









wordnet
参考WordNet Python API (整理总结)
wordnet简介
一个synset由lemma.POS.number组成,代表一个语义。
注意synset和synsets 的区别,synsets是list,synset是一个object 。
相似度计算
英文引用源文档,中文机翻

- path_similarity
synset1.path_similarity(synset2): Return a score denoting how similar two word senses are, based on the shortest path that connects the senses in the is-a (hypernym/hypnoym) taxonomy. The score is in the range 0 to 1. By default, there is now a fake root node added to verbs so for cases where previously a path could not be found—and None was returned—it should return a value. The old behavior can be achieved by setting simulate_root to be False. A score of 1 represents identity i.e. comparing a sense with itself will return 1.
基于连接is-a(双音节/催音符)分类法中感官的最短路径,返回表示两个单词的感官相似程度的分数。 分数在0到1的范围内。默认情况下,现在在动词上添加了一个假的根节点,因此对于以前找不到路径的情况-并且未返回None-它应该返回一个值。 通过将simulator_root设置为False可以实现旧的行为。 分数1表示身份,即将感官与自身进行比较将返回1。
####path_similarity = 1/(dis1+dis2+1)#### - 其中path_similarity是两个词集的相似度; - dis1与dis2分别表示两个词集与其最低共同上位词集的深度之差; - 两个1是为了归一化而使用的参数 >比如对于right_whale与minke_whale: >|
解释见语义相似度
- lch_similarity
synset1.lch_similarity(synset2): Leacock-Chodorow Similarity: Return a score denoting how similar two word senses are, based on the shortest path that connects the senses (as above) and the maximum depth of the taxonomy in which the senses occur. The relationship is given as -log(p/2d) where p is the shortest path length and d the taxonomy depth.
Leacock-Chodorow相似度:根据连接感觉的最短路径(如上所述)和出现感觉的分类法的最大深度,返回一个分数,表示两个单词的感觉有多相似。 关系以-log(p / 2d)形式给出,其中p是最短路径长度,d是分类深度。
原理
- wup_similarity
synset1.wup_similarity(synset2): Wu-Palmer Similarity: Return a score denoting how similar two word senses are, based on the depth of the two senses in the taxonomy and that of their Least Common Subsumer (most specific ancestor node). Note that at this time the scores given do not always agree with those given by Pedersen’s Perl implementation of Wordnet Similarity.
The LCS does not necessarily feature in the shortest path connecting the two senses, as it is by definition the common ancestor deepest in the taxonomy, not closest to the two senses. Typically, however, it will so feature. Where multiple candidates for the LCS exist, that whose shortest path to the root node is the longest will be selected. Where the LCS has multiple paths to the root, the longer path is used for the purposes of the calculation.
Wu-Palmer相似度:根据分类中两个词义的深度及其最不通用归类(最特定祖先节点)的深度,返回一个分数,表示两个词义的相似程度。 请注意,此时给出的分数始终与Pedersen的Wordnet相似性的Perl实现所给出的分数一致。
LCS不一定是连接这两种感觉的最短路径,因为按照定义,它是分类学中最深的,不是最接近这两种感觉的共同祖先。 但是,通常情况下,它将具有这种功能。 在存在多个LCS候选者的情况下,将选择到根节点的最短路径最长的候选者。 如果LCS具有到根的多个路径,则较长的路径用于计算目的。
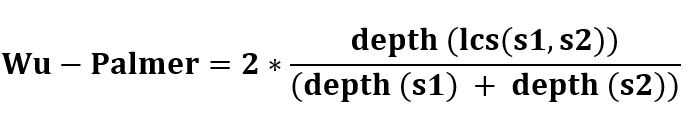
它通过考虑WordNet分类法中两个同义集的深度以及LCS(最小公共消费者)的深度来计算相关性。分数可以为0 <分数<=1。分数永远不会为零,因为LCS的深度永远不会为零(分类根的深度为1)。它根据单词含义的相似程度以及上位词树中同义词集相对于彼此出现的位置来计算相似度。 - res_similarity
synset1.res_similarity(synset2, ic): Resnik Similarity: Return a score denoting how similar two word senses are, based on the Information Content (IC) of the Least Common Subsumer (most specific ancestor node). Note that for any similarity measure that uses information content, the result is dependent on the corpus used to generate the information content and the specifics of how the information content was created.
Resnik相似度:基于最小公有购买者(最特定祖先节点)的信息内容(IC),返回表示两个词义相似程度的分数。 注意,对于使用信息内容的任何相似性度量,结果取决于用于生成信息内容的语料库以及如何创建信息内容的细节。

- jcn_similarity
synset1.jcn_similarity(synset2, ic): Jiang-Conrath Similarity Return a score denoting how similar two word senses are, based on the Information Content (IC) of the Least Common Subsumer (most specific ancestor node) and that of the two input Synsets. The relationship is given by the equation 1 / (IC(s1) + IC(s2) - 2 * IC(lcs)).
Jiang-Conrath相似度返回一个分数,该分数基于最小公有使用者(最特定祖先节点)和两个输入同义词集的信息内容(IC)来表示两个词义的相似程度。 。 该关系由等式1 /(IC(s1)+ IC(s2)-2 * IC(lcs))给出。 - lin_similarity
synset1.lin_similarity(synset2, ic): Lin Similarity: Return a score denoting how similar two word senses are, based on the Information Content (IC) of the Least Common Subsumer (most specific ancestor node) and that of the two input Synsets. The relationship is given by the equation 2 * IC(lcs) / (IC(s1) + IC(s2)).
Lin相似度:根据最不常见消费方(最特定祖先节点)和两个输入同义集的信息内容(IC),返回表示两个词义相似程度的分数。 该关系由等式2 * IC(lcs)/(IC(s1)+ IC(s2))给出。
















 4507
4507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









