然后才能进行数据的传输,通信完成以后关闭连接
udp 用户数据报协议
- 通信流程是创建好socket以后就直接可以发送数据了,不需要建立连接, 但是不能保证数据的准确性和有效性
tcp的特点
- 面向连接: 发送数据之前需要建立好连接, 间接验证ip地址的有效性
- 可靠的传输
- 应答机制:收到数据底层会回复
- 超时重传:如果数据包发送完成以后对方一直没有回复会隔一段时间再次发送,如果对方一直没有回复,表示掉 线了
- 错误校验:如果收到的数据包顺序和发送时候的顺序不一定会自动排序,这样数据不好发送错乱, 如果有重复的数据包会把重复的数据包删除
- 流量控制:如果发送数据的时候达到了网卡缓存区上限,会让其等待,等数据处理完成以后再发送数据,防止电脑卡死
tcp和udp的不同点
- tcp面向连接, udp不面向连接
- tcp能保证数据的可靠性,表示数据是有效无差错的,udp不能保证
- udp适合做广播,比如:飞秋上线操作, tcp不适合
- udp适合发送少量数据每个数据包最多是64kb, tcp适合发送大量数据
- udp的使用场景:音视频传输,发送广播消息, tcp的使用场景文件的上传和下载,绝大多数情况下都是tcp
Q. TCP传输大数据(鹅厂)
TCP 传输大块数据时,肯定需要进行数据分段,而每个分段所能携带的最大数据就是1个 MSS,假设大块数据为100个 MSS,那么发送方发送的方式大概有如下两种:
- 每次发送1个,收到接收方确认后,才发送下1个;
- 一口气发送100个,然后收到对方一起确认;
显然,方式1中,一个 RTT 只能处理一个包,这样的传输效率太低了。而方式2看似很美好,实际会存在两个问题,一个是接收方的接收窗口未必能一次性接收这么多数据,另外一个是网络的带宽也不一定足够大,容易出现丢包事故。所以引发了流量控制(Flow control)和拥塞控制(Congestion control)的问题
Q. TCP拥塞控制、流量控制(深信服、雷火)
TCP协议通过滑动窗口来进行流量控制,它是控制发送方的发送速度从而使接受者来得及接收并处理。而拥塞控制是作用于网络,它是防止过多的包被发送到网络中,避免出现网络负载过大,网络拥塞的情况。

拥塞控制主要是四个算法:1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复
Q. 如何把UDP变得可靠起来(鹅厂)
传输层无法保证数据的可靠传输,就只能通过应用层来实现了。实现的方式可以参照tcp可靠性传输的方式,只是实现不在传输层,实现转移到了应用层。
UDP要想可靠,就要接收方收到UDP之后回复个确认包,发送方有个机制,收不到确认包就要重新发送,每个包有递增的序号,接收方发现中间丢了包就要发重传请求,当网络太差时候频繁丢包,防止越丢包越重传的恶性循环,要有个发送窗口的限制,发送窗口的大小根据网络传输情况调整,调整算法要有一定自适应性。
恭喜你, 你在应用层重新实现了TCP!跟面试官可别这么说 (〃` 3′〃)
目前有如下开源程序利用UDP实现了可靠的数据传输,分别为RUDP、RTP、UDT
RUDP
RUDP 提供一组数据服务质量增强机制,如拥塞控制的改进、重发机制及淡化服务器算法等,从而在包丢失和网络拥塞的情况下, RTP 客户机(实时位置)面前呈现的就是一个高质量的 RTP 流。在不干扰协议的实时特性的同时,可靠 UDP 的拥塞控制机制允许 TCP 方式下的流控制行为。
RTP
实时传输协议(RTP)为数据提供了具有实时特征的端对端传送服务,如在组播或单播网络服务下的交互式视频音频或模拟数据。应用程序通常在 UDP 上运行 RTP 以便使用其多路结点和校验服务;这两种协议都提供了传输层协议的功能。但是 RTP 可以与其它适合的底层网络或传输协议一起使用。如果底层网络提供组播方式,那么 RTP 可以使用该组播表传输数据到多个目的地。
UDT
基于UDP的数据传输协议(UDP-basedData Transfer Protocol,简称UDT)是一种互联网数据传输协议。UDT的主要目的是支持高速广域网上的海量数据传输,而互联网上的标准数据传输协议TCP在高带宽长距离网络上性能很差。顾名思义,UDT建于UDP之上,并引入新的拥塞控制和数据可靠性控制机制。UDT是面向连接的双向的应用层协议。它同时支持可靠的数据流传输和部分可靠的数据报传输。由于UDT完全在UDP上实现,它也可以应用在除了高速数据传输之外的其它应用领域,例如点到点技术(P2P),防火墙穿透,多媒体数据传输等等。
介绍一下QUIC (鹅厂)
QUIC(Quick UDP Internet Connection)是谷歌提出的一种基于UDP的低时延的互联网传输层协议,QUIC的发音类似于Quick。实际上,QUIC确实很快。
QUIC 相比现在广泛应用的 HTTP+TCP+TLS 协议有如下优势:
- 减少了 TCP 三次握手及 TLS 握手时间
- 改进的拥塞控制
- 避免队头阻塞
QUIC 核心特性
0RTT建连
什么是 0RTT 建连呢?这里面有两层含义。
- 传输层 0RTT 就能建立连接。
- 加密层 0RTT 就能建立加密连接。
客户端之前没有连接个此服务器,那么他会发送一个Hello Packet。服务器接到之后,会回复一个数据包。里面包含了安全证书和对此客户端唯一的SYN cookie。客户端接到包之后,首先要做的就是解码,保存好SYN cookie。SYN cookie 类似于令牌,能够验证客户端身份。它的生存周期较短,防止被盗用。这样建立连接只需要1个RTT。
当客户端接到服务器发来的第一个数据包,没有正确解码,那么它会再次发送一个包要求服务器重新发送它的安全证书,并将SYN cookie附加到这个请求包中,以便让服务器验证请求的正确性和有效性。此时,建立连接需要2个RTT。

因为客户端之前已经成功和服务器通信。自然保留了一份服务器的安全证书。当再次想要连接服务器的时候,客户端假设这个安全证书没有过期,还是有效的。加密一个Hello Packet并发送之后。接着不用等回复就可以直接加密其他的数据包并发送。Hello Packet 里面包括一些协商信息和对自己掌握着Client IP的证明等。因为不用等待确认,为了预防丢包等问题,Hello Packet可能会隔一段时间被重传多次,保证减少丢包造成的延迟。比如,先发一个Hello包,之后发送数据包,再发送一个Hello包。
服务器接到Hello包之后,用自己现有的秘钥解码,如果解码不成功,将把客户端的连接当做第一次连接,重发安全证书等信息。同上介绍的一样。此时,通常会有2个RTT,极端情况下是3个RTT。
服务器成功解码之后,验证了客户端的安全性之后,就可以继续处理接下来收到的数据包。此时延时是0个RTT。

无歧义的重传
TCP 重传的 包的 sequence number 和原始的包的 sequence number 是保持不变的,也正是由于此,引发了 TCP 重传的歧义问题。

超时事件 RTO 发生后,客户端发起重传,然后服务端接收到了 ack 数据。由于 sequence number 一样,这个 ack 到底是原始请求的响应还是重传请求的响应呢?这就间接导致了RTT计算的歧义。
QUIC 使用 Packet Number 代替了 TCP 的 sequence number,并且每个 Packet Number 都严格递增,也就是说就算 Packet N 丢失了,重传的 Packet N 的 Packet Number 已经不是 N,而是一个比 N 大的值,这就解决了RTT计算的歧义问题。

保证包的顺序
QUIC 引入了一个叫 Stream Offset 的概念。
假设 Packet N 丢失了,发起重传,重传的 Packet Number 是 N+2,但是它的 Stream 的 Offset 依然是 x,这样就算 Packet N + 2 是后到的,依然可以将 Stream x 和 Stream x+y 按照顺序组织起来。

解决ack delay

TCP 的 RTT 计算:
R
T
T
=
t
i
m
e
s
t
a
m
p
2
−
t
i
m
e
s
t
a
m
p
1
RTT = timestamp2 - timestamp1
RTT=timestamp2−timestamp1
QUIC 的 RTT 计算: R T T = t i m e s t a m p 2 − t i m e s t a m p 1 − a c k d e l a y RTT = timestamp2 - timestamp1 - ack delay RTT=timestamp2−timestamp1−ackdelay
避免队头阻塞
我们以 HTTP2 举例,HTTP2 在一个 TCP 连接上同时发送 4 个 请求。其中 请求1 已经正确到达,并被应用层读取。但是 请求 2 的第三个 TCP 包丢失了,为了保证数据的顺序,需要发送端重传第 3 个包才能通知应用层读取接下去的数据,虽然这个时候 请求3 和 请求4 的全部数据已经到达了接收端,但都被阻塞住了。

QUIC 基于 UDP,各个请求之间相互独立,比如 请求2 丢了一个包,不会影响请求 3 和请求4,不存在 TCP 队头阻塞。
改进的拥塞控制
QUIC 协议当前默认使用了 TCP 协议的 Cubic 拥塞控制算法,同时也支持 CubicBytes, Reno, RenoBytes, BBR, PCC 等拥塞控制算法。
从拥塞算法本身来看,QUIC 只是按照 TCP 协议重新实现了一遍,那么 QUIC 协议到底改进在哪些方面呢?主要有如下两点:
(1)可插拔
什么叫可插拔呢?就是能够非常灵活地生效,变更和停止。体现在如下方面:
- 应用程序层面就能实现不同的拥塞控制算法,不需要操作系统,不需要内核支持。这是一个飞跃,因为传统的 TCP 拥塞控制,必须要端到端的网络协议栈支持,才能实现控制效果。而内核和操作系统的部署成本非常高,升级周期很长,这在产品快速迭代,网络爆炸式增长的今天,显然有点满足不了需求。
- 即使是单个应用程序的不同连接也能支持配置不同的拥塞控制。就算是一台服务器,接入的用户网络环境也千差万别,结合大数据及人工智能处理,我们能为各个用户提供不同的但又更加精准更加有效的拥塞控制。比如 BBR 适合,Cubic 适合。
- 应用程序不需要停机和升级就能实现拥塞控制的变更,我们在服务端只需要修改一下配置,reload 一下,完全不需要停止服务就能实现拥塞控制的切换。
(2)STGW 在配置层面进行了优化,我们可以针对不同业务,不同网络制式,甚至不同的 RTT,使用不同的拥塞控制算法。
Q. 快排优化、二路快排、三路快排
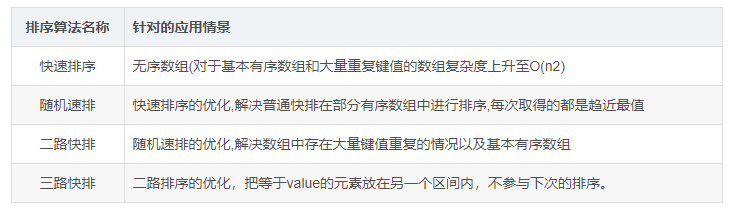
排序算法之——三路快排分析
快排优化:随机快排、双路快排、三路快排
Q. 头文件的作用,里面放什么?(深信服、雷火)
头文件的作用
- 通过头文件来调用库功能。提供保密和代码重用的手段。
- 减少代码的重复书写,提高编写和修改程序的效率。
里面放了什么
该文件包含了对程序中用到的所有函数的声明,即,只能在头文件中写形如:extern int a;和void f();的句子。但有三个规则是例外的:
- 头文件中可以写const对象的定义。因为全局的const对象默 认是没有extern的声明的,所以它只在当前文件中有效。把这样的对象写进头文件中,即使它被包含到其他多个.cpp文件中,这个对象也都只在包含它的 那个文件中有效,对其他文件来说是不可见的,所以便不会导致多重定义。同时,因为这些.cpp文件中的该对象都是从一个头文件中包含进去的,这样也就保证 了这些.cpp文件中的这个const对象的值是相同的,可谓一举两得。同理,static对象的定义也可以放进头文件。
- 头文件中可 以写内联函数(inline)的定义。因为inline函数是需要编译器在遇到它的地方根据它的定义把它内联展开的,而并非是普通函数那样可以先声明再链 接的(内联函数不会链接),所以编译器就需要在编译时看到内联函数的完整定义才行。如果内联函数像普通函数一样只能定义一次的话,这事儿就难办了。因为在 一个文件中还好,我可以把内联函数的定义写在最开始,这样可以保证后面使用的时候都可以见到定义;但是,如果我在其他的文件中还使用到了这个函数那怎么办 呢?这几乎没什么太好的解决办法,因此C++规定,内联函数可以在程序中定义多次,只要内联函数在一个.cpp文件中只出现一次,并且在所有的.cpp文 件中,这个内联函数的定义是一样的,就能通过编译。那么显然,把内联函数的定义放进一个头文件中是非常明智的做法。
- 头文件中可以写类 (class)的定义。因为在程序中创建一个类的对象时,编译器只有在这个类的定义完全可见的情况下,才能知道这个类的对象应该如何布局,所以,关于类的 定义的要求,跟内联函数是基本一样的。所以把类的定义放进头文件,在使用到这个类的.cpp文件中去包含这个头文件,是一个很好的做法。在这里,值得一提 的是,类的定义中包含着数据成员和函数成员。数据成员是要等到具体的对象被创建时才会被定义(分配空间),但函数成员却是需要在一开始就被定义的,这也就 是我们通常所说的类的实现。一般,我们的做法是,把类的定义放在头文件中,而把函数成员的实现代码放在一个.cpp文件中。这是可以的,也是很好的办法。 不过,还有另一种办法。那就是直接把函数成员的实现代码也写进类定义里面。在C++的类中,如果函数成员在类的定义体中被定义,那么编译器会视这个函数为 内联的。因此,把函数成员的定义写进类定义体,一起放进头文件中,是合法的。注意一下,如果把函数成员的定义写在类定义的头文件中,而没有写进类定义中, 这是不合法的,因为这个函数成员此时就不是内联的了。一旦头文件被两个或两个以上的.cpp文件包含,这个函数成员就被重定义了。
#include
#include 是一个来自C语言的宏命令,它在编译器进行编译之前,即在预编译的时候就会起作用。
#include的作用是把它后面所写的那个文件的内容,完完整整地、 一字不改地包含到当前的文件中来。简单的文本替换,别无其他。如,main.cpp文件中的第一句#include “math.h”,在编译之前就会被替换成math.h文件的内容。
Q:include< > 和“ ”区别
- 如果头文件名包含在<>中,那么认为该头文件是标准头文件。
编译器将会在预定义的位置集查找该头文件,这些预定义的位置可以通过设置查找路径环境变量或者通过命令行选项来修改。 - 如果头文件名包含在" "中,那么认为它是非系统文件,非系统文件的查找通常开始于源文件所在的路径。
Q17. 一个程序在执行main函数前干了啥
main函数执行之前,主要就是初始化系统相关资源:
1.设置栈指针
2.初始化static静态和global全局变量,即data段的内容
3.将未初始化部分的赋初值:数值型short,int,long等为0,bool为FALSE,指针为NULL,等等,即bss段的内容
4.运行全局构造器,即,全局对象的构造函数会在main 函数之前执行
5.将main函数的参数,argc,argv等传递给main函数,然后才真正运行main函数
Q18. new和malloc的区别
两者实现原理
new的实现原理:new的底层就是malloc,它会先调用malloc申请内存空间,然后再调用析构函数释放内存。
malloc的实现原理:malloc函数的实质体现在,它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表的功能。调用malloc函数时,它沿连接表寻找一个大到足以满足用户请求所需要的内存块。然后,将该内存块一分为二(一块的大小与用户请求的大小相等,另一块的大小就是剩下的字节)。接下来,将分配给用户的那块内存传给用户,并将剩下的那块(如果有的话)返回到连接表上。调用free函数时,它将用户释放的内存块连接到空闲链上。到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段,那么空闲链上可能没有可以满足用户要求的片段了。
为了减少内存碎片和系统调用的开销,malloc采用了内存池的方式,先申请大块内存作为堆区,然后将堆区分为多个内存块,以块作为内存管理的基本单位。同时malloc采用链表结构来管理所有空闲块,即使用一个双向链表将空闲快连接起来,每一个空闲块记录了一个连续、未分配的地址。
当内存进行分配时,malloc会通过链表遍历所有的空闲板块,选择满足要求的块进行分配。当进行内存合并时,malloc采用边界标记法,根据每个块前后块是否已经分配来决定是否进行块合并。
malloc在申请内存时,一般会通过brk或者mmap系统调用进行申请。其中当申请内存小于128K时,会使用系统函数brk在堆区中分配;而当申请内存大于128K时,会使用系统函数mmap在映射区分配。
二者区别
(1)new/delete是C++的操作符,需要编译器支持。 malloc/free是库函数,需要头文件的支持
(2)new可以调用对象的构造函数,对应的delete调用相应的析构函数,而malloc仅仅分配内存,free仅仅回收内存,并不执行构造和析构函数;
使用new操作符来分配对象内存时会经历三个步骤:
第一步:调用operator new 函数(对于数组是operator new[])分配一块足够大的,原始的,未命名的内存空间以便存储特定类型的对象。
第二步:编译器运行相应的构造函数以构造对象,并为其传入初值。
第三步:对象构造完成后,返回一个指向该对象的指针。
使用delete操作符来释放对象内存时会经历两个步骤:
第一步:调用对象的析构函数。
第二步:编译器调用operator delete(或operator delete[])函数释放内存空间。
(3)使用new操作符申请内存分配时无需指定内存块的大小,编译器会根据其信息自行计算,且需要用户自己初始化。而malloc则需要显示地指出所需内存的大小,会自行初始化
(4)new操作符内存分配成功时,返回的类型是指针,类型严格与对象匹配,无需转换,所以new是符合类型的安全操作符。而malloc返回的是void*,需要通过强制类型转换,强制void*转换成我们需要的类型。
(5)opeartor new /operator delete可以被重载。标准库是定义了operator new函数和operator delete函数的8个重载版本。而malloc/free并不允许重载。
(6)C++提供了new[]与delete[]来专门处理数组类型。new对数组的支持体现在它会分别调用构造函数初始化每一个数组元素,释放对象时为每个对象调用析构函数。注意delete[]要与new[]配套使用,不然会导致数组对象部分释放的现象,造成内存泄漏。至于malloc,它并不知道你在这块内存上要放的数组还是啥别的东西,反正它就给你一块原始的内存,再给你个内存的地址就完事。所以如果要动态分配一个数组的内存,还需要我们手动自定数组的大小
这里有一个知识点,就是调用delete[]时并未指定要删除的大小,那么delete是怎么知道要释放多少呢?
这是因为,在new[]一个数组对象时,C++在分配数组空间时多分配了4个字节的大小,专门用来保存数组的大小,这4个字节的空间在数组的前面,而new[]返回的指针则指向第一个元素。在delete[]时就可以从数组之前取出这个保存的数,就知道需要调用析构函数的次数了。
(7)new内存分配失败时,会抛异常,即出现bac_alloc现象异常。 malloc分配内存失败时返回NULL
(8)new操作符从自由存储区上为对象动态分配内存空间,而malloc函数从堆上动态分配内存。自由存储区是C++基于new操作符的一个抽象概念,凡是通过new操作符进行内存申请,该内存即为自由存储区,而堆是操作系统中的术语,是操作系统所维护的一块特殊区域内存,用于程序的内存动态分配,C语言使用的malloc从堆上分配内存,使用free释放已经分配的内存。
delete和free被调用后,内存不会立即回收,指针也不会指向空,delete或free仅仅是告诉操作系统,这一块内存被释放了,可以用作其他用途。但是由于没有重新对这块内存进行写操作,所以内存中的变量数值并没有发生变化,这时候就会出现野指针的情况。因此,释放完内存后,应该把指针指向NULL。
Q19. 如果new之后用free会怎样
new()函数实际过程中做了两步操作,第一步是分配内存空间,第二步是调用类的构造函数;delete()也同样是两步,第一步是调用类的析构函数,第二步才是释放内存;而malloc()和free()仅仅是分配内存与释放内存操作
那么如果通过new分配的内存,再用free去释放,就会少一步调用析构函数的过程。同时,在构造函数里面申请的内存因为没有调用析构函数,所以该内存并没有释放
Q. delete该用方括号的时候不用怎么样
分两种情况:基本数据类型的分配和自定义数据类型的分配
基本数据类型
对于基本数据类型,假如有如下代码
int *a = new int[10];
...
delete a; // 方式1
delete [ ] a; //方式2
肯定会不少人认为方式1存在内存泄露,然而事实上是不会!针对简单的基本数据类型,方式1和方式2均可正常工作,因为:基本的数据类型对象没有析构函数,并且new 在分配内存时会记录分配的空间大小,则delete时能正确释放内存,无需调用析构函数释放其余指针。因此两种方式均可。
自定义数据类型
这里一般指类,假设通过new申请了一个对象数组,注意是对象数组,返回一个指针,对于此对象数组的内存释放,需要做两件事情:一是释放最初申请的那部分空间,二是调用析构函数完成清理工作。对于内存空间的清理,由于申请时记录了其大小,因此无论使用delete还是delete[ ]都能将这片空间完整释放,而问题就出在析构函数的调用上,当使用delete时,仅仅调用了对象数组中第一个对象的析构函数,而使用delete [ ]的话,将会逐个调用析构函数。

