







Python爬取猪肉价格信息
写这篇文章主要是分享一下爬取价格信息、股市信息、天气信息等的经验。欢迎各路大神前来指教,我就是个小菜鸡。
前言
因为之前做的一次数模比赛,其中一道题目需要在猪价网https://zhujia.zhuwang.cc/爬取猪肉的价格信息,当时真的一点儿思路都没有。在这次春节期间,由于疫情的原因所以也一直去不了学校,就在家里看了很多东西,看了微信小程序,Android Studio,html5,css, json,JavaScript,当然很多都是草草的浏览了一下,没有留下很多印象,毕竟以后我应该也不会用到,只是知道有这么个东西。但我觉的并不是说我用不到就不需要了解,因为很多知识都是相互联系的,正是这段时间我看的这些东西,给了我一些启发。
在前端开发中,本人绝对是个外行,只是知道有html5、javascript、css这么个东西,但对他们的工作原理确是一概不知。以前看爬虫的时候不了解html等相关知识,以至于之前自己写的爬虫程序也就只能爬爬网络小说啥的,那速度不用说了,像蜗牛在爬,还老报错。
这段时间才刚刚了解到网页中的很多信息都是存储在JSON文件中进行传输的,例如价格网站的价格数据,天气网站 的天气数据都是存储在JSON中的。所以只要我们能够GET到所需的JSON,就能解析出相关数据。了解到这一点,要爬取猪肉的价格信息就小菜一碟了。
在这里我就以爬取猪肉价格为例和大家分享一下我的经验,希望能够帮助到有需要做这方面爬虫的人,同时也希望有大神能来给我指点指点迷津。
网页分析
我们以猪价网全国猪价为例,我们要爬取的就是一年以来,猪肉的价格变化。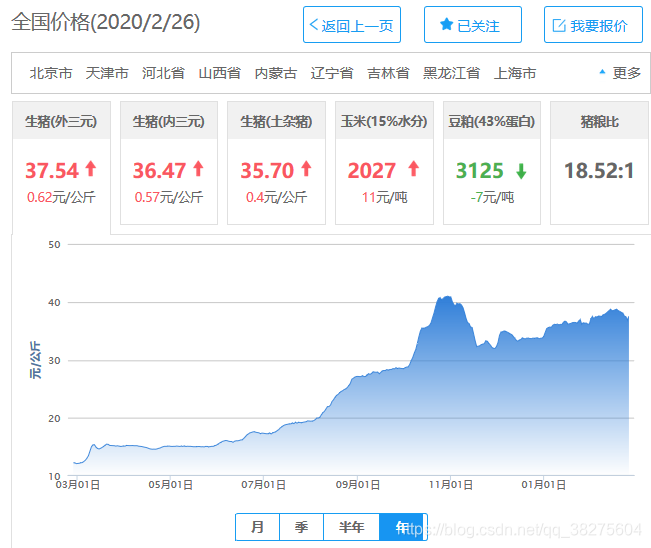
我们可以在网站的主页上看到猪价的走势图,作为一个小菜鸡,当初一直以为猪价信息就包含在图表中,所以废了很长时间也没有找到。其实上图图表只是通过JavaScript调用了猪价信息数据,我们去网页的所有数据文件中去查找JSON格式的文本,就能够找到了猪价数据了。
这里我暂时没去管是如何调用的,毕竟我也不是做前端的,这里我只教大家如然后找到相应的数据。在浏览器界面点击F12进入开发者窗口,选择网络选项卡。按F5刷新界面,即可查看到浏览器获取到到的所有数据,如下图所示,其中箭头所指,名为chartData的html文件,包含了存储表格数据的JSON格式文本。
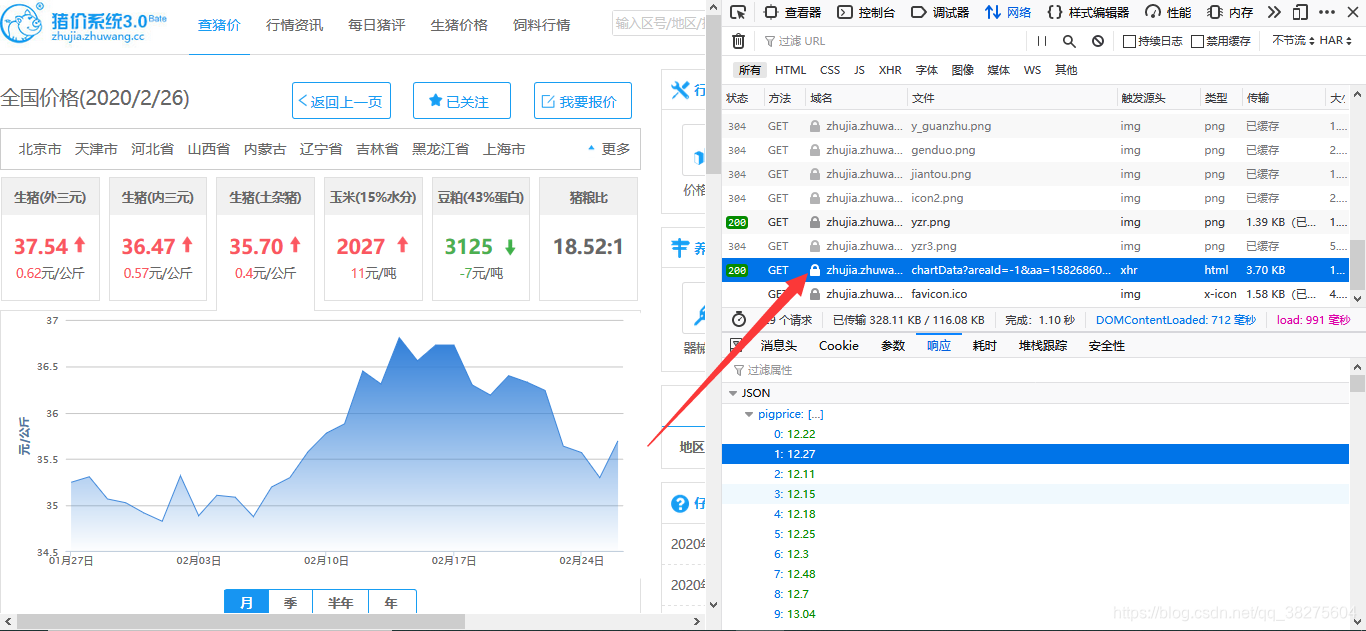
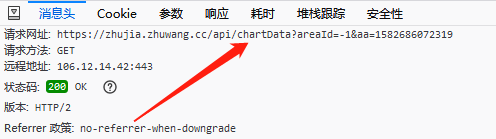
接下来我们需要看浏览器是如何获取到这段html代码的,点击箭头所指的html文件可查看详细信息,如下图,具体的意思就是,我们通过GET方法访问请求网址,就能得到chartData文件。
Python代码解析
构造请求url
我们来分析一下图中请求地址:https://zhujia.zhuwang.cc/api/chartData?areaId=-1&aa=1582686072319
- 其中https://zhujia.zhuwang.cc/api/chartData是原始网址
- ?areaID=-1意思判断用户选择的区域,-1代表了全国数据
- &aa=后面的一长串数字代表了请求发出时时间信息
我们要获取的就是全国数据,所以areaID不用改,我们只需要更改代表请求时间的字符串。
这里我们可以导入time模块,利用 **int(time.time()*1000)**计算的得到包含时间信息的字符串,同时我们导入requests模块,json模块,利用requests模块发起get请求,利用json解析数据
import time
# 构造请求网址url
url = "https://zhujia.zhuwang.cc/api/chartData?areaId=-1&aa=%d"% int(time.time()*1000)
发起get请求
# 构造请求头,有效避免发爬虫
header = {'User-Agent': 'Mozilla/5.0'}
