







【论文】Yu, Jun, Jing Li, Zhou Yu, and Qingming Huang. Multimodal transformer with multi-view visual representation for image captioning. (pdf)
Why is MT model
以往流行的方式都是使用 encoder-decoder 结构,在 encoder使用 CNN 提取局部视觉特征,decoder 使用 RNN 根据视觉特征生成 caption,这些方式有如下的一些问题:
- 它们的注意力机制都只注重对 co-attention 进行建模,即只关注模态内部的交互作用(e.g. object-to-word),而忽略了对模态间的交互作用(e.g. object-to-object,word-to-word)
- 并不能充分理解视觉物体之间的复杂关系
- 基于区域的视觉特征并不能囊括图片中的所有物体,从而导致视觉特征不够有效,无生成准确的 caption
在篇文章中,作者首次提出将 Transformer 引入到 image caption 建立了 MT model。Transformer 的好处在于抛弃了传统的 CNN 和 RNN,完全依赖于注意力机制来获取输入和输出自己爱你的全局关系。MT model 的主要表现如下:
-
MT model 在一个统一的 attention block 中同时捕捉模态内和模态间的交互作用
-
堆叠 attention blocks 加深模型可以使得 MT model 进行复杂的多模态推理
-
为了进一步提高 image captioning 的表现,MT model 还引入了 multi-view visual feature,提供更多样、更具区别性的视觉特征
Multimodel Transformer
MT model 的结构如下所示,包含一个 image encoder 和 caption decoder。首先,通过 Faster RCNN 提取出来区域视觉特征,然后将其输入到 encoder 中获得 attended visual features。decoder 根据这个视觉特征和前一个单词来预测一下个单词。细节如下图描述
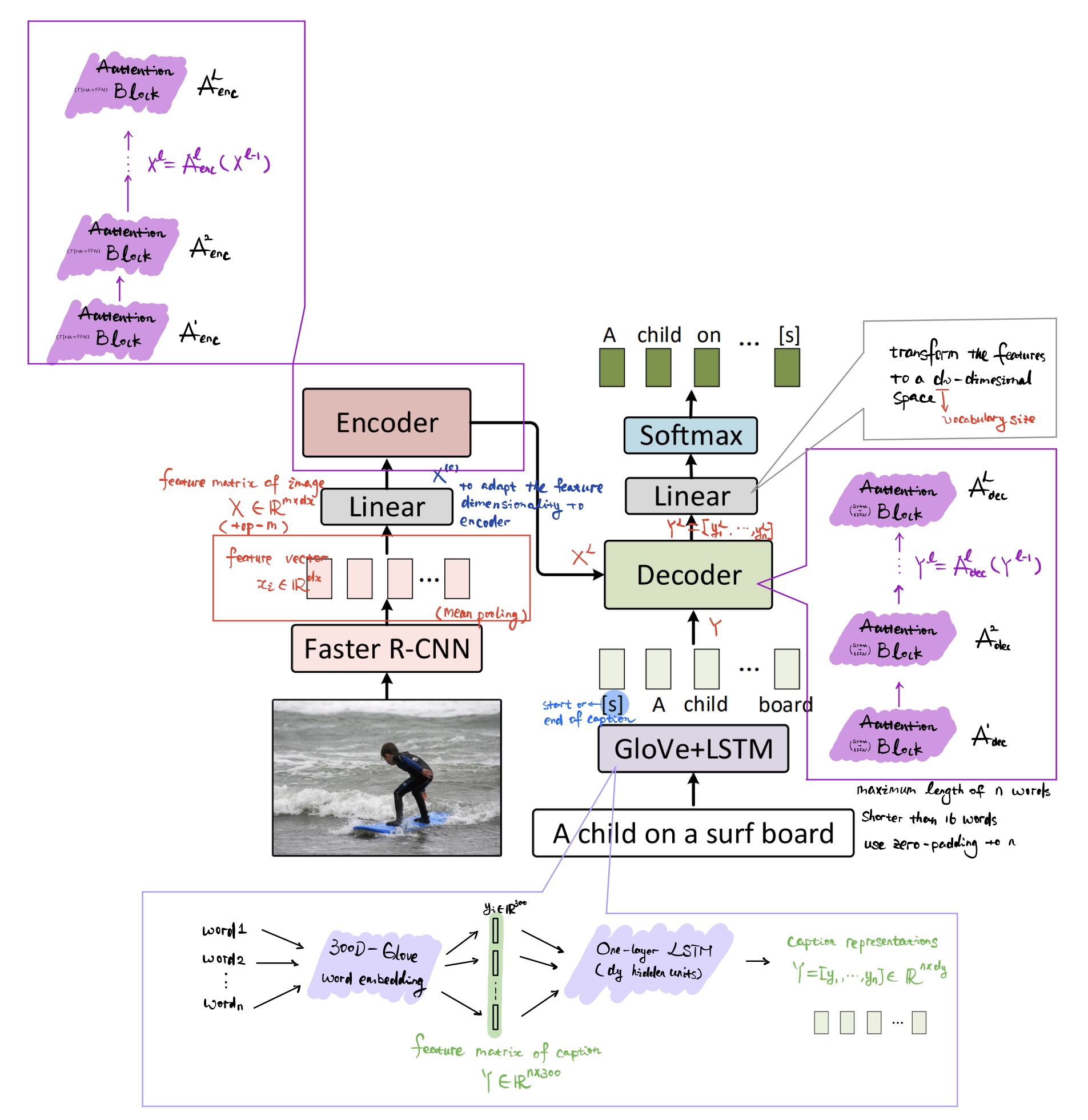
测试时,生成第 t t t 个单词的 input caption feature 是 Y ≤ t = [ y 1 , y 2 , ⋯ , y t − 1 , 0 , ⋯ , 0 ] 0 ∈ R d y Y_{\leq t}=[y_1, y_2, \cdots,y_{t-1},\mathbf 0,\cdots,\mathbf 0]\ \mathbf 0\in\mathbb R^{d_y} Y≤t=[y1,y2,⋯,yt−1,0,⋯,0] 0∈Rdy,该 caption feature 和 image feature 一同送入 decoder 产生预测单词。然后,下一次预测的第 t + 1 t+1 t+1 个单词的时候,input caption feature 就是 Y ≤ t + 1 Y_{\leq t+1} Y≤t+1
Image Encoder with Multi-View Visual Representation