Q. 在类的成员函数中能不能调用delete this?(雷火)
能,成员函数调用delete this之后还能进行其他操作吗?能,但是有个前提:被调用的方法不涉及这个对象的数据成员和虚函数。
为什么?当调用delete this时,类对象的内存空间被释放。在delete this之后进行的其他任何函数调用,只要不涉及到this指针的内容,都能够正常运行。
如果在类的析构函数中调用delete this,会发生什么?
delete的本质是“为将被释放的内存调用一个或多个析构函数,然后,释放内存” (来自effective c++)。显然,delete this会去调用本对象的析构函数,而析构函数中又调用delete this,形成无限递归,造成堆栈溢出,系统崩溃。
实际操作中使用delele this确实会直接出现错误。这是因为:在成员函数中调用delete this,首先会调用类的析构函数,this指针已删除,会出现指针错误。
Q21. 访问数组下标为-1的位置会怎么样?(深信服)
数组下标为-1的地址对于数组来说是越界访问了,但是这个地址是有意义的
这个地址就是所申请的数组存储空间的首地址的向前偏移一个单位(也就是偏移一个当前数组类型所对应的字节数)所对应的地址。
这个地址由于没有跟着数组空间一起初始化,所以其中的数据是不一定的,
如果是正在被系统使用中的地址空间,那么可以被访问,其中的数据的意义取决于被系统所写入的数据,但是访问后,有可能会引起系统异常。
如果是没有被使用的地址,那么就是一个野地址,那么其中的数据是随机的,无意义的。
for example
判断数组尾部是否存在换行符,如存在则用结束符代替:
char resp[256];
char *e = resp + strlen(resp);
if (e > resp && e[-1] == '\n')
e[-1] = '\0';
检测数组越界
if (size > 0) {
if (str < end) *str = '\0';
else end[-1] = '\0';
其中end是定义的内存空间的结束位置,如果访问越界了,就在结束前一个位置添加一个字符串结束符。
Q28. C++内联函数(深信服)
内联函数是什么
内联函数,它是一种编程语言结构,但与我们的普通函数不同,这种结构是给编译器用的,在编译过程发挥作用。
那怎么发挥作用呢?也就是编译器会如何使用内联函数呢?总体上讲有把它展开(类似带参宏展开)和把它当做普通函数看待(此时失去内联作用)两种。它类似带参宏定义展开,也就是在编译过程中他会以一种复制黏贴内联函数体内部代码的方式到调用处展开,所以会使得代码总量有些增加。然后,在调用处展开了之后,它就会像其他非函数调用的代码那样被执行,但此时由于不是函数调用,所以就没有了函数调用固有开销(如参数传递、保存上下文)。而后者应该是编译器的一些优化设计。
为什么需要内联函数
当函数体十分简短,我们调用它时函数调用的固有开销(参数传递、保存上下文)会大于函数体内部代码执行所占的开销。也就是说我们要调用一个函数,在真正执行函数体内部代码之前所做的准备工作所占时长都比我们真正执行函数体内部代码所占的时长还多了。那样的话调用这个函数就有些不值得啦,一次两次看不出,但频繁调用的话就会很浪费资源了。
那怎么办?直接用一句两句代码(非函数调用)实现就可以了。但我们又想要层次结构分明之类的,又或者这些与参数有关之类的,直接代码写死不好,那怎么办?那就我们主角——内联函数出场了。
内联函数怎么用
以下情况适合使用内联函数
(1)函数体很简短,里面没有循环、switch等复杂的结构控制语句。
(2)函数没有直接递归调用自身。
内联函数与(带参宏)宏定义的区别
(1)内联函数在编译过程展开,而宏定义在预编译过程展开。
(2)宏定义是简单的文本替换,而内联函数是直接被嵌入到目标代码中去的。
(3)使用宏定义时要小心处理宏参数,一般要用括号括起来,否则容易出现二义性。而内联函数没有这种二义性。
(4)宏展开是不作参数类型检查的,而内联函数是会作参数类型检查且还有返回值的类型检查。
内联函数与普通函数的区别
(1)普通函数调用需要到函数入口地址去执行,而内联函数不用寻址直接在那儿执行就可以了。
(2)内联函数有一定的限制,参考上面的“怎么使用内联函数”。
Q29. 父类指针或引用指向子类对象,可以访问子类成员吗(深信服)
父类指针既可以指向父类对象,也可以指向子类对象
当父类指针指向父类对象时,访问父类的成员
当父类指针指向子类对象时,那么只能访问子类中从父类继承下来的那部分成员,不能访问子类独有的成员,如果访问,编译阶段会报错
Q30. 如何判断一段程序是由C编译程序还是C++编译程序编译的?(深信服)
#ifdef __cplusplus
cout << "C++" << endl;
#else
cout << "C" << endl;
#endif
Q31. 两个栈实现队列(深信服)
Q32. 最小时间复杂度匹配子串(深信服)
单独只说一点: n e x t [ j ] next[j] next[j] 表示档模式中第 j 个字符与主串中相应字符“失配”时, 在模式中需要重新和主串中该字符进行比较的字符的位置
Q33. 操作系统中的消费者/生产者模型(深信服)
Q34. 互斥锁(深信服)
互斥锁是一个二元变量,其状态为开锁(允许0)和上锁(禁止1),将某个共享资源与某个特定互斥锁在逻辑上绑定(要申请该资源必须先获取锁)。
(1)访问公共资源前,必须申请该互斥锁,若处于开锁状态,则申请到锁对象,并立即占有该锁,以防止其他线程访问该资源;如果该互斥锁处于锁定状态,则阻塞当前线程。
(2)只有锁定该互斥锁的进程才能释放该互斥锁,其他线程试图释放无效。
Q35. 哈希表原理及冲突解决(深信服)
- 外部拉链

- 开放定址法
主要思想是发生冲突时,直接去寻找下一个空的地址,只要底层的表足够大,就总能找到空的地址。这个寻找下一个地址的行为,叫做探测
Q. 哈希的时间复杂度(鹅厂)
时间复杂度在平均情况下,搜索、插入、删除都是 O ( 1 ) O(1) O(1);但在最差情况下,会退化成 O ( n ) O(n) O(n)
Q. 虚拟地址空间由哪些组成(深信服)
虚拟地址空间由内核空间(kernel space)和用户模式空间(user mode space)两部分组成。其中内核空间是持续存在的,并且在所有进程中都映射到同样的物理内存。与此相反,用户模式空间的映射随进程切换的发生而不断变化。
Q. 一个指针为什么是四字节(深信服)
首先,指针就是地址,地址就是指针。而地址是内存单元的编号。所以,一个指针占几字节,等于是一个地址内存单元编号有多长。
地址总线的宽度决定了CPU的寻址能力。对32位计算机,我们一般需要32个0或1的组合就可以找到内存中所有的地址,而32个0或1的组合,就是32个位,也就是4个字节的大小,因此,我们只需要4个字节就可以找到所有的数据。所以,指针变量在编译期转换为一个32位4字节的地址串(即存储单元编号), 存放在寄存器中。同理,在64位的计算机中,指针占8个字节。
Q. Int型指针指向char数组"abcd" 取int*的值是多少(深信服)
先说大小端的问题:高位字节放低地址,低位字节放高地址,是大端字节序
记句顺口溜:自大的人眼高手低–其中,自大代表大端序,眼高代表高地址,手低代表低字节
char占一字节,int占四字节,“abcd”的char数组刚好是四字节,将char数组转换成32位二进制再对应转换成int就行
Q. 大端小端?操作系统一般是大端还是小端?int i = 1 在内存中怎么存的?(雷火)
x86下windows和fedora都是小端。int类型在内存中以补码的形式存储,剩下的就是大端小端的问题了,要么是0001 0000 0000 0000,要么是0000 0000 0000 0001
Q. 带参宏定义(深信服)
Q. C++ explicit关键字(深信服)
Q. 对一个数组,频繁查找子区间的和(深信服)
我们用 O ( n ) O(n) O(n)的空间记录数组 A A A中每个元素到 A [ 0 ] A[0] A[0]的和,如果计算 A [ 3 , 5 ] A[3,5] A[3,5],即 A [ 3 , 5 ] = s u m ( 5 ) − s u m ( 3 ) + A [ 3 ] A[3,5] = sum(5) - sum(3) + A[3] A[3,5]=sum(5)−sum(3)+A[3]
深入一点可以答树状数组
Q. 对一个矩阵,频繁查找子区域的元素和(深信服)
有了Q47.的基础,这个问就很好处理了,如下图

深入一点可以答二维树状数组
Q. 互斥对象(深信服)
线程同步(windows平台):互斥对象
互斥对象与事件对象实现线程同步
Q. 关键字const(深信服)
Q. 套接字编程(深信服)


