







0x01dig_dig_dig
__int64 __fastcall main(int a1, char **a2, char **a3)
{
size_t v3; // rax
char *dest; // ST18_8
size_t v5; // rax
__int64 v6; // rax
__int64 v7; // rax
char *v8; // ST18_8
if ( a1 != 2 )
{
puts("./dec_dec_dec flag_string_is_here ");
exit(0);
}
v3 = strlen(a2[1]);
dest = (char *)malloc(v3 + 1);
v5 = strlen(a2[1]);
strncpy(dest, a2[1], v5);
v6 = sub_860(dest);
v7 = sub_F59(v6);
v8 = (char *)sub_BE7(v7);
if ( !strcmp(v8, s2) )
puts("correct :)");
else
puts("incorrect :(");
return 0LL;
}
从这里可以看出,输入字符串进行了3次加密,没有长度信息。

第一段看编码表可以猜测是base64
可以验证一下
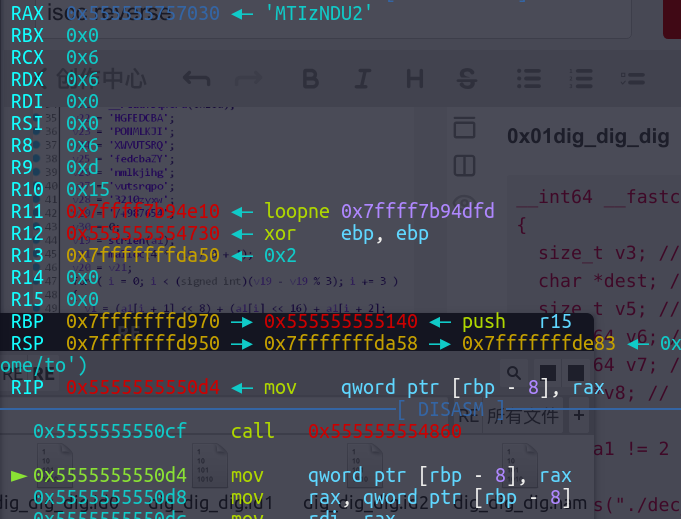
验证MTIzNDU2就是123456base64加密后的结果
第二部分

这个是rot5,这里分享一个爆破脚本
v10='Hv1g_1g_M0if_Tzou_v4v4v'
v11=[]
for i in range(len(v10)):
v11.append(v10[i])
f=''
for i in range(len(v10)):
for j in range(0,128):
if j > 90 or j< 65 :
if j > 122 or j < 97:
continue
v9 = (j - 83) % 26 + 97
else:
v9 = (j - 51) % 26 + 65
if v10[i]==chr(v9):
print v10[i],chr(j)
v11[i]=chr(j)
for i in range(len(v10)):
f+=v11[i]
print f
print v10

第三段是uuencode加密更好的
可以从这个加密结果猜测
.rodata:00000000000011C8 a1de440s9w92tY0 db '@1DE!440S9W9,2T%Y07=%<W!Z.3!:1T%S2S-),7-$/3T ',0
总结:需要一个总结关于常用的编码方式
1.编码代码的特点
2.编码明文和密文范围的特点()
3.编码之后明文密文长度的变化特点。
可能会有几种加密方法一起。或者编码之后再进行简单异或,小写转大写等。这些可以动态调试来确定。
0x02pyc.pyc
pyc文件是python字节码文件,可以在线反编译https://tool.lu/pyc/
进行了简单异或
import base64
c = 'eYNzc2tjWV1gXFWPYGlTbQ=='
m = c.decode("base64")
s = ''