在这一节,引入 multi-view image representation 对上述的 image encoder 作出修改。不同于以往,作者采用基于区域的 local multi-view features——将每个目标检测器视为一个角度,每个检测器通过不同 backbone 的 Faster RCNN 得到。考虑到不同检测器得到的特征并不对齐,作者提出了两种 multi-view image encoder,Aligned Multi-View(AMV)image encoder 和 Unaligned Multi-View(UMV)image encoder
Aligned Multi-View image encoder[^1]
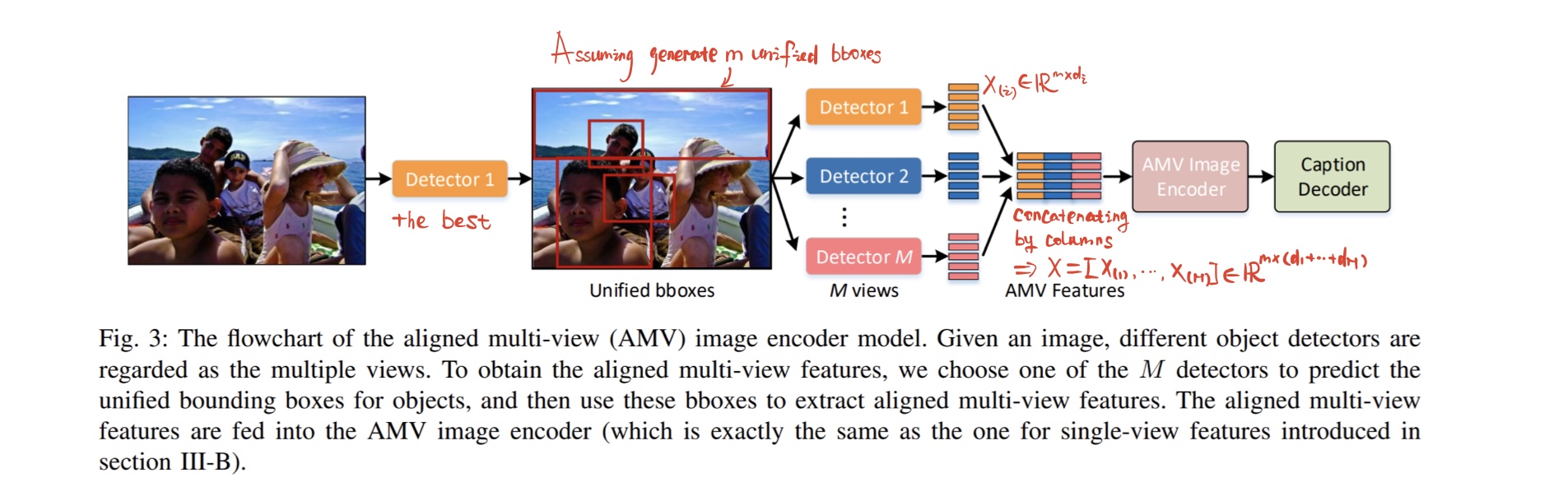
作者认为统一的边框不是很好,会降低 multi-view features 的多样性,限制 encoded image features 的表征能力。同时,AMV 模型隐式的限制了目标检测器只能是 Faster RCNN 模型(Faster RCNN 要么使用需要计算好的 proposals 作为输入,要么使用自己的 RPN 生成 proposals),这样对于像是 RetinaNet 或者 YOLO 这种 one-stage 的模型就没有办法作为 AMV 的目标检测器
Unaligned Multi-View image encoder
为了解决 AMV 的问题,作者又提出了 UMA 直接整合不同目标检测器的 unaligned multi-view features
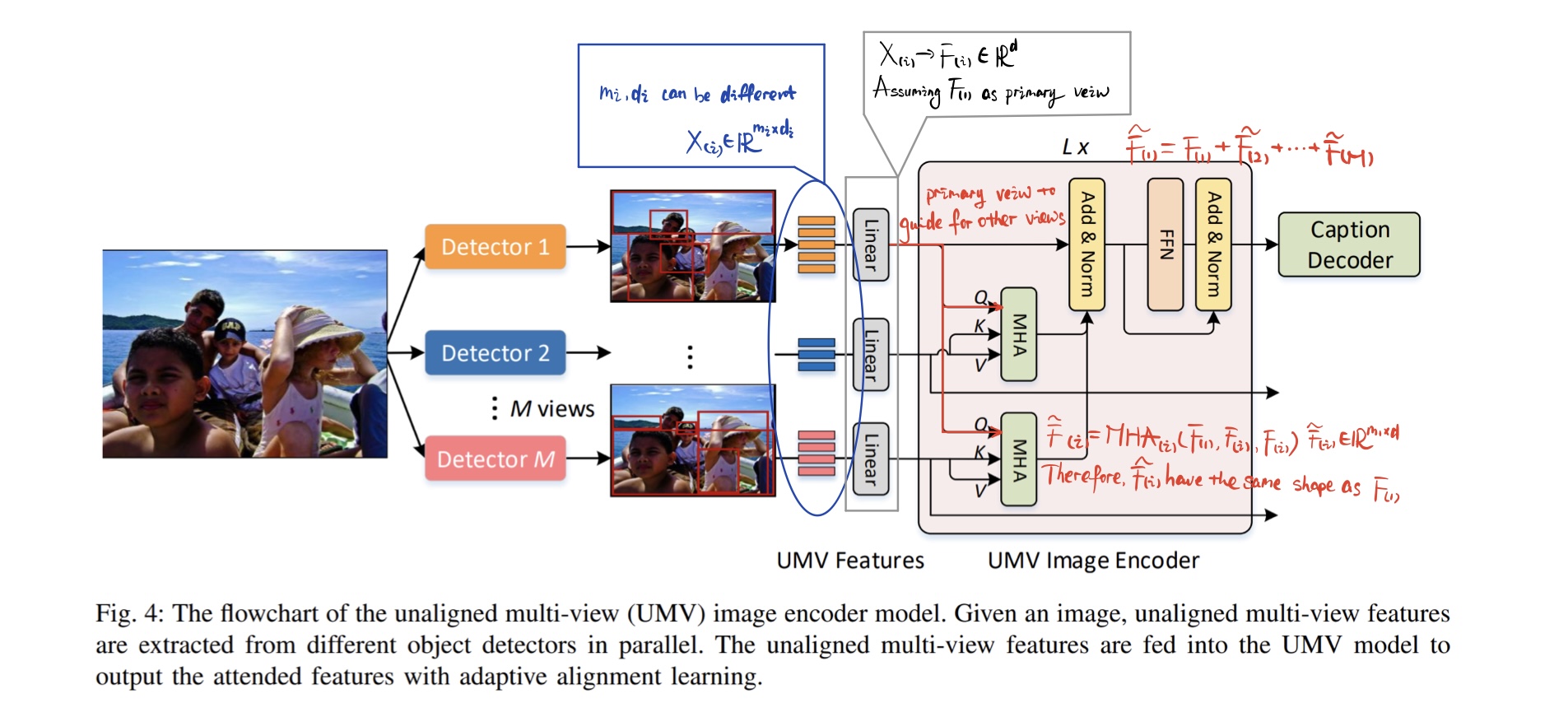