Q. 排序(雷火)
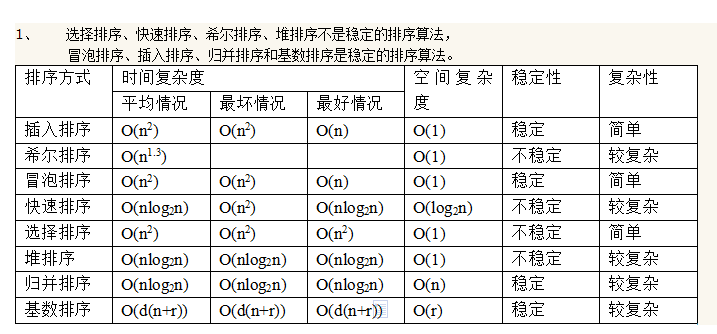
不稳定的:情绪不稳定,快些选一堆好友来聊天
复杂度(O(nlogn)): 快些 以nlogn 归队
复杂度分析:
选排 正序时候比较次数是 n − 1 n-1 n−1,逆序时候比较次数是 ∑ i = 2 n i \sum_{i=2}^{n}i ∑i=2ni
快排
假设
T
(
n
)
T(n)
T(n)是对
n
n
n个记录进行快速排序所需时间,则
T ( n ) = f ( n ) + T ( k − 1 ) + T ( n − k ) T(n)=f(n)+T(k-1)+T(n-k) T(n)=f(n)+T(k−1)+T(n−k),其中 f ( n ) f(n) f(n)是一趟快排所需时间,且 f ( n ) ∝ n f(n)\propto n f(n)∝n, c c c某常数,于是有 f ( n ) = c n f(n) = cn f(n)=cn
假设待排序列中的记录是随机排列的, k k k取 1... n 1...n 1...n之间任何一值的概率相同,则快排所需时间的平均值为
T a v g ( n ) = c n + 1 n ∑ k = 1 n [ T a v g ( k − 1 ) + T a v g ( n − k ) ] = c n + 2 n ∑ i = 0 n T a v g ( i ) \begin{aligned}T_{avg}(n) &= cn + \frac{1}{n}\sum_{k=1}^n[T_{avg}(k-1)+T_{avg}(n-k)] \\ & =cn+\frac{2}{n}\sum_{i=0}^nT_{avg}(i)\end{aligned} Tavg(n)=cn+n1k=1∑n[Tavg(k−1)+Tavg(n−k)]=cn+n2i=0∑nTavg(i)
由数学归纳法可证其数量级为 O ( n l o g n ) O(nlogn) O(nlogn)
换种解释方法也就是在最优的情况下递归树的深度为 ⌊ l o g 2 n ⌋ + 1 \left \lfloor log_2n \right \rfloor+1 ⌊log2n⌋+1,需要 l o g 2 n log_2n log2n次的递归,每次时间为 O ( n ) O(n) O(n)
数组有序时,快排退化为冒泡排序,比较次数为 n ( n − 1 ) 2 \frac{n(n-1)}{2} 2n(n−1)
选排 无论记录的初始排列如何,所需进行的关键字间的比较次数相同,均为 n ( n − 1 ) 2 \frac{n(n-1)}{2} 2n(n−1)
堆排
初始化堆
O
(
n
)
O(n)
O(n)
假设堆的深度为 k k k,建堆的时间为 T = ∑ i = 1 k − 1 2 i − 1 ⋅ ( k − i ) T = \sum_{i=1}^{k-1}2^{i-1}\cdot(k-i) T=∑i=1k−12i−1⋅(k−i),其中 i i i表示第几层, 2 i − 1 2^{i-1} 2i−1表示该层上有多少元素, k − i k-i k−i表示子树上要下调比较的次数
于是, T = 2 k − k + 1 T=2^k-k+1 T=2k−k+1,其中 k = l o g n k=logn k=logn
重建
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)
调整建新堆时调用adjustheap()过程
n
−
1
n-1
n−1次,每次的比较次数为
l
o
g
i
logi
logi,则
l
o
g
2
+
l
o
g
3
+
⋯
+
l
o
g
n
≈
l
o
g
(
n
!
)
log2+log3+\cdots+logn\approx log(n!)
log2+log3+⋯+logn≈log(n!),可以证明
l
o
g
(
n
!
)
log(n!)
log(n!)与
n
l
o
g
n
nlogn
nlogn同阶
总的时间复杂度为 O ( n + n l o g n ) = O ( n l o g n ) O(n+nlogn)=O(nlogn) O(n+nlogn)=O(nlogn)
归并
f
(
n
)
=
2
f
(
n
2
)
+
n
f(n)=2f(\frac{n}{2})+n
f(n)=2f(2n)+n,其中
f
(
n
)
f(n)
f(n)是对
n
n
n个数进行归并排序所需的时间,
n
n
n是merge操作所需的时间
由数学归纳法得
f ( n ) = 2 m f ( n 2 m ) + m n f(n)=2^mf(\frac{n}{2^m})+mn f(n)=2mf(2mn)+mn
当 m m m足够大,仅剩一个数字时, n 2 m = 1 , m = l o g n \frac{n}{2^m}=1,m=logn 2mn=1,m=logn,则
f ( n ) = 2 l o g n f ( 1 ) + n l o g n f(n)=2^{logn}f(1)+nlogn f(n)=2lognf(1)+nlogn,其中 f ( 1 ) = 0 f(1)=0 f(1)=0
Q. C++内存分布(雷火)
在C++中,内存分成5个区,他们分别是堆、栈、自由存储区、全局/静态存储区和常量存储区
1.栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清楚的变量的存储区。里面的变量通常是局部变量、函数参数等。
2.堆,就是那些由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new就要对应一个delete.如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
3.自由存储区,就是那些由malloc等分配的内存块,他和堆是十分相似的,不过它是用free来结束自己的生命的。
4.全局/静态存储区,全局变量和静态变量被分配到同一块内存中,在以前的C语言中,全局变量又分为初始化的和未初始化的,在C++里面没有这个区分了,他们共同占用同一块内存区。
5.常量存储区,这是一块比较特殊的存储区,他们里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改)
Q. 进程地址空间是怎么样的?(雷火)
Q. 说一说c++中四种cast转换(雷火)
C++中四种类型转换是:static_cast,dynamic_cast,const_cast,reinterpret_cast
const_cast
const_cast这个操作符可以去掉变量const属性或者volatile属性的转换符,这样就可以更改const变量了
static_cast
用法:static_cast < type-id > ( expression )
该运算符把expression转换为type-id类型,但没有运行时类型检查来保证转换的安全性。其相当于C语言中的强制类型转换的替代品,主要有如下几种用法:
- 用于类层次结构中基类和子类之间指针或引用的转换。进行上行转换(把子类的指针或引用转换成基类表示)是安全的;进行下行转换(把基类指针或引用转换成子类表示)时,由于没有动态类型检查,所以是不安全的。
- 用于基本数据类型之间的转换,如把int转换成char,把int转换成enum。这种转换的安全性也要开发人员来保证。
- 把空指针转换成目标类型的空指针。
- 把任何类型的表达式转换成void类型。
注意:static_cast不能转换掉expression的const、volitale、或者__unaligned属性。
dynamic_cast
用法:dynamic_cast < type-id > ( expression )
该运算符把expression转换成type-id类型的对象。Type-id必须是类的指针、类的引用或者void *;如果type-id是类指针类型,那么expression也必须是一个指针,如果type-id是一个引用,那么expression也必须是一个引用。
dynamic_cast 操作符可以安全的将父类转化为子类,子类转化为父类都是安全的。所以你可以用于安全的将基类转化为继承类,而且可以知道是否成功,如果强制转换的是指针类型,失败会返回NULL指针,如果强制转化的是引用类型,失败会抛出异常。dynamic_cast 转换符只能用于含有虚函数的类。
reinterpret_cast
重新解释(无理)转换。即要求编译器将两种无关联的类型作转换。
QQ. dynamic_cast怎么进行执行期检查的?
首先,dynamic_cast依赖于RTTI(运行时类型识别)信息。在转换时,dynamic_cast会检查转换的source对象是否真的可以转换成target类型,这种检查不是语法上的,而是真实情况的检查。
先看RTTI相关部分,通常,许多编译器都是通过vtable找到对象的RTTI信息的,这也就意味着,如果基类没有虚方法,也就无法判断一个基类指针变量所指对象的真实类型,这时候,dynamic_cast只能用来做安全的转换,例如从派生类指针转换成基类指针。而这种转换其实并不需要dynamic_cast参与。也就是说,dynamic_cast是根据RTTI记载的信息来判断类型转换是否合法的.
Q. 虚继承(雷火)
虚继承是解决C++多重继承问题的一种手段,从不同途径继承来的同一基类,会在子类中存在多份拷贝。这将存在两个问题:其一,浪费存储空间;第二,存在二义性问题。虚继承可以解决多种继承的这两个问题。
Q. 请说一下C/C++ 中指针和引用的区别?(雷火)
- 指针有自己的一块空间,而引用只是一个别名;
- 使用sizeof看一个指针的大小是4,而引用则是被引用对象的大小;
- 指针可以被初始化为NULL,而引用必须被初始化且必须是一个已有对象的引用;
- 作为参数传递时,指针需要被解引用才可以对对象进行操作,而直接对引用的修改都会改变引用所指向的对象;
- 可以有const指针,引用常量不存在,没有int& const p,常量引用是存在的cosnt int &p;
- 指针在使用中可以指向其它对象,但是引用只能是一个对象的引用,不能被改变;
- 指针可以有多级指针(**p),而引用至多一级;
- 指针和引用使用++运算符的意义不一样;指针和引用的自增(++)运算意义不一样?怎么个不同法?请举例说明
- 如果返回动态内存分配的对象或者内存,必须使用指针,引用可能引起内存泄露。
Q. 拷贝构造函数(雷火)
拷贝构造函数的作用就是用来复制对象的,在使用这个对象的实例来初始化这个对象的一个新的实例。
拷贝构造函数的调用时机
- 当函数的参数为类的对象时
- 函数的返回值是类的对象
- 对象需要通过另外一个对象进行初始化
Q. 拷贝构造函数参数是什么样的 (雷火)
拷贝构造函数的参数类型必须是引用,如果拷贝构造函数中的参数不是一个引用,即形如CClass(const CClass c_class),那么就相当于采用了传值的方式(pass-by-value),而传值的方式会调用该类的拷贝构造函数,从而造成无穷递归地调用拷贝构造函数。
当一个对象需要以值方式传递时,编译器会生成代码调用它的拷贝构造函数以生成一个复本。如果类A的拷贝构造函数是以值方式传递一个类A对象作为参数的话,当需要调用类A的拷贝构造函数时,需要以值方式传进一个A的对象作为实参;而以值方式传递需要调用类A的拷贝构造函数;结果就是调用类A的拷贝构造函数导致又一次调用类A的拷贝构造函数,这就是一个无限递归。
因此拷贝构造函数的参数必须是一个引用。需要澄清的是,传指针其实也是传值,如果拷贝构造函数写成CClass(const CClass* c_class),也是不行的。事实上,只有传引用不是传值外,其他所有的传递方式都是传值。
Q. 类没声明拷贝构造函数时有没有拷贝构造函数,深拷贝浅拷贝?简单分析一下深拷贝和浅拷贝区别(雷火)
很多时候在我们都不知道拷贝构造函数的情况下,传递对象给函数参数或者函数返回对象都能很好的进行,这是因为编译器会给我们自动产生一个拷贝构造函数,这就是“默认拷贝构造函数”,这个构造函数很简单,仅仅使用“老对象”的数据成员的值对“新对象”的数据成员一一进行赋值,也就说默认拷贝构造函数执行的是浅拷贝
所谓浅拷贝,指的是在对象复制时,只对对象中的数据成员进行简单的赋值,多情况下“浅拷贝”已经能很好地工作了,但是一旦对象存在了动态成员,那么浅拷贝就会出问题了。
在“深拷贝”的情况下,对于对象中动态成员,就不能仅仅简单地赋值了,而应该重新动态分配空间。
Q. 模板类是编译时确定还是运行时确定?(雷火)
模板类是编译时多态。所有的模板都是在编译时产生对应的代码,它没有面向对象中的虚表,无法实现动态多态。
Q. 为什么C++调用C函数要用extern “C”?(雷火)
主要的原因就是C++编译的函数和C编译的函数在库中的名字不一样
Q. linux下可执行文件是什么格式?介绍一下这个文件格式(雷火)
Linux下面,目标文件、共享对象文件、可执行文件都是使用ELF文件格式来存储的。
ELF文件的最开始是ELF文件头信息,32位有52个字节组成。ELF文件头包括:
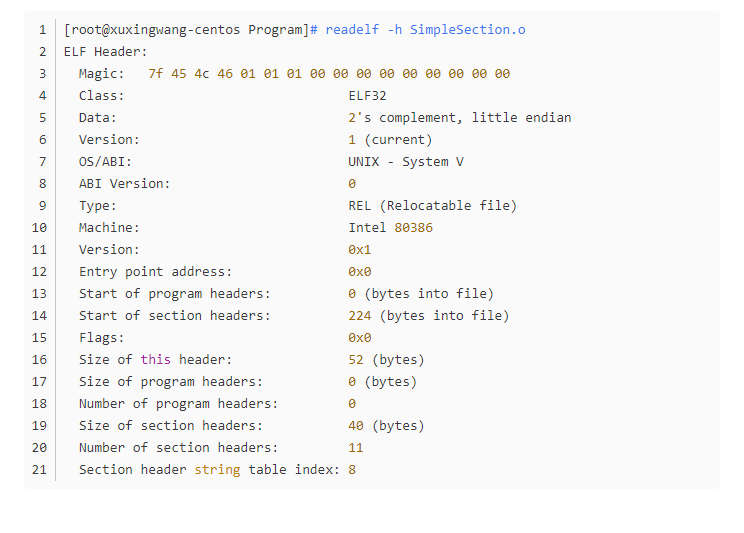
- Entry point address 指的是程序入口地址,如果是可执行文件,这个字段会有值;它之前的字段是一些说明字段;
- Start of program headers 指的是程序头表的起始位置。程序头表是从装载视图的角度对ELF的各个段进行的分类信息;结构和段表相似;
- Start of section headers 指出了ELF除文件头以外的最重要的信息:段表的起始位置。段表包含了各个段的名称、属性、大小、位置等重要信息。操作系统首先找到段表,然后根据段表的信息去找到各个段。段表是一个类似数组的结构,一个段的信息是这个数组的一个元素。
- Size of this header 指的是头文件大小,32位都是52 个字节,0x34个字节。
- Size of program headers 指的是每个程序头表的大小。
- Number of program headers 指的是 程序头表 的数目。
- Size of sections headers 指的是每个段表的大小;
- Number of section headers 指的是段表的数量;
- Section header string table index 指出了段表当中用到的字符串表在段表中的下标。
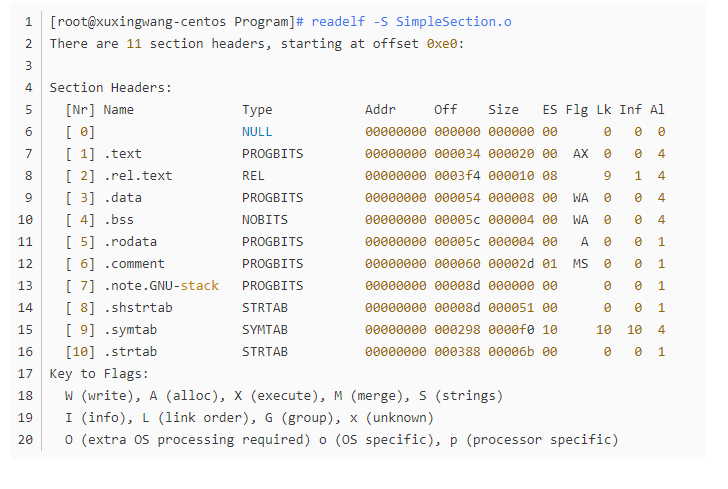
文件头之后,紧跟着的是程序头,程序头转载了目标文件链接的信息,程序头之后就是各个段的数据,我们可以用工具查看一下:
Q. 操作系统有哪些锁?(雷火、鹅厂)
信号量、互斥量、临界区、读写锁、条件变量
Q. 介绍一下C++的智能指针(雷火)
C++里面的四个智能指针: auto_ptr,shared_ptr,weak_ptr,unique_ptr 其中后三个是c++11支持,并且第一个已经被11弃用。
为什么要使用智能指针:
智能指针的作用是管理一个指针,因为存在以下这种情况:申请的空间在函数结束时忘记释放,造成内存泄漏。使用智能指针可以很大程度上的避免这个问题,因为智能指针就是一个类,当超出了类的作用域是,类会自动调用析构函数,析构函数会自动释放资源。 所以智能指针的作用原理就是在函数结束时自动释放内存空间,不需要手动释放内存空间。
(1) auto_ptr
auto_ptr< string> p1 (new string ("I reigned lonely as a cloud.”));
auto_ptr<string> p2;
p2 = p1; //auto_ptr不会报错.
此时不会报错,p2剥夺了p1的所有权,但是当程序运行时访问p1将会报错。所以,auto_ptr的缺点是:存在潜在的内存崩溃问题
(2)unique_ptr(替换auto_ptr)
unique_ptr实现独占式拥有或严格拥有概念,保证同一时间内只有一个智能指针可以指向该对象。 它对于避免资源泄露(例如“以new创建对象后因为发生异常而忘记调用delete”)特别有用。
unique_ptr<string> p3 (new string ("auto")); //#4
unique_ptr<string> p4; //#5
p4 = p3;//此时会报错!!
编译器认为p4=p3非法,避免了p3不再指向有效数据的问题。因此,unique_ptr比auto_ptr更安全。
另外unique_ptr还有更聪明的地方:当程序试图将一个 unique_ptr 赋值给另一个时,如果源 unique_ptr 是个临时右值,编译器允许这么做;如果原 unique_ptr 将存在一段时间,编译器将禁止这么做,比如:
unique_ptr<string> pu1(new string ("hello world"));
unique_ptr<string> pu2;
pu2 = pu1; // #1 not allowed
unique_ptr<string> pu3;
pu3 = unique_ptr<string>(new string ("You")); // #2 allowed
其中#1留下悬挂的unique_ptr(pu1),这可能导致危害。而#2不会留下悬挂的unique_ptr,因为它调用 unique_ptr 的构造函数,该构造函数创建的临时对象在其所有权让给 pu3 后就会被销毁。这种随情况而已的行为表明,unique_ptr 优于允许两种赋值的auto_ptr 。
注:如果确实想执行类似与#1的操作,要安全的重用这种指针,可给它赋新值。C++有一个标准库函数std::move(),让你能够将一个unique_ptr赋给另一个。例如:
unique_ptr<string> ps1,ps2;
ps1 = demo("hello");
ps2 = move(ps1);
ps1 = demo("alexia");
cout << *ps2 << *ps1 << endl;
(3)shared_ptr
几乎每一个有分量的程序都需要“在相同时间的多处地点处理或使用对象”的能力。为此,我们必须在程序的多个地点指向(refer to)同一对象。虽然C++语言提供引用(reference)和指针(pointer),还是不够,因为我们往往必须确保当“指向对象”的最末一个引用被删除时该对象本身也被删除,毕竟对象被删除时析构函数可以要求某些操作,例如释放内存或归还资源等等。
shared_ptr实现共享式拥有概念。多个智能指针可以指向相同对象,该对象和其相关资源会在“最后一个引用被销毁”时候释放。 从名字share就可以看出了资源可以被多个指针共享,它使用计数机制来表明资源被几个指针共享。可以通过成员函数use_count()来返回引用计数的个数。除了可以通过new来构造,还可以通过传入auto_ptr,unique_ptr,weak_ptr来构造。当我们调用release()时,当前指针会释放资源所有权,计数减一。当计数等于0时,资源会被释放。
shared_ptr 是为了解决 auto_ptr 在对象所有权上的局限性(auto_ptr 是独占的),在使用引用计数的机制上提供了可以共享所有权的智能指针。
(4)weak_ptr
weak_ptr 是一种不控制对象生命周期的智能指针,它指向一个 shared_ptr 管理的对象。 进行该对象的内存管理的是那个强引用的 shared_ptr. weak_ptr只是提供了对管理对象的一个访问手段。weak_ptr 设计的目的是为配合 shared_ptr 而引入的一种智能指针来协助 shared_ptr 工作,它只可以从一个 shared_ptr 或另一个 weak_ptr 对象构造,它的构造和析构不会引起引用记数的增加或减少。weak_ptr是用来解决shared_ptr相互引用时的死锁问题, 如果说两个shared_ptr相互引用,那么这两个指针的引用计数永远不可能下降为0,资源永远不会释放。它是对对象的一种弱引用,不会增加对象的引用计数,和shared_ptr之间可以相互转化,shared_ptr可以直接赋值给它,它可以通过调用lock函数来获得shared_ptr。
class B;
class A
{
public:
shared_ptr<B> pb_;
~A()
{
cout<<"A delete\n";
}
};
class B
{
public:
shared_ptr<A> pa_;
~B()
{
cout<<"B delete\n";
}
};
void fun()
{
shared_ptr<B> pb(new B());
shared_ptr<A> pa(new A());
pb->pa_ = pa;
pa->pb_ = pb;
cout<<pb.use_count()<<endl;
cout<<pa.use_count()<<endl;
}
int main()
{
fun();
return 0;
}
可以看到fun函数中pa ,pb之间互相引用,两个资源的引用计数为2,当要跳出函数时,智能指针pa,pb析构时两个资源引用计数会减一,但是两者引用计数还是为1,导致跳出函数时资源没有被释放(A、B的析构函数没有被调用),如果把其中一个改为weak_ptr就可以了,我们把类A里面的shared_ptr pb_;改为weak_ptr pb_; 运行结果如下,这样的话,资源B的引用开始就只有1,当pb析构时,B的计数变为0,B得到释放,B释放的同时也会使A的计数减一,同时pa析构时使A的计数减一,那么A的计数为0,A得到释放
注意的是我们不能通过weak_ptr直接访问对象的方法,比如B对象中有一个方法print(),我们不能这样访问,pa->pb_->print(),因为pb_是一个weak_ptr,应该先把它转化为shared_ptr,如:shared_ptr p = pa->pb_.lock(); p->print();
Q. 请你回答一下智能指针有没有内存泄露的情况
当两个对象相互使用一个shared_ptr成员变量指向对方,会造成循环引用,使引用计数失效,从而导致内存泄漏
Q. 请你来说一下智能指针的内存泄漏如何解决
为了解决循环引用导致的内存泄漏,引入了weak_ptr弱指针,weak_ptr的构造函数不会修改引用计数的值,从而不会对对象的内存进行管理,其类似一个普通指针,但不指向引用计数的共享内存,但是其可以检测到所管理的对象是否已经被释放,从而避免非法访问。
Q. 智能指针怎样线程安全?(雷火、鹅厂)
对于unique_ptr,由于只是在当前代码块范围内生效,因此不涉及线程安全问题。而shared_ptr的引用计数在手段上使用了atomic原子操作,因此shared_ptr本身是线程安全的。但智能指针所指对象的线程安全问题没有任何保障,换句话说,也就是对象的读写不一定是线程安全的。主要的考虑是多线程编程中的三个核心概念:原子性、可见性和顺序性。为了解决智能指针所指对象的线程安全问题可以加入互斥锁(mutex),也可以使用lock_guard
Q. web server里长链接怎么做的?(雷火)
web 通信 之 长连接、长轮询(long polling)
基于HTTP的长连接是一种通过长轮询方式实现"服务器推"的技术,它弥补了HTTP简单的请求应答模式的不足,极大地增强了程序的实时性和交互性。
通常的做法是,在服务器的程序中加入一个死循环,在循环中监测数据的变动。当发现新数据时,立即将其输出给浏览器并断开连接,浏览器在收到数据后,再次发起请求以进入下一个周期,这就是长轮询方式。
轮询可能在以下3种情况时终止:
- 有新数据推送
当循环过程中服务器向浏览器推送信息后,应该主动结束程序运行从而让连接断开,这样浏览器才能及时收到数据。 - 没有新数据推送
循环不能一直持续下去,应该设定一个最长时限,避免WEB服务器超时(Timeout),若一直没有新信息,服务器应主动向浏览器发送本次轮询无新信息的正常响应,并断开连接,这也被称为“心跳”信息。 - 网络故障或异常
由于网络故障等因素造成的请求超时或出错也可能导致轮询的意外中断,此时浏览器将收到错误信息。
Q. MYSQL中怎么查看查询性能?
explain + sql语句

