




 该论文提出了一种多模态Transformer架构,用于视频检索任务。通过融合视频的视觉、声音、语音特征,专家信息和时间编码,学习视频的表示。同时,利用BERT处理字幕获取caption表示,通过计算caption与video表示的相似度进行检索。实验表明,这种方法在性能上表现出色。关键创新点包括:1)设计了视频编码器处理多模态特征;2)对比研究了不同的语言embedding,发现BERT效果最佳;3)引入时间embedding提供时间线索。
该论文提出了一种多模态Transformer架构,用于视频检索任务。通过融合视频的视觉、声音、语音特征,专家信息和时间编码,学习视频的表示。同时,利用BERT处理字幕获取caption表示,通过计算caption与video表示的相似度进行检索。实验表明,这种方法在性能上表现出色。关键创新点包括:1)设计了视频编码器处理多模态特征;2)对比研究了不同的语言embedding,发现BERT效果最佳;3)引入时间embedding提供时间线索。
简介
使用多模态transformer融合了来自视频的 多种模态(视觉、声音、语音)特征、专家序号、时间编码,得到各个模态的video表征,再计算由BERT、Gated embedding modules输出的Caption words的表征,最后计算caption和video表征的相似度
论文的任务/贡献
1.提出用于检索的视频编码器体系结构:多模态transformer处理在不同时间提取的多模态特征
2.研究了不同的语言embedding体系结构,BERT最好。
3.效果好。
所提方法
通过学习一个函数计算文本和视频的相似度,根据相似性对数据集中所有视频进行排序
网络结构
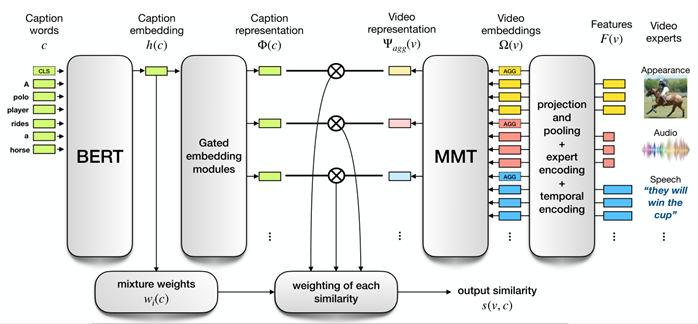
MMT:多模态Transformer
Ω:结合了语义特征F,专家信息E,时间线索T的向量,最终输入到MMT
视频表征
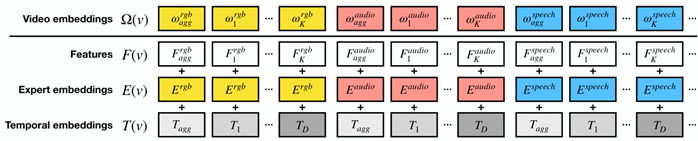
特征F:利用专家之间的跨模态和长时期时间关系学习一种联合表示。使用了N个预训练过的专家{Fn}n=1N\{F^n\}^N_{n=1}{Fn}n=1N。每个专家是一个为特定任务而训练的模型,随后用来从视频中提取特征。每个专家为一个视频v提取出来K个特征的序列Fn(v)=[F1n,...,FKn]F^n(v)=[F^n_1,...,F^n_K]Fn(v)=[F1n,...,FKn]。专家提取的特征编码了视频的语义,随后为每个专家使用一个线性层将特征映射到同一维度dmodeld_{model}dmodel。
由于每个transformer为每个输入产生一个embedding,则每个专家有多个embedding,为了让每个专家仅有一个embedding,定义了一个特征集合,将专家的信息收集并置于上下文中。将单个专家预测的所有特征使用最大池化进行聚合Faggn=maxpool({Fkn}k=1K)F^n_{agg}=maxpool(\{F^n_k\}^K_{k=1})Faggn=maxpool({Fkn}k=1K)。输入视频编码器的特征格式为F(v)=[Fagg1,F11,...,FK1,...,FaggN,F1N,...,FKN]F(v)=[F^1_{agg},F^1_1,...,F^1_K,...,F^N_{agg},F^N_1,...,F^N_K]F(v)=[Fagg1,F11,...,FK1,...,FaggN,F1N,...,FKN](F是用什么得到的论文里没提)
专家embedding E:为了使MMT能够确定该关注哪个专家,学习了N个embedding。送入视频编码器的专家embedding序列的格式E(v)=[E1,E1,...,E1,...,EN,EN,...EN]E(v)=[E^1,E^1,...,E^1,...,E^N,E^N,...E^N]E(v)=[E1,E1,...,E1,...,EN,EN,...EN]
时间embedding T:提供了视频中特征被提取到MMT的时间信息。视频持续时间最长为D=tmax秒,且向上取整,学习了D个embedding{T1,...,TD}\{T_1,...,T_D\}{T1,...,TD},每个TxT_xTx都含有1秒的时间信息(t=7.4时,D=8)。还额外学习了两个时间embedding,其编码了聚合后的特征Tagg和未知的时间信息特征Tunk(对于时间信息未知的专家),组成T(v)=[Tagg,T1,...,TD,...,Tagg,T1,...,TD]T(v)=[T_{agg},T_1,...,T_D,...,T_{agg},T_1,...,T_D]T(v)=[Tagg,T1,...,TD,...,Tagg,T1,...,TD](Tagg Tunk是学来的?T怎样与F和E对齐?)
最终,Ω(v)=F(v)+E(v)+T(v)=[ωagg1,ω11,...,ωK1,...,ωagg1,ω1N,...,ωKN]\Omega(v)=F(v)+E(v)+T(v)=[\omega^1_{agg},\omega^1_1,...,\omega^1_K,...,\omega^1_{agg},\omega^N_1,...,\omega^N_K]Ω(v)=F(v)+E(v)+T(v)=[ωagg1,ω11,...,ωK1,...,ωagg1,ω1N,...,ωKN],经过MMT后输出Ψagg(v)=MMT(Ω(v))=[ψagg1,...,ψaggN]\Psi_{agg}(v)=MMT(\Omega(v))=[\psi^1_{agg},...,\psi^N_{agg}]Ψagg(v)=MMT(Ω(v))=[ψagg1,...,ψaggN]
字幕表征
先使用训练过的BERT,将输出[CLS]作为caption的embedding h©,然后使用函数g投影到N个不同空间即Φ=g◦hΦ=g◦hΦ=g◦h。为了使字幕表征的大小与视频匹配,为函数g学习了与视频专家一样多的门控embedding模块。字幕表征由N个embedding组成,表示为Φ(c)={ϕi}i=1NΦ(c)=\{\phi^i\}^N_{i=1}Φ(c)={ϕi}i=1N
相似性估计
将每个专家i的视频-字幕相似性⟨ϕi,ψaggi⟩\lang\phi^i,\psi^i_{agg}\rang⟨ϕi,ψaggi⟩的加权(由于字幕可能不能统一描述视频中内在模态,有些关注于视觉模态,有些关注于声音模态)之和s(v,c)=∑i=1Nwi(c)⟨ϕi,ψaggi⟩\displaystyle s(v,c)=\sum^N_{i=1}w_i(c)\lang\phi^i,\psi^i_{agg}\rangs(v,c)=i=1∑Nwi(c)⟨ϕi,ψaggi⟩作为视频-字幕相似性,记为s。wi(c)w_i(c)wi(c)代表第i个专家的权重,权重是将字幕表征通过一个线性层后使用softmax

















 7856
7856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