值得注意的是,UMV 可以通过堆叠学习到更多不同视角的交互作用
Experiments
我们下面来看一下论文里几张实验的图片
Attentions of MTsv(single-view MT model) Encoder
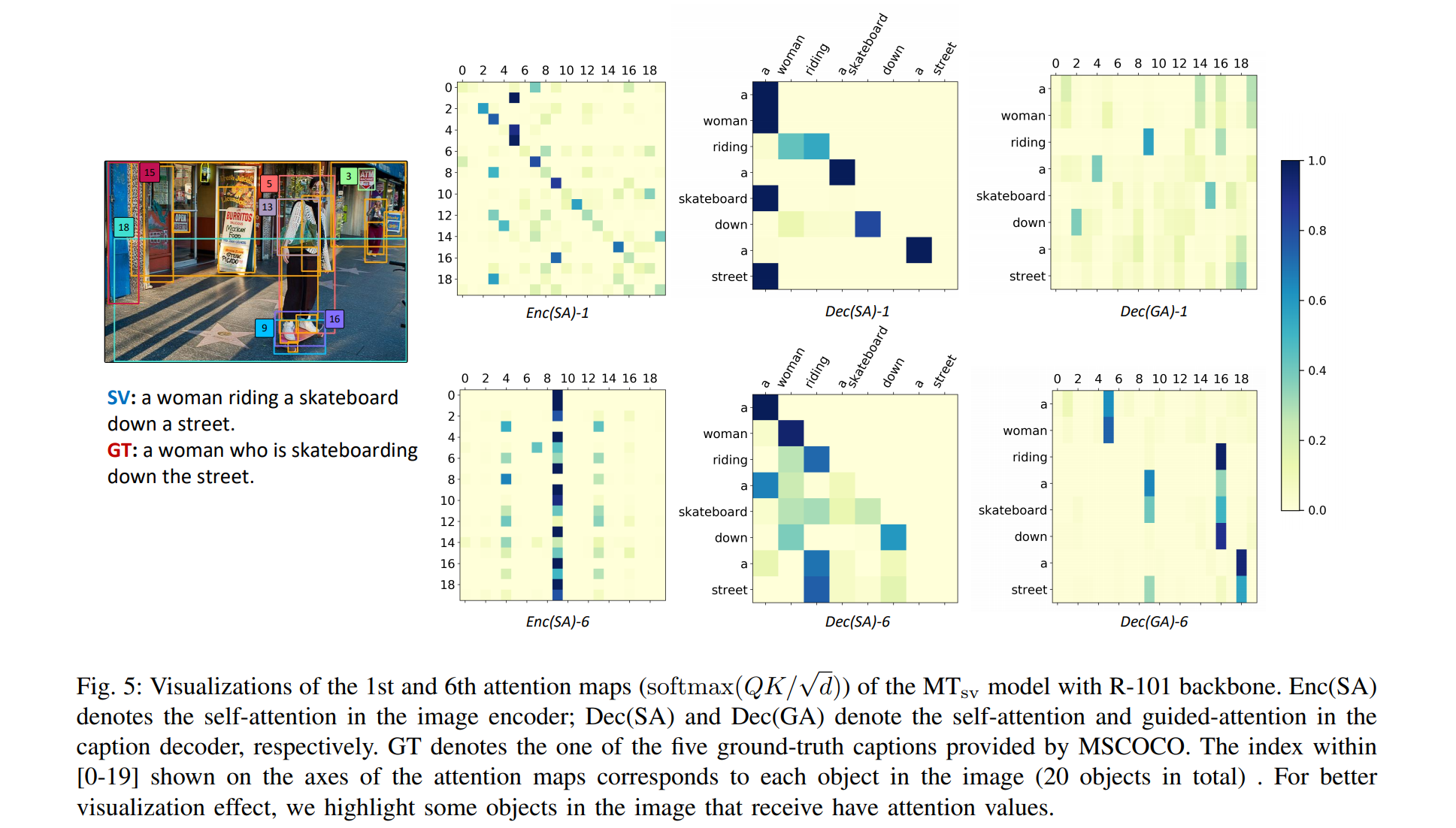
观察上图我们可以发现:
- 在 Enc(SA)-1 中,最大的注意力值几乎出现在对角线上,说明在 encoder 的第一层中没有学到图像中物体两两的交互作用
- 在 Enc(Sa)-6 中,最大的注意力值几乎成垂直线(在第 4、9、13 列),对应图中的关键对象(如女孩、滑板)
这表明,所有 attended features 都倾向于与关键对象产生交互作用
Attentions of MTsv Decoder
如上图所示, caption decoder 第一层和第六层的注意力图都反映了 paried words 的相似性。和 Enc(SA)-1 相似,Dec(SA)-1 并没有习得两两单词之间的交互作用。但是在 Dec(Sa)-6 中,我们发现,许多单词开始有了联系
guided-attention(GA)反应了多模态之间的相互联系(word-object)。在 Dec(GA)-1 中,一些词和物并不能很好的配对。但是在 Dec(GA)-6 中,关键对象和它们匹配的词之间的 word-object relationship 相当明显
Attentions of MTumv Encoder
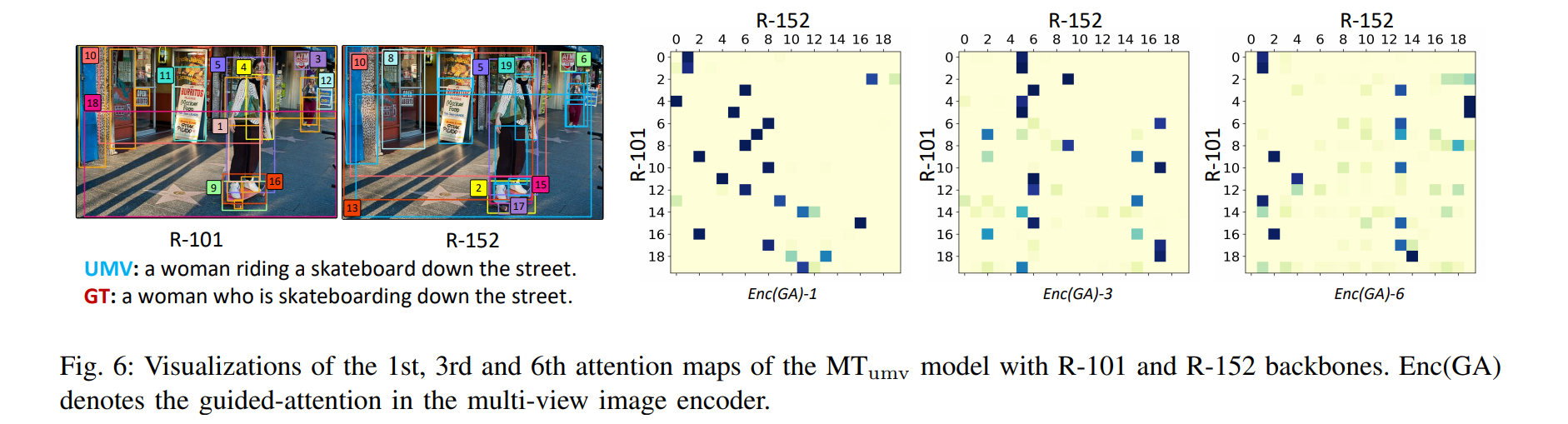
观察上图我们可以发现:
- 在 Enc(GA)-1 中,来自不同视点的 unaligned objects 自动对齐了,如在 R-101 和 R-152 中的第五个对象,R-101 中的第三个对象和 R-152 中的第 6 个对象
- 在 Enc(GA)-3 中,开始会涉及到上下文环境,如 R-152 中的第五个对象和 R-101 中的第一个、第四个对象,他们都对应女孩的身体
- 在 Enc(GA)-6 中,涉及到特定对象的一些关系,以及背景环境的关系会被模型注意到,如 R-152 中的第十三个对象和 R-101 中的第十个对象,它们都属于接街道背景
这表明, UMA image encoder 能够学会对齐来自不同目标检测器的对象,同时能够通过多视点特征探索物体和物体之间的更为复杂的关系,能够提供对图像内容的 fine-grained understanding
同时,作者也在下图展示了一些 image captioning 的预测结果

通过前两行可以明显发现,MTumv 的预测优于 MTsv 的预测。第三行展示了两个 MTsv 优于 MTumv 的例子。最后一行展示了两个模型都预测错误的例子。作者给出的结论是:
- 尽管 MTumv 预测正确的数量多于 MTsv,但是两者之间的性能差距没有本质上的区别,各有各的优势。甚至把两者融合在一起能够形成一个更具多样性的模型
- 不正确的预测往往会出现在图像上的一些小物体上
[^ 1]: AMV 里面的 d i d_i di 应该是可以不同的,即 d 1 ≠ d 2 ≠ ⋯ d_1\neq d2\neq\cdots d1=d2=⋯ 这种

















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