重点关注
type:显示查询使用了何种类型。从最好到最差依次是:system>const>eq_ref>ref>range>index>all,一般来说,得保证查询至少达到range级别,最好能达到ref级别
Extra:包含不适合在其他列中显示但十分重要的额外信息
Q. Nagle算法(雷火)
该算法主要用于避免过多小分节报文在网络中传输,从而降低网络容量利用率。
if there is new data to send #有数据要发送
# 发送窗口缓冲区和队列数据 >=mss,队列数据(available data)为原有的队列数据加上新到来的数据
# 也就是说缓冲区数据超过mss大小,nagle算法尽可能发送足够大的数据包
if the window size >= MSS and available data is >= MSS
send complete MSS segment now # 立即发送
else
if there is unconfirmed data still in the pipe # 前一次发送的包没有收到ack
# 将该包数据放入队列中,直到收到一个ack再发送缓冲区数据
enqueue data in the buffer until an acknowledge is received
else
send data immediately # 立即发送
end if
end if
end if
-
对于MSS的片段直接发送
-
如果有没有被确认的data在缓冲区内,先将待发送的数据放到buffer中直到被发送的数据被确认【最多只能有一个未被确认的小分组】
-
两种情况置位,就直接发送数据,实际上如果小包,但是没有未被确认的分组,就直接发送数据。
Q. shutdown()和close()有什么区别?(雷火)
- shutdown()和close()函数的区别
- linux网络编程之shutdown() 与 close()函数详解
- 浅谈shutdown()和close()的区别
- socket shutdown和close的区别
shutdown()函数可以选择关闭全双工连接的读通道或者写通道,如果两个通道同时关闭,则这个连接不能再继续通信。close()函数会同时关闭全双工连接的读写通道,除了关闭连接外,还会释放套接字占用的文件描述符。而shutdown()只会关闭连接,但是不会释放占用的文件描述符。
调用close()是关闭TCP连接的正常方式,但这种方式存在两个限制,而这正是引入shutdown()的原因:
(1)如果有多个进程共享一个套接字,close()其实只是将socket fd的引用计数减1,只有当该socket fd的引用计数减至0时,TCP传输层才会发起4次握手从而真正关闭连接。而shutdown则可以直接发起关闭连接所需的4次握手,而不用受到引用计数的限制;
(2)close()会终止TCP的双工链路。由于TCP连接的全双工特性,有时候我们需要告知对端我们已经完成了数据发送,我们仅仅需要关闭数据发送的一个通道,但是我们还是可以接收到对端发送过来的数据,这种控制只有利用shutdown()函数才能实现。
close()关闭本进程的socket id,但链接还是开着的,用这个socket id的其它进程还能用这个链接,能读或写这个socket id;而shutdown()则破坏了socket 链接。这也解释了,在多进程中如果一个进程中shutdown(sfd,SHUT_RDWR)后其它的进程将无法进行通信.;如果一个进程close(sfd)将不会影响到其它进程。
Q. C++11新特性(雷火)
(1)auto
用auto的时候,编译器根据上下文情况,确定auto变量的真正类型,auto在C++14中可以作为函数的返回值。
(2)nullptr
统 C++ 会把 NULL、0 视为同一种东西,这取决于编译器如何定义 NULL,因此会导致一些问题。关键字nullptr是std::nullptr_t类型的值,用来指代空指针。nullptr和任何指针类型以及类成员指针类型的空值之间可以发生隐式类型转换,同样也可以隐式转换为bool型(取值为false)。
(3)智能指针 shared_ptr、unique_ptr、weak_ptr
(4)基于范围的for循环
为了在遍历容器时支持”foreach”用法,C++11扩展了for语句的语法。如果你只是想对集合或数组的每个元素做一些操作,而不关心下标、迭代器位置或者元素个数,那么这种foreach的for循环将会非常有用。
int nums = {1,2,3};
for(int num: nums)
{
...
}
(5)lambda函数
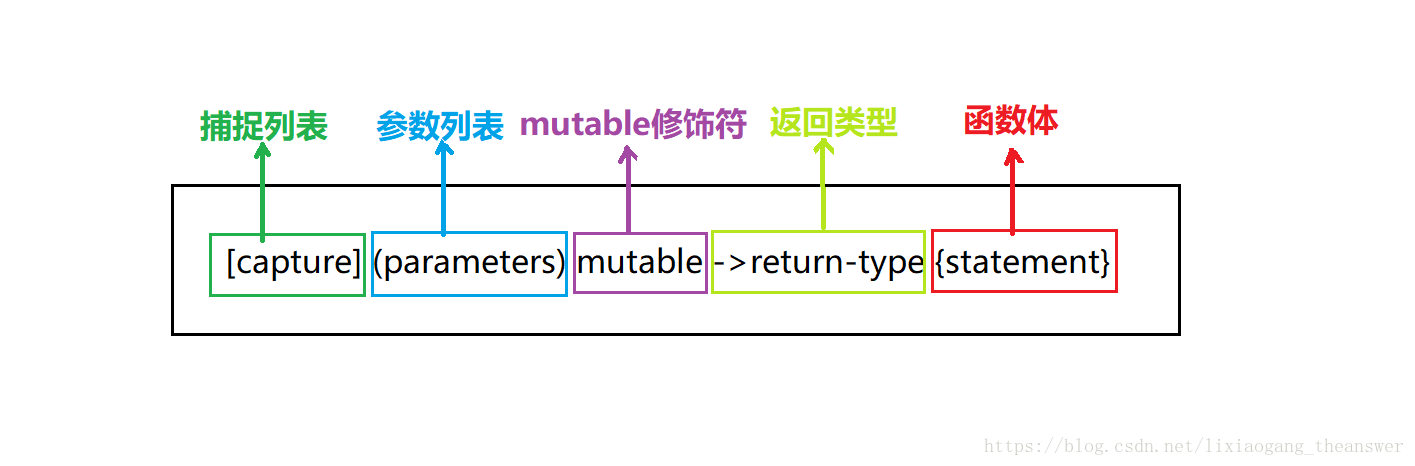
(6)move语义
C++11加入了右值引用(rvalue reference)的概念(用&&标识),用来区分对左值和右值的引用。左值就是一个有名字的对象,而右值则是一个无名对象(临时对象)。move语义允许修改右值(以前右值被看作是不可修改的,等同于const T&类型)。
(7)可变参数模板
在 C++11 之前,不论是类模板或是函数模板,都只能按其被声明时所指定的样子,接受一组数目固定的模板参数。C++11 加入新的表示法,允许任意个数、任意类型的模板参数,不必在定义时将参数的个数固定。
template<typename... Values> class T;
(8)std::unordered_map、std::unordered_set
std::unordered_map与std::map用法基本差不多,但STL在内部实现上有很大不同,std::map使用的数据结构为二叉树,而std::unordered_map内部是哈希表的实现方式,哈希map理论上查找效率为 O ( 1 ) O(1) O(1)。但在存储效率上,哈希map需要增加哈希表的内存开销。
std::unordered_set的数据存储结构也是哈希表的方式结构,除此之外,std::unordered_set在插入时不会自动排序,这都是std::set表现不同的地方。
Q. 一般操作系统页的大小?(雷火)
windows和unix处理内存时,一个内存页的大小都为4k
Q. 两个不同进程的指针有可能指向同一个地址吗?(雷火)
应用程序的指针访问的是虚拟地址,所以两个不同的进程,可以访问相同的虚拟地址,但是每个进程的这个虚拟地址,被操作系统放在不同的物理地址上,互相没有任何关系。
Q. vector push_back时间复杂度?(雷火)
考虑 vector 每次内存扩充两倍的情况。
如果我们插入 N N N个元素, 则会引发 l g N lgN lgN次的内存扩充,而每次扩充引起的元素拷贝次数为 2 0 , 2 1 , 2 2 , . . . , 2 l g N 2^0, 2^1, 2^2, ..., 2^{lgN} 20,21,22,...,2lgN
再把所有的拷贝次数相加得到 2 0 + 2 1 + 2 2 + . . . + 2 l g N = 2 ∗ 2 l g N − 1 2^0 + 2^1 + 2^2 + ... + 2^{lgN} = 2 * 2^{lgN} - 1 20+21+22+...+2lgN=2∗2lgN−1 约为 2 N 2N 2N 次
共拷贝了 N N N次最后一个元素, 所以总的操作大概为 3 N 3N 3N,所以, 每个push_back操作分摊 3 次, 是 O ( 1 ) O(1) O(1) 的复杂度
Q. 为什么windows vector是1.5倍,linux是2倍(鹅厂)
我们先回答一个问题:为什么是成倍增长,而不是每次增长一个固定大小的容量呢?解析如上一个问题,对比可以发现采用采用成倍方式扩容,可以保证常数的时间复杂度,而增加指定大小的容量会达到 O ( n ) O(n) O(n)的时间复杂度,因此,使用成倍的方式扩容更好
现在,思考第二个问题:为什么是以 2 倍或者 1.5 倍增长,而不是以 3 倍或者 4 倍等增长呢?主要考虑是空间和时间的权衡,简单来说,空间分配的多,均摊时间复杂度低,但是浪费空间多。
那么我们再来说说1.5倍和2倍有什么区别吗?
以2倍的方式扩容,导致下一次申请的内存必然大于之前分配内存的总和,导致之前分配的内存不能再被使用,如下所示