for i in m:
x = ord(i) - 16
x = x ^ 32
s=s+chr(x)
print s
0x03 main.exe
用ida打开,有经验的话可以看出来这是一个64位的elf文件,然而知道这些并没有什么用。
没办法,谷歌了一下输出的字符串,找出来了别人解出来的答案。
https://www.megabeets.net/page/4/
0x04 Re2.exe
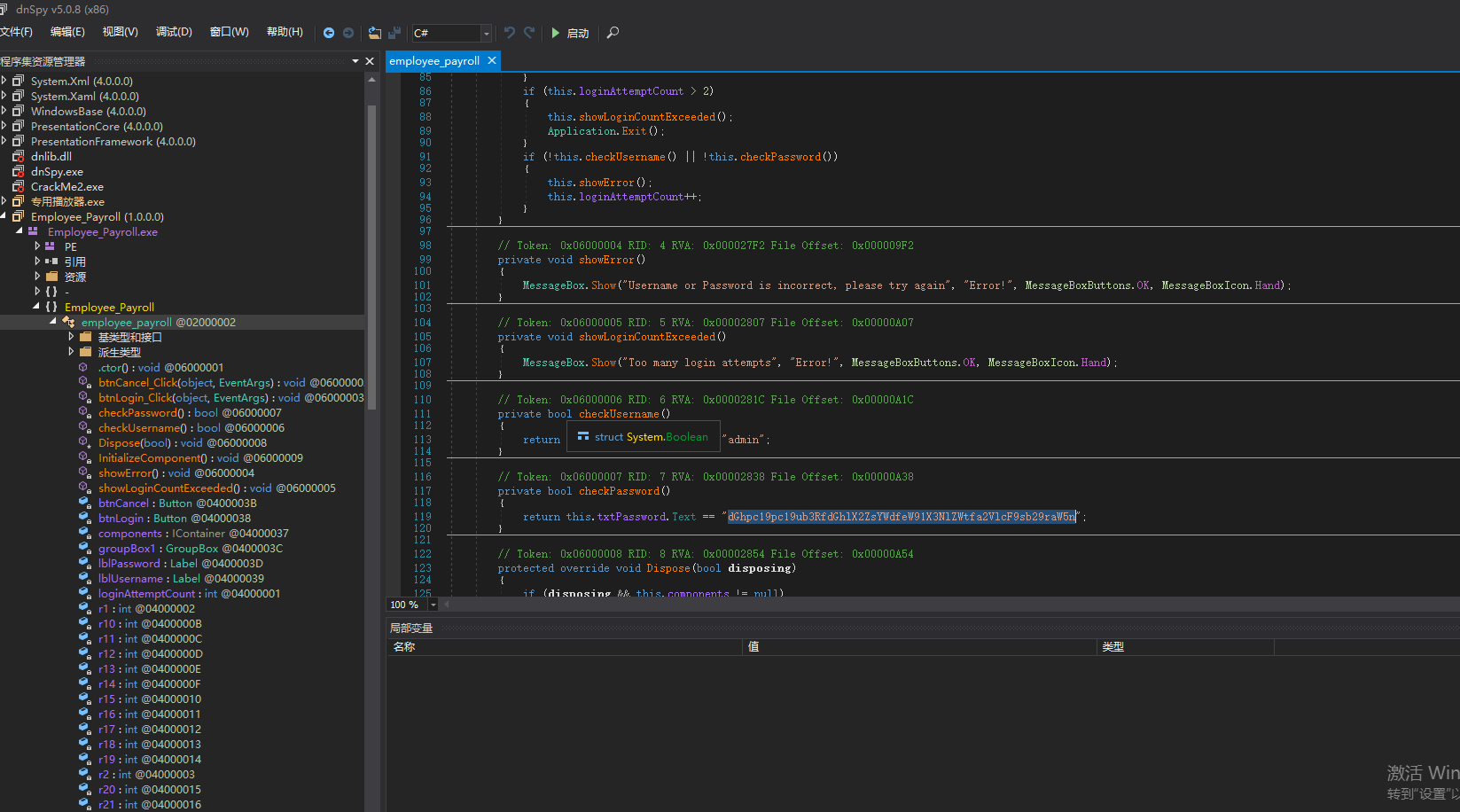
输入用户名和密码即可
0x05reverse
搜索输入函数可以找到
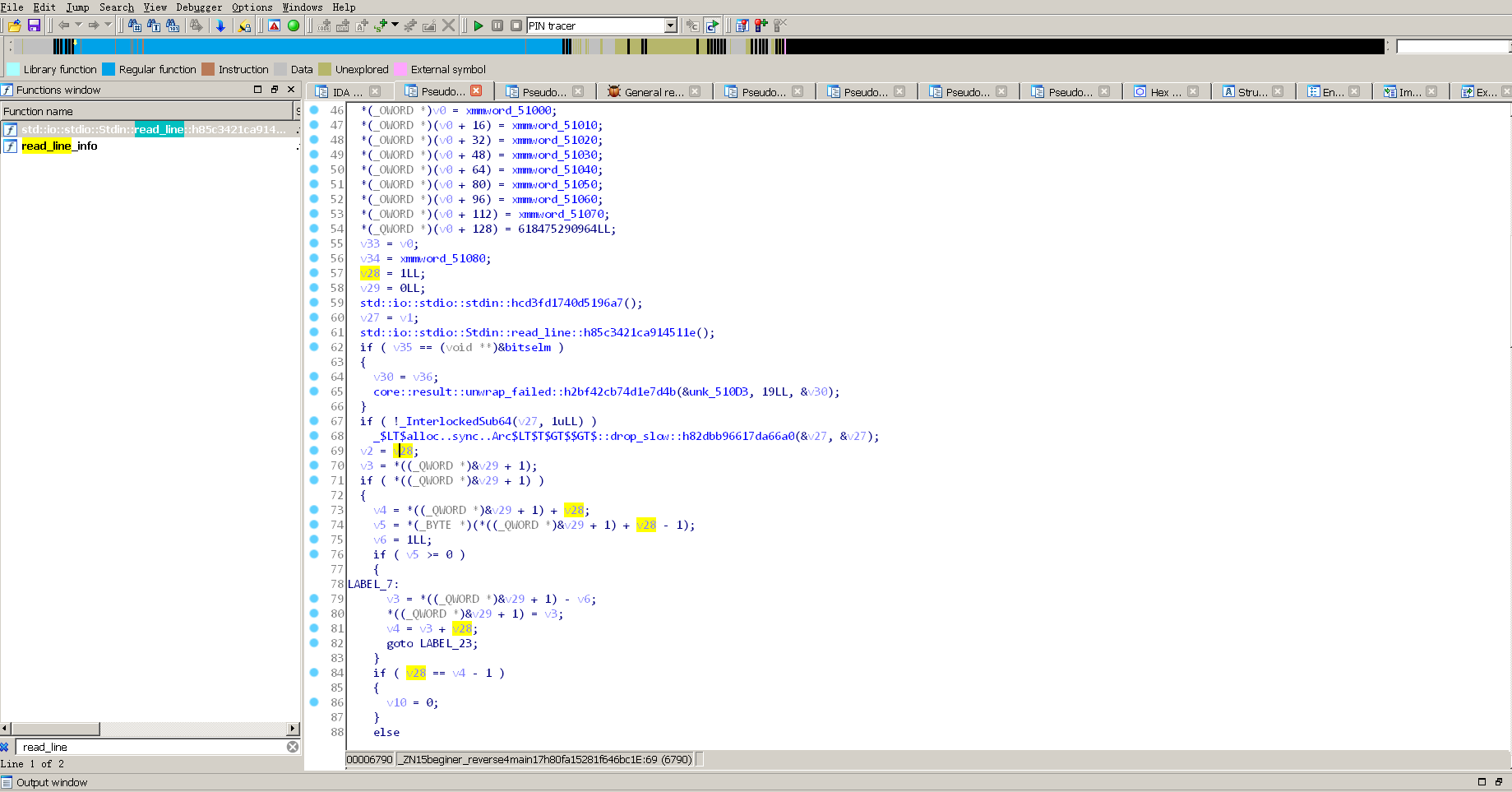
输入的值被放入了v28,追踪v28可以确定
在这里验证

下断点扒数据
pwndbg> x /50xw 0x7ffff6c2a000
0x7ffff6c2a000: 0x00000154 0x00000180 0x000001fc 0x000001e4
0x7ffff6c2a010: 0x000001f8 0x00000154 0x00000190 0x000001bc
0x7ffff6c2a020: 0x000001bc 0x000001b8 0x00000154 0x000001f8
0x7ffff6c2a030: 0x00000194 0x00000154 0x000001b4 0x000001bc
0x7ffff6c2a040: 0x000001f8 0x00000154 0x000001f4 0x00000188
0x7ffff6c2a050: 0x000001ac 0x000001f8 0x00000154 0x0000018c
0x7ffff6c2a060: 0x000001e4 0x00000154 0x00000190 0x000001bc
0x7ffff6c2a070: 0x000001bc 0x000001b8 0x000001bc 0x000001b8
0x7ffff6c2a080: 0x00000154 0x00000090 0x00000000 0x00000000
0x7ffff6c2a090: 0x00000000 0x00000000 0x00000000 0x00000000
0x7ffff6c2a0a0: 0x00000000 0x00000000 0x00000000 0x00000000
0x7ffff6c2a0b0: 0x00000000 0x00000000 0x00000000 0x00000000
0x7ffff6c2a0c0: 0x00000000 0x00000000
key=[0x00000154,0x00000180,0x000001fc,0x000001e4,0x000001f8,0x00000154,0x00000190,0x000001bc, 0x000001bc, 0x000001b8, 0x00000154, 0x000001f8,
0x00000194, 0x00000154, 0x000001b4, 0x000001bc,
0x000001f8, 0x00000154, 0x000001f4, 0x00000188,
0x000001ac, 0x000001f8, 0x00000154, 0x0000018c,