看不懂为啥吧 ((*・∀・)ゞ→→
来再解释一遍,为啥不直接追加在原来的vector后面呢?因为一般分配器不支持 realloc(),在应用层面只能分配一块新内存,然后把旧的数据复制过去,再释放之前的内存。那么,我们的理想分配方案就是在第
N
N
N次resize()的时候能复用之前
N
−
1
N-1
N−1次释放的内存,但选择2倍的增长比如像这样
1 , 2 , 4 , 8 , 16 , 32 , . . . 1,2,4,8,16,32,... 1,2,4,8,16,32,...
可以看到到第三次resize(4)的时候,前面释放的总和只有
1
+
2
=
3
1+2=3
1+2=3,到第四次resize(8)的时候前面释放的总和只有
1
+
2
+
4
=
7
1+2+4=7
1+2+4=7,每次需要申请的空间都无法用到前面释放的内存。现在讲清楚最上面的那句话的意思了吗?
至于最开始的问题:为什么 windows vector 是1.5倍,linux 是2倍?其实在 C++ 标准中,并没有规定 vector::push_back() 要用哪一个增长因子。这是由标准库的实现者决定的。
Q. 打怪掉装备,1000种掉落物,每个掉落物有自己的概率,加起来是1,怎么随机掉一个装备出来?(雷火)
方法1. 构造容器,随机一个数,取容器中对应位置的元素
方法2. 均匀分布生成其他分布
方法3. alias method
Q. 贪心算法的思路?DP和贪心不同?贪心的场景,DP的场景?(雷火)
贪心算法就是每一步选择贡献最大的,因此贪心并不总能给出最优解,尤其当前面的状态会影响后面状态时。
首先,DP和贪心都是一种递推算法,均由局部最优解来推导全局最优解。
但是贪心算法每步做出的决策都是无法改变的,因为贪心策略是由上一步的最优解推导下一步的最优解,而之前的最优解则不作保留。
在DP中,我们认为全局最优解中一定包含某个局部最优解,但不一定是上一步的局部最优解,所以需要记录之前的所有局部最优解。
如果以自顶向下的方向看问题树(原问题作根),则我们每次只需要向下遍历代表最优解的子树就可以保证会得到整体的最优解。在DP中,我们自底向上(从叶子向根)构造子问题的解,对每一个子树的根,求出下面每一个叶子的值,并且以其中的最优值作为自身的值,其它的值舍弃。动态规划的代价就取决于可选择的数目(树的叉数)和子问题的的数目(树的节点数,或者是树的高度)。而在贪心算法中,由于每一个子树的根的值不取决于下面叶子的值,而只取决于当前问题的状况,所以它对解空间树的遍历不需要自底向上,而只需要自根开始,选择最优的路,一直走到底就可以了。
Q. 一个包含n个节点的四叉树,每个节点都有四个指向孩子节点的指针,这4n个指针中有多少个空指针?(雷火)
n个节点,每个节点有4个指向孩子的指针,所以共有4n个指针。其中,除根节点外,其余节点都有一个指针指向它们。所以空指针的个数是: 4 n − ( n − 1 ) = 3 n + 1 4n-(n-1)=3n+1 4n−(n−1)=3n+1
Q. 有一个算法的递推关系式为:T(n) = 9 T(n / 3) + n,则该算法的时间复杂度为()(雷火)
O ( n 2 ) O(n^2) O(n2)
Master 公式
T ( N ) = a ∗ T ( N / b ) + O ( N d ) T(N) = a*T(N/b) + O(N^d) T(N)=a∗T(N/b)+O(Nd)
估计递归问题复杂度的通式,只要复杂度符合以下公式,都可以套用此公式计算时间复杂度
例子:递归方式查找数组最大值 T ( N ) = 2 ∗ T ( N / 2 ) + O ( 1 ) T(N) = 2*T(N/2) + O(1) T(N)=2∗T(N/2)+O(1)
T
(
N
)
T(N)
T(N):样本量为
N
N
N 的情况下,时间复杂度
N
N
N:父问题的样本量
a
a
a:子问题发生的次数(父问题被拆分成了几个子问题,不需要考虑递归调用,只考虑单层的父子关系)
b
b
b:被拆成子问题,子问题的样本量(子问题所需要处理的样本量),比如
N
N
N 被拆分成两半,所以子问题样本量为
N
/
2
N/2
N/2
O
(
N
d
)
O(N^d)
O(Nd):剩余操作的时间复杂度,除去调用子过程之外,剩下问题所需要的代价(常规操作则为
O
(
1
)
O(1)
O(1))
l
o
g
b
a
>
d
→
log_ba > d\rightarrow
logba>d→ 复杂度为
O
(
N
l
o
g
b
a
)
O(N^{log_ba})
O(Nlogba)
l
o
g
(
b
,
a
)
=
d
→
log(b,a) = d\rightarrow
log(b,a)=d→ 复杂度为
O
(
N
d
∗
l
o
g
N
)
O(N^d * logN)
O(Nd∗logN)
l
o
g
(
b
,
a
)
<
d
→
log(b,a) < d\rightarrow
log(b,a)<d→ 复杂度为
O
(
N
d
)
O(N^d)
O(Nd)
Q. 内核空间是使用虚拟内存还是物理内存?(雷火)
linux上的虚拟内存大小为2^32(32位的X86机器上),每个进程都可以拥有4GB的虚拟地址空间。这4GB的空间又分为两部分,最高的1GB字节供内核使用,称为内核空间,每个进程都可以通过系统调用进入内核空间,因此,这1GB的内核空间为所有进程以及内核所共享。较低的3GB字节,供进程使用,称为用户空间。
Q. brk()是申请的连续还是非连续虚拟内存?申请2k的内存的具体过程?(雷火)
连续虚拟内存,因为brk是将数据段(.data)的最高地址指针_edata往高地址推
Q. 实现auto_ptr(雷火)
最开始auto_ptr的成员变量主要有T* _ptr 和 bool _owner,主要实现原理是在构造对象时赋予其管理空间的所有权,在拷贝或赋值中转移空间的所有权,在析构函数中当_owner为true(拥有所有权)时来释放所有权。
但是这存在一个问题,如果拷贝出来的对象比原来的对象先调用析构函数,则原来的对象的_owner虽然为false,但却在访问一块已经释放的空间,原因在于拷贝对象的释放会导致原对象的_ptr指向的内容跟着被释放,这就造成指针的悬挂的问题。
新版auto_ptr的实现方法还是管理空间的所有权转移,但这种实现方法中没有_owner权限拥有者。构造和析构和上述实现方法类似,但拷贝和赋值后直接将_ptr赋为空,禁止其再次访问原来的内存空间,比较简单粗暴。
Q. 进程和线程的区别(雷火)
根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
Q. 物理内存、虚拟内存(雷火)
在很久以前,还没有虚拟内存概念的时候,程序寻址用的都是物理地址。程序能寻址的范围是有限的,这取决于CPU的地址线条数。比如在32位平台下,寻址的范围是2^32也就是4G。并且这是固定的,如果没有虚拟内存,且每次开启一个进程都给4G的物理内存,就可能会出现很多问题:
- 因为我的物理内存时有限的,当有多个进程要执行的时候,都要给4G内存,很显然你内存小一点,这很快就分配完了,于是没有得到分配资源的进程就只能等待。当一个进程执行完了以后,再将等待的进程装入内存。这种频繁的装入内存的操作是很没效率的
- 由于指令都是直接访问物理内存的,那么我这个进程就可以修改其他进程的数据,甚至会修改内核地址空间的数据,这是我们不想看到的
- 因为内存时随机分配的,所以程序运行的地址也是不正确的。
于是针对上面会出现的各种问题,虚拟内存就出来了。
在之前进程分配资源介绍过一个进程运行时都会得到4G的虚拟内存。这个虚拟内存你可以认为,每个进程都认为自己拥有4G的空间,这只是每个进程认为的,但是实际上,在虚拟内存对应的物理内存上,可能只对应的一点点的物理内存,实际用了多少内存,就会对应多少物理内存。
进程开始要访问一个地址,它可能会经历下面的过程:
- 每次我要访问地址空间上的某一个地址,都需要把地址翻译为实际物理内存地址
- 所有进程共享这整一块物理内存,每个进程只把自己目前需要的虚拟地址空间映射到物理内存上
- 进程需要知道哪些地址空间上的数据在物理内存上,哪些不在(可能这部分存储在磁盘上),还有在物理内存上的哪里,这就需要通过页表来记录
- 页表的每一个表项分两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地址(如果在的话)
- 当进程访问某个虚拟地址的时候,就会先去看页表,如果发现对应的数据不在物理内存上,就会发生缺页异常
- 缺页异常的处理过程,操作系统立即阻塞该进程,并将硬盘里对应的页换入内存,然后使该进程就绪,如果内存已经满了,没有空地方了,那就找一个页覆盖,至于具体覆盖的哪个页,就需要看操作系统的页面置换算法是怎么设计的了。

Q. 线程的栈是怎么创建的?如果一个进程有100个线程,那么这个进程占多大物理空间?(雷火)
一般默认情况下,线程栈是在进程的堆中分配栈空间,每个线程拥有独立的栈空间,为了避免线程之间的栈空间踩踏,线程栈之间还会有以小块guardsize用来隔离保护各自的栈空间,一旦另一个线程踏入到这个隔离区,就会引发段错误。
Q. 怎么编程实现一个异步函数?(雷火)
异步函数:如果一个异步函数被调用时,该函数会立即返回尽管该函数规定的操作任务还没有完成。
异步调用时,调用方不等被调方返回结果就转身离去,因此必须有一种机制让被调方有了结果时能通知调用方。在同一进程中有很多手段可以利用,常用的手段是回调和消息。
- 回调:回调方式很简单:调用异步函数时在参数中放入一个函数地址,异步函数保存此地址,待有了结果后回调此函数便可以向调用方发出通知。如果把异步函数包装进一个对象中,可以用事件取代回调函数地址,通过事件处理例程向调用方发通知。
- 消息:借助 Windows 消息发通知是个不错的选择,既简单又安全。程序中定义一个用户消息,并由调用方准备好消息处理例程。被调方出来结果之后立即向调用方发送此消息,并通过 WParam 和 LParam 这两个参数传送结果。消息总是与窗口 handle 关联,因此调用方必须借助一个窗口才能接收消息,这是其不方便之处。另外,通过消息联络会影响速度,需要高速处理时回调方式更有优势。
那么我们按如下方式可以实现一个异步的Func函数:
(1)先把你要异步完成的工作单独写成一个函数
(2)在函数Func中使用CreateThtread函数将(1)中的函数创建一成一个线程,然后直接返回。
当然,写一个异步函数的方法很多,但是一个本质不会变,就是必须要依据多线程才能实现。
Q. 阻塞非阻塞的区别,阻塞IO和非阻塞IO在写文件描述符时有什么不同?(雷火)
- 理解同步异步与阻塞非阻塞的区别
- 高级IO–1 —(五种典型IO,阻塞IO,非阻塞IO,信号驱动IO,异步IO, IO多路转接)
- 关于同步、异步与阻塞、非阻塞的理解
- 阻塞IO和非阻塞IO的区别
- 阻塞与非阻塞的IO网络读写
阻塞调用: 是指调用结果返回之前,当前线程会被挂起。一直处于等待消息通知,不能够执行其他业务,调用线程只有在得到结果之后才会返回。
非阻塞调用: 指在不能立刻得到结果之前,该调用不会阻塞当前线程,而会立刻返回。
对网络读写来说,
读,
在阻塞条件下, 如果没有数据就一直等。有数据时候会读到用户指定的缓存区,但是如果数据量比较少,少于参数指定的大小,read也会立即返回,而不会一直等到数据足够。
在非阻塞条件下, 如果发现没有数据就直接返回,如果发现有数据也是采用有多少读多少的方式进行处理。
写,
在阻塞条件下, 一直等待直到写完全部的数据再返回。
非阻塞条件下, 有多少写多少。能够写多少是根据本地网络拥塞情况为标准的
Q. C从源文件到可执行文件有哪些步骤?(雷火)
1、预处理 gcc -E main.c -o main.i 头文件解析,删除注释
2、编译 gcc -S main.i -o main.s main.s为汇编语言
3、汇编 gcc -c main.s -o main.o main.o为二进制文件
4、链接 gcc -o main.o -o hello 代码中使用了别的库,此步进行链接
执行 ./a.out
Q. 协程(雷火、鹅厂)
协程,是一种用户态的轻量级线程。协程不像线程和进程那样,需要进行系统内核上的上下文切换,协程的上下文切换是由程序员决定的。
多线程编程比较困难, 因为调度程序任何时候都能中断线程, 必须记住保留锁, 去保护程序中重要部分, 防止多线程在执行的过程中断。
而协程默认会做好全方位保护, 以防止中断。我们必须显示产出才能让程序的余下部分运行。对协程来说, 无需保留锁, 而在多个线程之间同步操作, 协程自身就会同步, 因为在任意时刻, 只有一个协程运行。
总结下大概下面几点:
- 无需系统内核的上下文切换,减小开销;
- 无需原子操作锁定及同步的开销,不用担心资源共享的问题;
- 单线程即可实现高并发,单核 CPU 即便支持上万的协程都不是问题,所以很适合用于高并发处理,尤其是在应用在网络爬虫中。
由于我们可以在用户态调度协程任务,所以我们可以把一组相互依赖的任务设计为协程。这样,当一个协程任务完成之后,可以手动的进行任务切换,把当前任务挂起(yield),切换到另一个协程区工作。由于我们可以控制程序主动让出资源,很多情况下将不需要对资源进行加锁。
Q. 线程上下文(雷火)
线程在切换的过程中需要保存当前线程Id、线程状态、堆栈、寄存器状态等信息。 其中寄存器主要包括SP PC EAX等寄存器,其主要功能如下: SP:堆栈指针,指向当前栈的栈顶地址 PC:程序计数器,存储下一条将要执行的指令 EAX:累加寄存器,用于加法乘法的缺省寄存器
Q. 进程通信、线程通信(雷火)
- 什么是临界资源和临界区
- 临界区,互斥量,信号量,事件的区别
- 进程间和线程间的的的通信方式,了解一下?
- 面试官问你什么是消息队列?把这篇甩给他!
- 消息队列——介绍,应用,功能及常见问题解决方案
- 线程间通信的三种方法
- 进程间通信的方式——信号、管道、消息队列、共享内存
进程间通信方式
管道:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
有名管道: 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信
信号量: 信号量是一个计数器,可以用来控制多个进程对共享资源的访问,主要作为进程间以及同一进程内不同线程之间的同步手段。
【具体过程】
信号量允许多个进程同时使用共享资源,但是需要限制在同一时刻访问此资源的最大进程数目。在用CreateSemaphore()创建信号量时即要同时指出允许的最大资源计数和当前可用资源计数。一般是将当前可用资源计数设置为最大资源计数,每增加一个进程对共享资源的访问,当前可用资源计数就会减1,只要当前可用资源计数是大于0的,就可以发出信号量信号。但是当前可用计数减小到0时则说明当前占用资源的进程数已经达到了所允许的最大数目, 不能在允许其他进程的进入,此时的信号量信号将无法发出。进程在处理完共享资源后,应在离开的同时通过ReleaseSemaphore()函数将当前可用资源计数加1。在任何时候当前可用资源计数决不可能大于最大资源计数。
信号机制:信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生
消息队列:把要传输的数据放在队列中,把数据放到消息队列叫做生产者,从消息队列里边取数据叫做消费者
共享内存:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问
线程间通信方式
锁机制:包括互斥锁、条件变量、读写锁
【具体内容】
- 互斥锁提供了以排他方式防止数据结构被并发修改的方法。
- 读写锁允许多个线程同时读共享数据,而对写操作是互斥的。
- 条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
信号量:同进程间通信
信号机制:类似进程间的信号处理
全局变量:进程中的线程间内存共享,这是比较常用的通信方式和交互方式
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制。
Q. 你认为MQ有什么用?(雷火)
- 解耦
假如,有许多进程都要频繁的使用进程A产生的数据,那么每次当有进程需要这些数据时就需要找进程A,进程A产生数据给他们。而加入MQ之后,进程A只用一次将产生的数据放入MQ,剩下其他进程不管怎么使用这个数据都不再找进程A。 - 异步
假如有进程A、B、C,处理时间分别为100ms、10ms、20ms,其中B、C在A运行之后才能运行且同时运行,若没有消息队列,那么三个进程完成的时间就是120ms。加入消息队列就只需要100ms,因为A处理完就返回了。 - 削峰/限流
假如有两个进程,每次只能处理1个请求,但是一次进来了3个请求,多出来的一个请求就放入消息队列。
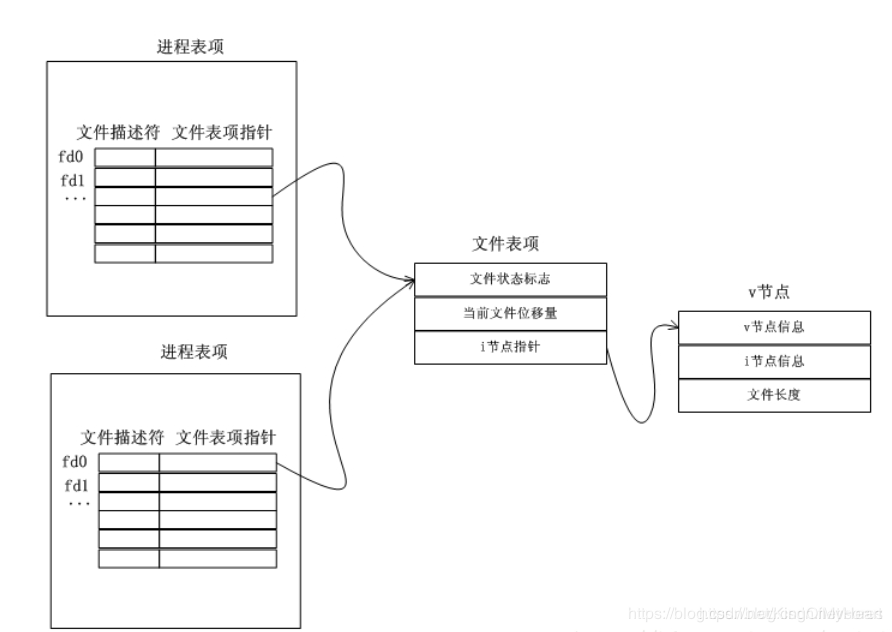
Q. 多进程编程,父进程打开了一个文件描述符,fork一个子进程,子进程调用read,此时父进程再调用read从哪开始读(雷火)
先fork()后open(),父子进程共享一个文件文件描述信息,包括引用计数、读取位置等等
Q. 函数返回值可以是引用么?(雷火)
函数在返回值的时候,会产生一个临时变量作为函数返回值的副本;而函数在返回引用的时候,不会产生副本!但引用作为返回值需注意一下几点:
(1)不能返回局部变量的引用。主要原因是局部变量会在函数返回后被销毁,因此被返回的引用就成为了"无所指"的引用,程序会进入未知状态。
(2)不能返回函数内部new分配的内存的引用。虽然不存在局部变量的被动销毁问题,可对于这种情况(返回函数内部new分配内存的引用),又面临其它尴尬局面。例如,被函数返回的引用只是作为一 个临时变量出现,而没有被赋予一个实际的变量,那么这个引用所指向的空间(由new分配)就无法释放,造成memory leak(内存泄露)。
(3)可以返回类成员的引用,但最好是const。
Q. 1个6L的水杯和一个5L的水杯,问能精确打多少升水?(雷火)
6L杯打满,倒入5L杯,6L杯得1L水
1L水倒入5L杯,6L杯打满倒入5L杯,6L杯得2L水
2L水倒入5L杯,6L杯打满倒入5L杯,6L杯得3L水
3L水倒入5L杯,6L杯打满倒入5L杯,6L杯得4L水
Q. 在公司局域网上ping www.taobao.com没有涉及到的网络协议是()(雷火)
没有TCP协议
DNS是将域名www.taobao.com映射成主机的IP地址,ARP是将IP地址映射成物理地址,ICMP是报文控制协议,由路由器发送给执行ping命令的主机,而一个ping命令并不会建立一条TCP连接,故没有涉及TCP协议。
Q. 说一下C++和C的区别
设计思想上:
C++是面向对象的语言,而C是面向过程的结构化编程语言
语法上:
C++具有封装、继承和多态三种特性
C++相比C,增加多许多类型安全的功能,比如强制类型转换
C++支持范式编程,比如模板类、函数模板等
Q. 给定三角形ABC和一点P(x,y,z),判断点P是否在ABC内,给出思路并手写代码
利用面积法,如图所示,如果点P在三角形ABC的内部,则三个小三角形PAB,PBC,PAC的面积之和 = ABC的面积,反之则不相等。
提示:三角形面积用海伦公式