0x000001e4, 0x00000154, 0x00000190, 0x000001bc,
0x000001bc, 0x000001b8, 0x000001bc, 0x000001b8,
0x00000154, 0x00000090]
flag=""
for i in key:
flag+= chr((i>>2)^0xA)
print flag
0x06 apk
用jeb查看check逻辑。可以得到长度和范围
提取so文件分析check逻辑。
这个题目代码静态调试不好懂(ida反编译过来很乱,需要看汇编)但是具体算法挺简单。这两个特点满足符号执行。
用angr解题
# libnative-lib.so
import angr
import claripy
import binascii
base = 0x400000
p = angr.Project("./libnative-lib.so")
key = claripy.BVS("key", 16 * 8)
state = p.factory.blank_state(addr=0xECC0+base)#设置入口地址
# 0xF19C + base :first_out_call
# 0xF198 check_first_wrapper
# 0xE3C0 check_first
# 0xECC0 check_again
# for i in range(0, 8):
# state.add_constraints(key.get_byte(i) == claripy.BVV(i + ord('1'), 4))
# state.se.add(key.get_byte(8) == int(binascii.hexlify(b"12345678"), 16))
state.se.add(key.get_byte(0) == int(binascii.hexlify(b"1"), 16))
state.se.add(key.get_byte(1) == int(binascii.hexlify(b"2"), 16))
state.se.add(key.get_byte(2) == int(binascii.hexlify(b"3"), 16))
state.se.add(key.get_byte(3) == int(binascii.hexlify(b"4"), 16))
state.se.add(key.get_byte(4) == int(binascii.hexlify(b"5"), 16))
state.se.add(key.get_byte(5) == int(binascii.hexlify(b"6"), 16))
state.se.add(key.get_byte(6) == int(binascii.hexlify(b"7"), 16))
state.se.add(key.get_byte(7) == int(binascii.hexlify(b"8"), 16))#设置前8位
sm = p.factory.simulation_manager(state)
sm.explore(find=[ # 0xE607 + base, # first_check
# 0xE487 + base, # char+1
# 0xE4E4 + base, # cahr+1
0xF0F5 + base, #运行到这里是checkAgain正确结果
#0xF223 + base # out of check_second , in check_main
],
avoid=[0xE5E2 + base, # check_first
0xF00F + base, 0xF037 + base, 0xF0B7 + base, 0xF077 + base, 0xEFB4 + base, 0xEF9C + base,
0xEF81 + base,
0xF22C+base # behind calculation
]) #这些是不正确的结果
found = sm.found[0]
for i in range(8, 16):
cond_0 = key.get_byte(i) >= ord('1')
cond_1 = key.get_byte(i) <= ord('8')
found.add_constraints(found.solver.And(cond_0, cond_1))
for j in range(i + 1, 16):
if i == j or j >= 16:
break
# found.add_constraints(found.solver.And(key.get_byte(i) != key.get_byte(j), cond_1))
# print("NOW ADD index(%d) !=index(%d)", i, j)
cond2 = key.get_byte(i) != key.get_byte(j)
found.add_constraints(found.solver.And(cond_0, cond2))
# if i + 1 <= 17:
# cond_2 = key.get_byte(i) != key.get_byte(i + 1)
# found.add_constraints(found.solver.And(cond_0, cond_2))
tmp_addr = 0x38460 + base
state.regs.rdi = tmp_addr
flag_addr = state.regs.rdi
# found.add_constraints(found.memory.load(flag_addr, 5) == int(binascii.hexlify(b"12345678"), 16))
found.memory.store(flag_addr, key)
if found.solver.satisfiable():
print("FIND IT")
else:
print("CANNOT FIND")
exit(0)
flag_str = found.solver.eval(key, cast_to=bytes)
print(bytes.decode(flag_str).strip('\x00'))















 952
952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