Q. 请回答一下数组和指针的区别
Q. 进程切换上下文细节(鹅厂)
进程上下文
当一个进程从内核中移出,另一个进程成为活动的,这些进程之间便发生了上下文切换。操作系统必须记录重启进程和启动新进程使之活动所需要的所有信息,这些信息被称作上下文。它描述了进程的现有状态。进程上下文实际上是进程执行活动全过程的静态描述,可以看作是用户进程传递给内核的一些参数以及内核要保存的一整套的变量和寄存器值以及当时的环境等。
进程的上下文信息包括, 指向可执行文件的指针,栈,内存(数据段和堆),进程状态,优先级,程序I/O的状态,授予权限,调度信息,审计信息,有关资源的信息(文件描述符和读/写指针),关事件和信号的信息,寄存器组(栈指针,指令计数器)等等。
处理器总处于以下三种状态之一:
1. 内核态,运行于进程上下文,内核代表进程运行于内核空间;
2. 内核态,运行于中断上下文,内核代表硬件运行于内核空间;
3. 用户态,运行于用户空间。
用户空间的应用程序,通过系统调用,进入内核空间。这个时候用户空间的进程要传递很多变量和参数值给内核,内核态运行的时候也要保存用户进程的一些寄存器值、变量等,即所谓的进程上下文。
硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理。所谓的中断上下文,其实也可以看作就是硬件传递过来的一些参数和内核需要保存的一些其他环境(主要是当前被打断执行的进程环境)。
【Linux 完全注释中有一段话】
当一个进程在执行时,CPU 的所有寄存器中的值、进程的状态以及堆栈中的内容被称为该进程的上下文。当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的上下文,以便在再次执行该进程时,能够必得到切换时的状态执行下去。在 Linux 中,当前进程上下文均保存在进程的任务数据结构中。在发生中断时,内核就在被中断的进程的上下文中,在内核态下执行中断服务例程。同时,内核会保留所有需要用到的资源,以便中继服务结束时能恢复被中断进程的执行。
上下文切换
进程被抢占 CPU 的时候,操作系统会保存其上下文信息,同时将新的活动进程的上下文信息加载进来,这个过程其实就是上下文切换,而当一个被抢占的进程再次成为活动的,它可以恢复自己的上下文继续从被抢占的位置开始执行
上下文切换(有时也称做进程切换或任务切换)是指 CPU 从一个进程或线程切换到另一个进程或线程
稍微详细地描述一下,上下文切换可以认为是内核在 CPU 上对于进程(包括线程)进行以下的活动:
- 挂起一个进程,将这个进程在 CPU 中的状态(上下文)存储于内存中的某处
- 在内存中检索下一个进程的上下文并将其在 CPU 的寄存器中恢复
- 跳转到程序计数器所指向的位置(即跳转到进程被中断时的代码行),以恢复该进程
因此上下文是指某一时间点CPU寄存器和程序计数器的内容,广义上还包括内存中进程的虚拟地址映射信息。
上下文切换只能发生在内核态中,上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒进行几十到上百次的切换,每次切换只需要纳秒量级的时间。所以,上下文切换对系统来说意味着需要消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
Linux 相比与其他操作系统有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
context_switch 进程上下文切换
Linux 中进程调度时, 内核在选择新进程之后进行抢占时, 通过 context_switch 完成进程上下文切换。
【注意】 进程调度与抢占的区别
进程调度不一定发生抢占, 但是抢占时却一定发生了调度
在进程发生调度时, 只有内核中的当前进程因为主动或者被动需要放弃 CPU 时, 内核才会选择一个与当前活动进程不同的进程来抢占 CPU
context_switch 其实是一个分配器, 它会调用所需的特定的体系结构的方法。
-
调用
switch_mm(),把虚拟内存从一个进程映射切换到新进程中 -
switch_mm()更换通过task_struct->mm描述的内存管理上下文, 该工作的细节取决于处理器, 主要包括加载页表, 刷出地址转换后备缓冲器(部分或者全部), 向内存管理单元(MMU)提供新的信息 -
调用
switch_to(),从上一个进程的处理器状态切换到新进程的处理器状态。这包括保存、恢复栈信息和寄存器信息 -
switch_to()切换处理器寄存器的内容和内核栈(虚拟地址空间的用户部分已经通过switch_mm()变更, 其中也包括了用户状态下的栈, 因此switch_to()不需要变更用户栈, 只需变更内核栈), 此段代码严重依赖于体系结构, 且代码通常都是用汇编语言编写 -
context_switch()函数建立 next 进程的地址空间。进程描述符的active_mm字段指向进程所使用的内存描述符,而mm字段指向进程所拥有的内存描述符。对于一般的进程,这两个字段有相同的地址,但是,内核线程没有它自己的地址空间而且它的mm字段总是被设置为NULL -
context_switch( )函数保证:如果 next 是一个内核线程, 它使用 prev 所使用的地址空间,
由于不同架构下地址映射的机制有所区别, 而寄存器等信息也依赖于架构, 因此switch_mm和switch_to两个函数均是体系结构相关的
prepare_arch_switch 切换前的准备工作
在进程切换之前,首先执行调用每个体系结构都必须定义的 prepare_task_switch() 挂钩,这使得内核执行特定的体系结构代码,为切换做事先准备。 大多数支持的体系结构都不需要该选项。
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next); /* 完成进程切换的准备工作 */
next 是内核线程时的处理
由于用户空间进程的寄存器内容在进入核心态时保存在内核栈中, 在上下文切换期间无需显式操作。因为每个进程首先都是从核心态开始执行(在调度期间控制权传递给新进程), 在返回用户空间时,会使用内核栈上保存的值自动恢复寄存器数据。
而内核线程没有自身的用户空间上下文,其task_struct->mm为NULL, 从当前进程 “借来” 的地址空间记录在active_mm中,于是,
/* 如果next是内核线程,则线程使用prev所使用的地址空间
* schedule( )函数把该线程设置为懒惰TLB模式
* 内核线程并不拥有自己的页表集(task_struct->mm = NULL)
* 它使用一个普通进程的页表集
* 不过,没有必要使一个用户态线性地址对应的TLB表项无效
* 因为内核线程不访问用户态地址空间。
*/
if (!mm) /* 内核线程无虚拟地址空间, mm = NULL*/
{
/* 内核线程的active_mm为上一个进程的mm
* 注意此时如果prev也是内核线程,
* 则oldmm为NULL, 即next->active_mm也为NULL */
next->active_mm = oldmm;
/* 增加mm的引用计数 */
atomic_inc(&oldmm->mm_count);
/* 通知底层体系结构不需要切换虚拟地址空间的用户部分
* 这种加速上下文切换的技术称为惰性TLB */
enter_lazy_tlb(oldmm, next);
}
else /* 不是内核线程, 则需要切切换虚拟地址空间 */
switch_mm(oldmm, mm, next);
switch_to 完成进程切换
最后调用switch_to()完成进程的切换, 该函数切换了寄存器的状态和栈, 新进程在该调用后开始执行,而switch_to()之后的代码只有在当前进程下一次被选择运行时才会执行
内核在switch_to()中执行如下操作:
- 进程切换,即 esp 的切换,因为从 esp 可以找到进程的描述符
- 硬件上下文切换,设置 ip 寄存器的值,并跳转到
__switch_to函数 - 堆栈的切换,即 ebp 的切换,ebp 是栈底指针,它确定了当前用户空间属于哪个进程
【为什么switch_to需要3个参数】
#define switch_to(prev, next, last)
我们考虑这个样一个例子,假定多个进程 A,B,C 在系统上运行,在某个时间点,内核决定从进程 A 切换到进程 B,此时 prev = A,next = B,即执行了 switch_to(A,B),而后当被抢占的进程 A 再次被选择执行的时候,系统可能进行了多次进程切换/抢占(至少会经历一次即再次从 B 到 A),假设 A 再次被选择执行时当前活动进程是 C,即此时 prev = C, next = A
但是,在进程 A 被选中再次执行的时候,会出现一个问题:此时控制权即将回到 A,switch_to函数返回,内核开始执行switch_to之后的点,此时内核栈准确的恢复到切换之前的状态,即进程 A 上次被切换出去时的状态,prev = A,next = B,此时,内核无法知道实际上在进程 A 之前运行的是进程 C
于是,在进程被选中重新执行时,内核恢复到进程被切换出去的点继续执行,此时内核只知道谁之前将该进程抢占了,但是却不知道该进程再次执行是抢占了谁。在新进程被选中时,底层的进程切换例程必须将此前执行的进程提供给 context_switch,由于控制流会回到该函数的中间,这样无法用普通的函数返回值来做到,因此提供了 3 个参数的宏。但是逻辑效果是相同的,仿佛是switch_to()是带有两个参数的函数,而且返回了一个指向此前运行的进程的指针。
在上个例子中,进程 A 提供给 switch_to 的参数是 prev = A,next = B,然后控制权从A交给了B,但是恢复执行的时候是通过 prev = C,next = A 完成了再次调度,而后内核恢复了进程 A 被切换之前的内核栈信息,即prev = A,next = B,内核为了通知调度机制 A 抢占了 C 的处理器,就通过last参数传递回来,prev = last = C
switch_mm()进行用户空间的切换,更确切地说,是切换地址转换表(pgd), 由于 pgd 包括内核虚拟地址空间和用户虚拟地址空间的地址映射,Linux 内核把进程的整个虚拟地址空间分成两个部分, 一部分是内核虚拟地址空间,另一部分是用户虚拟地址空间,各个进程的虚拟地址空间各不相同,但是却共用了同样的内核地址空间,这样在进程切换的时候,就只需要切换虚拟地址空间的用户空间部分。
每个进程都有其自身的页目录表(pgd),在进程本身尚未切换时, 存储管理机制的页目录指针 cr3 却已经切换了,这样不会造成问题吗?不会的,因为这个时候 CPU 在系统空间运行,而所有进程的页目录表中与系统空间对应的目录项都指向相同的页表,所以,不管切换到哪一个进程的页目录表都一样,受影响的只是用户空间,系统空间的映射则永远不变
barrier 路障同步
witch_to()完成了进程的切换,新进程在该调用后开始执行,而switch_to之后的代码只有在当前进程下一次被选择运行时才会执行。
而为了程序编译后指令的执行顺序不会因为编译器的优化而改变,因此内核提供了路障同步barrier来保证程序的执行顺序。
finish_task_switch 完成清理工作
finish_task_switch()完成一些清理工作,使得能够正确的释放锁,但我们不会详细讨论这些。 它会向各个体系结构提供另一个挂钩上下切换过程的可能性,当然这只在少数计算机上需要。
context_switch 完全代码注释
/*
* context_switch - switch to the new MM and the new thread's register state.
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
/* 完成进程切换的准备工作 */
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
/* 如果next是内核线程,则线程使用prev所使用的地址空间
* schedule( )函数把该线程设置为懒惰TLB模式
* 内核线程并不拥有自己的页表集(task_struct->mm = NULL)
* 它使用一个普通进程的页表集
* 不过,没有必要使一个用户态线性地址对应的TLB表项无效
* 因为内核线程不访问用户态地址空间。
*/
if (!mm) /* 内核线程无虚拟地址空间, mm = NULL*/
{
/* 内核线程的active_mm为上一个进程的mm
* 注意此时如果prev也是内核线程,
* 则oldmm为NULL, 即next->active_mm也为NULL */
next->active_mm = oldmm;
/* 增加mm的引用计数 */
atomic_inc(&oldmm->mm_count);
/* 通知底层体系结构不需要切换虚拟地址空间的用户部分
* 这种加速上下文切换的技术称为惰性TBL */
enter_lazy_tlb(oldmm, next);
}
else /* 不是内核线程, 则需要切切换虚拟地址空间 */
switch_mm(oldmm, mm, next);
/* 如果prev是内核线程或正在退出的进程
* 就重新设置prev->active_mm
* 然后把指向prev内存描述符的指针保存到运行队列的prev_mm字段中
*/
if (!prev->mm)
{
/* 将prev的active_mm赋值和为空 */
prev->active_mm = NULL;
/* 更新运行队列的prev_mm成员 */
rq->prev_mm = oldmm;
}
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
lockdep_unpin_lock(&rq->lock);
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
/* Here we just switch the register state and the stack.
* 切换进程的执行环境, 包括堆栈和寄存器
* 同时返回上一个执行的程序
* 相当于prev = witch_to(prev, next) */
switch_to(prev, next, prev);
/* switch_to之后的代码只有在
* 当前进程再次被选择运行(恢复执行)时才会运行
* 而此时当前进程恢复执行时的上一个进程可能跟参数传入时的prev不同
* 甚至可能是系统中任意一个随机的进程
* 因此switch_to通过第三个参数将此进程返回
*/
/* 路障同步, 一般用编译器指令实现
* 确保了switch_to和finish_task_switch的执行顺序
* 不会因为任何可能的优化而改变 */
barrier();
/* 进程切换之后的处理工作 */
return finish_task_switch(prev);
}
Q. 线程切换上下文细节(鹅厂)
线程切换上下文的细节已经在上面进程的内容中有所体现,这里就讲得比较粗糙了
通过上面的讲述知道,进程切换分两步
- 切换页目录以使用新的地址空间
- 切换内核栈和硬件上下文
但是,线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。所谓内核中的任务调用,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
于是,线程的上下文切换,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据,寄存器等不共享的数据,即只有上面的第 2 个步骤
Q. 解释型语言和编译型语言的区别(鹅厂)
用编译型语言写的程序执行之前,需要一个专门的编译过程,通过编译系统(不仅仅只是通过编译器,编译器只是编译系统的一部分)把高级语言翻译成机器语言(具体翻译过程可以参看下图),把源高级程序编译成为机器语言文件,比如windows下的exe文件。以后就可以直接运行而不需要编译了,因为翻译只做了一次,运行时不需要翻译,所以编译型语言的程序执行效率高,但也不能一概而论,部分解释型语言的解释器通过在运行时动态优化代码,甚至能够使解释型语言的性能超过编译型语言。

解释则不同,解释型语言编写的程序不需要编译。解释型语言在运行的时候才翻译,比如VB语言,在执行的时候,专门有一个解释器能够将VB语言翻译成机器语言,每个语句都是执行的时候才翻译。这样解释型语言每执行一次就要翻译一次。
编译型与解释型,两者各有利弊。前者由于程序执行速度快,同等条件下对系统要求较低,因此像开发操作系统、大型应用程序、数据库系统等时都采用它,像C/C++、Pascal/Object Pascal(Delphi)等都是编译语言,而一些网页脚本、服务器脚本及辅助开发接口这样的对速度要求不高、对不同系统平台间的兼容性有一定要求的程序则通常使用解释性语言,如JavaScript、VBScript、Perl、Python、Ruby、MATLAB 等等。
Q. STL底层内存分配(鹅厂)
隐藏在 vector 这些容器后的内存管理工作是通过 STL 提供的一个默认的 allocator 实现的。这个 allocator 是一个由两级分配器构成的内存管理器,当申请的内存大小大于 128byte 时,就启动第一级分配器通过 malloc 直接向系统的堆空间分配;如果申请的内存大小小于 128byte 时,就启动第二级分配器,从一个预先分配好的内存池中取一块内存交付给用户,这个内存池由 16 个不同大小(8的倍数,8~128byte)的空闲列表组成,allocator 会根据申请内存的大小(将这个大小四舍五入取为8的倍数)从对应的空闲块列表取表头块给用户。
这种做法有两个优点:
1)小对象的快速分配。
小对象是从内存池分配的,这个内存池是系统调用一次 malloc 分配一块足够大的区域给程序备用,当内存池耗尽时再向系统申请一块新的区域,整个过程类似于批发和零售,起先是由 allocator 向总经商批发一定量的货物,然后零售给用户,与每次都向总经商要一个货物再零售给用户的过程相比,显然是快捷了。当然,这里的一个问题时,内存池会带来一些内存的浪费,比如当只需分配一个小对象时,为了这个小对象可能要申请一大块的内存池,但这个浪费还是值得的,况且这种情况在实际应用中也并不多见。
2)避免了内存碎片的生成。
程序中的小对象的分配极易造成内存碎片,给操作系统的内存管理带来了很大压力,系统中碎片的增多不但会影响内存分配的速度,而且会极大地降低内存的利用率。以内存池组织小对象的内存,从系统的角度看,只是一大块内存池,看不到小对象内存的分配和释放。
实现时,allocator 需要维护一个存储16个空闲块列表表头的数组 free_list,数组元素
i
i
i 是一个指向块大小为
8
∗
(
i
+
1
)
8*(i+1)
8∗(i+1) 字节的空闲块列表的表头,一个指向内存池起始地址的指针start_free和一个指向结束地址的指针end_free。空闲块列表节点的结构如下:
union obj {
union obj *free_list_link; // 当作为自由链表的一个结点时,存储其下一个节点的地址
char client_data[1]; // 当其作为返回值时,返回的正好是分配内存的首地址
};
这个结构可以看做是从一个内存块中抠出4个字节大小来存储节点头结构,结构体中client_data返回的实际上是可用的内存块地址。free_list中找到合适的块后,会将下一个空闲块的地址写在原来这个free_list数组元素的位置。一般而言内存块是连续的。因此,allocator 中的空闲块链表可以表示成:
obj* free_list[16];
Q. 12个瓶子,其中有一个不知道轻重,你如何查出来(鹅厂)
把12个瓶子分成4份,每份3个1份。
任意取2份去称,若平衡,则次品在剩下的2份中,若不平衡,则次品在被称量的这2份中。于是,可以把4份分为有次品的和没有次品的
任意取出有次品的一份,和没有次品的一份进行称量。若平衡,则说明当前这份认为有次品的实则是无次品的,于是,对剩下的唯一的那份有次品的进行称量就行。若不平衡,则说明当前这份的确含有次品,同样对这一份进行称量就行。
Q. 某个线程CPU占比高,你如何排查出问题(鹅厂)
(1)输入top命令查看CPU占比
(2)输入top -c命令可以看到更完整的信息,输入大写P,top的输出会按使用cpu多少排序,此时我们可以看到进程的PID
(3)输入top -H 进程号,同样输入大写P,top的输出会按使用cpu多少排序。由此可以找到耗CPU的线程
(4)输入pstack 进程号,并搜索线程号对应的堆栈,可以用来帮助排查问题
如果整个系统的各个服务CPU占比都比正常情况高,这时候要使用vmstat命令,输入vmstat 2是指2秒会统计一次CPU信息
Q. TCP/IP议栈的每一层的作用分别是什么?(鹅厂)
4 层,应用层,传输层,网络层,网络接口层
应用层
TCP/IP协议族在这一层面有着很多协议来支持不同的应用,许多大家所熟悉的基于Internet的应用的实现就离不开这些协议。如我们进行万维网(WWW)访问用到了HTTP协议、文件传输用FTP协议、电子邮件发送用SMTP、域名的解析用DNS协议、远程登录用Telnet协议等等,都是属于TCP/IP应用层的;就用户而言,看到的是由一个个软件所构筑的大多为图形化的操作界面,而实际后台运行的便是上述协议。(FTP、SMTP、telnet、DNS、tftp)
传输层
这一层的的功能主要是提供应用程序间的通信,TCP/IP协议族在这一层的协议有TCP和UDP(TCP、UDP)
网络层
是TCP/IP协议族中非常关键的一层,主要定义了IP地址格式,从而能够使得不同应用类型的数据在Internet上通畅地传输,实现路由和转发。(IP数据包)
网络接口层
这是TCP/IP软件的最低层,负责接收IP数据包并通过网络发送之,或者从网络上接收物理帧,抽出IP数据报,交给IP层。(帧,网络接口协议)
Q. HTTPs 如何保证安全性?(鹅厂)
什么是HTTPs
HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL
HTTPs的作用
- 内容加密,建立一个信息安全通道,来保证数据传输的安全
- 身份认证,确认网站的真实性
- 数据完整性,防止内容被第三方冒充或者篡改
HTTPs和HTTP的区别
- HTTPs协议需要到CA申请证书
- HTTP是超文本传输协议,信息是明文传输;HTTPs 则是具有安全性的ssl加密传输协议
- HTTP和HTTPs使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443
- HTTP的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比HTTP协议安全。
HTTPs 如何保证安全性
下面就是https的整个架构,现在的https基本都使用TLS了,因为更加安全,所以下图中的SSL应该换为SSL/TLS。
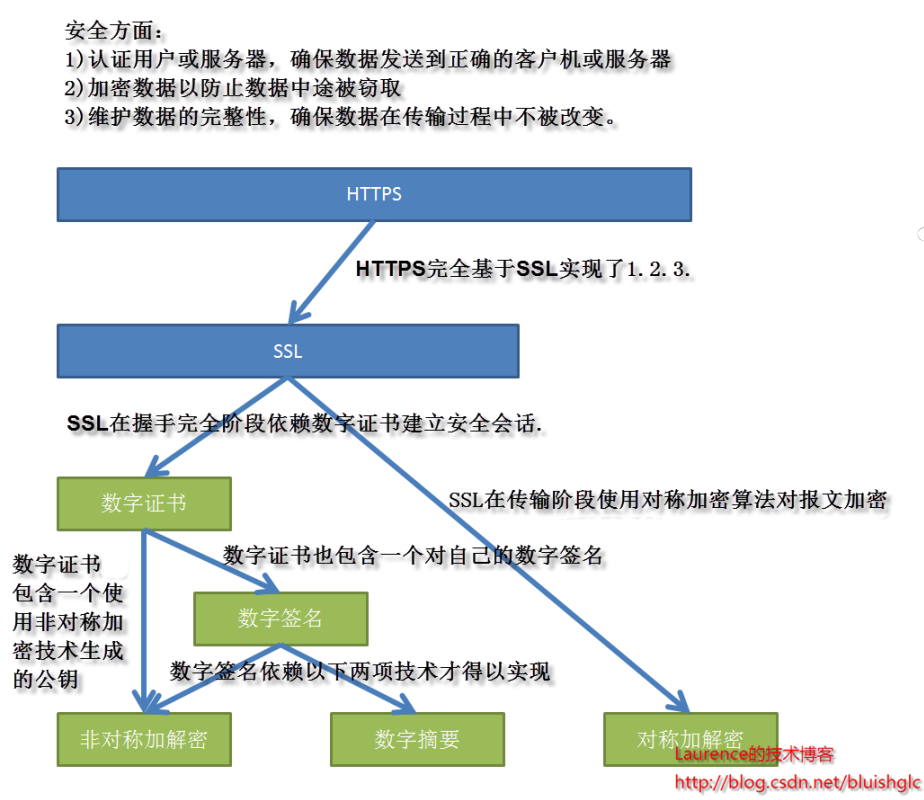
下面逐个对上图中的知识点进行介绍:
对称加密
对称加密(也叫私钥加密)指加密和解密使用相同密钥的加密算法。有时又叫传统密码算法,就是加密密钥能够从解密密钥中推算出来,同时解密密钥也可以从加密密钥中推算出来。而在大多数的对称算法中,加密密钥和解密密钥是相同的,所以也称这种加密算法为秘密密钥算法或单密钥算法。
非对称加密
与对称加密算法不同,非对称加密算法需要两个密钥:公开密钥(publickey)和私有密钥(privatekey);并且加密密钥和解密密钥是成对出现的。非对称加密算法在加密和解密过程使用了不同的密钥,非对称加密也称为公钥加密,在密钥对中,其中一个密钥是对外公开的,所有人都可以获取到,称为公钥,其中一个密钥是不公开的称为私钥。
摘要算法
数字摘要是采用单项Hash函数将需要加密的明文“摘要”成一串固定长度(128位)的密文,这一串密文又称为数字指纹,它有固定的长度,而且不同的明文摘要成密文,其结果总是不同的,而同样的明文其摘要必定一致。“数字摘要“是HTTPs能确保数据完整性和防篡改的根本原因。
数字签名
数字签名技术就是对“非对称密钥加解密”和“数字摘要“两项技术的应用,它将摘要信息用发送者的私钥加密,与原文一起传送给接收者。接收者只有用发送者的公钥才能解密被加密的摘要信息,然后用HASH函数对收到的原文产生一个摘要信息,与解密的摘要信息对比。如果相同,则说明收到的信息是完整的,在传输过程中没有被修改,否则说明信息被修改过,因此数字签名能够验证信息的完整性。
数字签名的过程如下:
明文 --> hash运算 --> 摘要 --> 私钥加密 --> 数字签名
数字证书
为什么要有数字证书?
对于请求方来说,它怎么能确定它所得到的公钥一定是从目标主机那里发布的,而且没有被篡改过呢?亦或者请求的目标主机本本身就从事窃取用户信息的不正当行为呢?这时候,我们需要有一个权威的值得信赖的第三方机构(一般是由政府审核并授权的机构)来统一对外发放主机机构的公钥,只要请求方这种机构获取公钥,就避免了上述问题的发生。
数字证书的颁发过程
用户首先产生自己的密钥对,并将公共密钥及部分个人身份信息传送给认证中心。认证中心在核实身份后,将执行一些必要的步骤,以确信请求确实由用户发送而来,然后,认证中心将发给用户一个数字证书,该证书内包含用户的个人信息和他的公钥信息,同时还附有认证中心的签名信息(根证书私钥签名)。用户就可以使用自己的数字证书进行相关的各种活动。数字证书由独立的证书发行机构发布,数字证书各不相同,每种证书可提供不同级别的可信度。
验证证书的有效性
浏览器默认都会内置CA根证书,其中根证书包含了CA的公钥
- 证书颁发的机构是伪造的:浏览器不认识,直接认为是危险证书
- 证书颁发的机构是确实存在的,于是根据CA名,找到对应内置的CA根证书、CA的公钥。用CA的公钥,对伪造的证书的摘要进行解密,发现解不了,认为是危险证书。
- 对于篡改的证书,使用CA的公钥对数字签名进行解密得到摘要A,然后再根据签名的Hash算法计算出证书的摘要B,对比A与B,若相等则正常,若不相等则是被篡改过的。
- 证书可在其过期前被吊销,通常情况是该证书的私钥已经失密。较新的浏览器如Chrome、Firefox、Opera和Internet Explorer都实现了在线证书状态协议(OCSP)以排除这种情形:浏览器将网站提供的证书的序列号通过OCSP发送给证书颁发机构,后者会告诉浏览器证书是否还是有效的。
1、2点是对伪造证书进行的,3是对于篡改后的证书验证,4是对于过期失效的验证。
Q. 平衡二叉树删除和插入的时间复杂度(鹅厂)

Q. HTTP请求过程(鹅厂)
根据域名解析IP地址
浏览器根据访问的域名找到其IP地址。DNS 查找过程如下:
- 浏览器缓存:首先搜索浏览器自身的 DNS 缓存(缓存的时间比较短,大概只有1分钟,且只能容纳1000条缓存),看自身的缓存中是否是有域名对应的条目,而且没有过期,如果有且没有过期则解析到此结束。
- 系统缓存:如果浏览器自身的缓存里面没有找到对应的条目,那么浏览器会搜索操作系统自身的 DNS 缓存,如果找到且没有过期则停止搜索解析到此结束。
- 路由器缓存:如果系统缓存也没有找到,则会向路由器发送查询请求。
- ISP(互联网服务提供商) DNS缓存:如果在路由缓存也没找到,最后要查的就是ISP缓存DNS的服务器。
与WEB服务器建立一个TCP连接
TCP的3次握手
给WEB服务器发送一个HTTP请求
一个HTTP请求报文由请求行(request line)、请求头部(headers)、空行(blank line)和请求数据(request body)4个部分组成。

【插一句】
讲下请求头参数,一样是鹅厂问的
请求行
请求行分为三个部分:请求方法、请求地址 URL 和 HTTP 协议版本
请求头部
请求头部为请求报文添加了一些附加信息,由 “名/值” 对组成,每行一对,名和值之间使用冒号分隔。

【再插一句】
讲下请求方法里面 GET 和 POST 的区别,一样是鹅厂问到的
GET(完整请求一个资源)
当客户端要从服务器中读取文档时,当点击网页上的链接或者通过在浏览器的地址栏输入网址来浏览网页的,使用的都是 GET 方式。GET 方法要求服务器将 URL 定位的资源放在响应报文的数据部分,发送给客户端。
POST(提交表单)
允许客户端给服务器提供信息较多。POST方法将请求参数封装在 HTTP 请求数据中,以名称/值的形式出现,可以传输大量数据,这样POST方式对传送的数据大小没有限制,而且也不会显示在URL中。
最后附上 HTTP 请求方法的一个汇总表

** 服务器端响应HTTP请求,浏览器得到HTML代码**
HTTP响应报文由状态行(status line)、相应头部(headers)、空行(blank line)和响应数据(response body)4个部分组成。

【插一句】
状态行
状态行由3部分组成,分别为:协议版本、状态码、状态码扫描。其中协议版本与请求报文一致,状态码描述是对状态码的简单描述。

浏览器解析HTML代码,并请求HTML代码中的资源
浏览器拿到HTML文件后,开始解析HTML代码,遇到静态资源时,就向服务器端去请求下载。
关闭TCP连接,浏览器对页面进行渲染呈现给用户
浏览器利用自己内部的工作机制,把请求到的静态资源和HTML代码进行渲染,呈现给用户。
Q. 1000个苹果分10个箱装(鹅厂)
1000个苹果放入10个箱子。客户如果要获得1~1000个苹果中的任意个数,都可以整箱搬,而不用拆开箱子。问是否有这样的装箱方法?
二进制数组合:
1
10
100
1000
可以表示任何0x01~0xFF之间的数字,所以按照这样的思想,
1
10
100
1000
10000
100000
1000000
10000000
100000000
1000000000
可以表示任何1~0x10FF的数,即1~1024的数,而一共只有1000个苹果,所以数列应该为
1, 2,4, 8, 16, 32, 64, 128, 256, 489
Q. 进程挂了共享内存是否还存在,为什么?(鹅厂)
进程间通信使用的数据结构:管道、socket、共享内存、消息队列、信号量等,是属于内核级的,一旦创建后就由内核管理,若进程不对其主动释放,那么这些变量会一直存在,除非重启系统。
Q. 数据包MTU(最大传输单元)
** 数据链路层的以太网帧结构**

以太网帧结构由四个字段组成,各字段含义为:
目的地址:该地址指的是MAC地址,指该数据要发送至哪里
源地址:MAC地址,填本地MAC地址,指该数据从哪里来
类型:值该数据要交给上层(网络层)的那个协议(IP协议,ARP协议…)
数据:要传输的数据,不过该数据有长度的要求,是在46–1500字节之间,该长度称为最大传输单元即MTU
若数据长度不够46字节,则需要填充内容;若数据长度超过1500字节,则需要分片传输。
MTU对IP协议的影响
- IP报文在超过MTU后需要分片,接收端需要组装;
- 由于MTU影响的IP报文的分片和组装会加大报文丢失的可能性;
- 一旦分片后的IP报文有一部分丢失,则接收端组装会失败,对于整个IP报文而言相当于传输失败,而IP协议不会负责重新传输数据;
- 报文的分片和组装由IP层自己做,会加大传输的成本,降低性能。
Q. 自旋锁、悲观锁、乐观锁(鹅厂)
自旋锁
自旋锁(spinlock):是指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环。
自旋锁的优缺点
自旋锁尽可能的减少线程的阻塞,这对于锁的竞争不激烈,且占用锁时间非常短的代码块来说性能能大幅度的提升,因为自旋的消耗会小于线程阻塞挂起再唤醒的操作的消耗,这些操作会导致线程发生两次上下文切换!
但是如果锁的竞争激烈,或者持有锁的线程需要长时间占用锁执行同步块,这时候就不适合使用自旋锁了,因为自旋锁在获取锁前一直都是占用 cpu 做无用功,占着茅坑不拉屎,同时有大量线程在竞争一个锁,会导致获取锁的时间很长,线程自旋的消耗大于线程阻塞挂起操作的消耗,其它需要 cpu 的线程又不能获取到 cpu,造成 cpu 的浪费。所以这种情况下我们要关闭自旋锁。
悲观锁
悲观锁是一种悲观思想,它总认为最坏的情况可能会出现,它认为数据很可能会被其他人所修改,所以悲观锁在持有数据的时候总会把资源 或者 数据 锁住,这样其他线程想要请求这个资源的时候就会阻塞,直到等到悲观锁把资源释放为止。
乐观锁
乐观锁的思想与悲观锁的思想相反,它总认为资源和数据不会被别人所修改,所以读取不会上锁,但是乐观锁在进行写入操作的时候会判断当前数据是否被修改过
CAS算法
即 Compare And Swap(比较与交换),是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。CAS算法涉及到三个操作数:
- 需要读写的内存值 V
- 进行比较的值 A
- 拟写入的新的值 N
当且仅当 V 的值等于 A 时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个自旋操作,即不断的重试。
ABA 问题
ABA 问题说的是,如果一个变量第一次读取的值是 A,准备好需要对 A 进行写操作的时候,发现值还是 A,那么这种情况下,能认为 A 的值没有被改变过吗?可以是由 A -> B -> A 的这种情况,但是 AtomicInteger 却不会这么认为,它只相信它看到的,它看到的是什么就是什么。
JDK 1.5 以后的 AtomicStampedReference 类就提供了此种能力,其中的 compareAndSet 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
也可以采用 CAS 的一个变种 DCAS 来解决这个问题。DCAS,是对于每一个 V 增加一个引用的表示修改次数的标记符。对于每个 V,如果引用修改了一次,这个计数器就加1。然后在这个变量需要 update 的时候,就同时检查变量的值和计数器的值。
悲观锁、乐观锁的使用场景
什么时候使用乐观锁
资源提交冲突,其他使用方需要重新读取资源,会增加读的次数,但是可以面对高并发场景,前提是如果出现提交失败,用户是可以接受的。因此一般乐观锁只用在高并发、多读少写的场景。
其中:GIT,SVN,CVS等代码版本控制管理器,就是一个乐观锁使用很好的场景,例如:A、B程序员,同时从SVN服务器上下载了code.html文件,当A完成提交后,此时B再提交,那么会报版本冲突,此时需要B进行版本处理合并后,再提交到服务器。这其实就是乐观锁的实现全过程。如果此时使用的是悲观锁,那么意味着所有程序员都必须一个一个等待操作提交完,才能访问文件,这是难以接受的。
什么时候使用悲观锁
一旦通过悲观锁锁定一个资源,那么其他需要操作该资源的使用方,只能等待直到锁被释放,好处在于可以减少并发,但是当并发量非常大的时候,由于锁消耗资源,并且可能锁定时间过长,容易导致系统性能下降,资源消耗严重。因此一般我们可以在并发量不是很大,并且出现并发情况导致的异常用户和系统都很难以接受的情况下,会选择悲观锁进行。
Q. volatile关键字(鹅厂)
volatile提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,都会直接从变量地址中读取数据。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。
于是,当两个线程都要用到某一个变量且该变量的值会被改变时,应该用volatile声明。
Q. 用户态和内核态(C++)
用户态和内核态的概念
当一个进程在执行用户自己的代码时处于用户运行态(用户态),此时特权级最低,为3级,是普通的用户进程运行的特权级,大部分用户直接面对的程序都是运行在用户态。Ring3状态不能访问Ring0的地址空间,包括代码和数据;当一个进程因为系统调用陷入内核代码中执行时处于内核运行态(内核态),此时特权级最高,为0级。执行的内核代码会使用当前进程的内核栈,每个进程都有自己的内核栈。
用户运行一个程序,该程序创建的进程开始时运行自己的代码,处于用户态。如果要执行文件操作、网络数据发送等操作必须通过write、send等系统调用,这些系统调用会调用内核的代码。进程会切换到Ring0,然后进入3G-4G中的内核地址空间去执行内核代码来完成相应的操作。内核态的进程执行完后又会切换到Ring3,回到用户态。这样,用户态的程序就不能随意操作内核地址空间,具有一定的安全保护作用。这说的保护模式是指通过内存页表操作等机制,保证进程间的地址空间不会互相冲突,一个进程的操作不会修改另一个进程地址空间中的数据。
用户态和内核态的切换
当在系统中执行一个程序时,大部分时间是运行在用户态下的,在其需要操作系统帮助完成一些用户态自己没有特权和能力完成的操作时就会切换到内核态。
用户态切换到内核态的3种方式
(1)系统调用
这是用户态进程主动要求切换到内核态的一种方式。用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作。例如fork()就是执行了一个创建新进程的系统调用。系统调用的机制和新是使用了操作系统为用户特别开放的一个中断来实现,如Linux的int 80h中断。
(2)异常
当cpu在执行运行在用户态下的程序时,发生了一些没有预知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关进程中,也就是切换到了内核态,如缺页异常。
(3)外围设备的中断
当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令而转到与中断信号对应的处理程序去执行,如果前面执行的指令时用户态下的程序,那么转换的过程自然就会是 由用户态到内核态的切换。如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后边的操作等。
这三种方式是系统在运行时由用户态切换到内核态的最主要方式,其中系统调用可以认为是用户进程主动发起的,异常和外围设备中断则是被动的。从触发方式上看,切换方式都不一样,但从最终实际完成由用户态到内核态的切换操作来看,步骤有事一样的,都相当于执行了一个中断响应的过程。系统调用实际上最终是中断机制实现的,而异常和中断的处理机制基本一致。

















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