# 获取json文本
html = requests.get(url, headers=header).text
解析json
通过**json.loads()**方法将html文本加载成json格式
j0 = json.loads(html)
在解析json文本的过程中,我们了解json文本的构成,这样才能找到在大量的信息中找到我们需要的信息。在这里我给大家推荐一个可以通过视图查看json格式文本的网址,JSON在线视图查看器。
通过将将文本复制到该网址中,可以查看到JSON视图,如图所示。
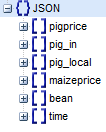
接下来我们对利用json模块进行解析,同时利用matplotlib绘制猪价走势图,同时保存猪价到文本中
priceList = []
print(j0.keys())
if not os.path.exists("猪肉价格"):
os.mkdir("猪肉价格")
# j0['pig_in'][i], j0['pig_local'][i], j0['maizeprice'][i], j0['bean'][i]
for item in j0:
if item != "time":
f = open("猪肉价格/"+item+'.txt', 'w+')
for i in range(366):
f.write("%.2f\n" % float(j0[item][i]))
f.close()
plt.figure(item)
plt.title(item)
plt.plot(j0[item])
plt.xlabel("时间")
plt.ylabel("元/公斤")
plt.xlim([0, 366])
plt.savefig("猪肉价格/"+item + '.png', dpi=600)
else:
f = open("猪肉价格/"+item+'.txt', 'w+')
for i in range(4):
for j in range(3):
f.write("%s" % j0[item][i][j])
f.write("\n")
总结
完整代码
import matplotlib.pyplot as plt
import numpy as np
import json, time, requests, os
url = "https://zhujia.zhuwang.cc/api/chartData?areaId=-1&aa=%d"% int(time.time()*1000)
header = {'User-Agent': 'Mozilla/5.0'}
html = requests.get(url, headers=header).text
j0 = json.loads(html)
priceList = []
print(j0.keys())
if not os.path.exists("猪肉价格"):
os.mkdir("猪肉价格")
# j0['pig_in'][i], j0['pig_local'][i], j0['maizeprice'][i], j0['bean'][i]
for item in j0:
if item != "time":
f = open("猪肉价格/"+item+'.txt', 'w+')
for i in range(366):
f.write("%.2f\n" % float(j0[item][i]))
f.close()
plt.figure(item)
plt.title(item)
plt.plot(j0[item])
plt.xlabel("时间")
plt.ylabel("元/公斤")
plt.xlim([0, 366])
plt.savefig("猪肉价格/"+item + '.png', dpi=600)
else:
f = open("猪肉价格/"+item+'.txt', 'w+')
for i in range(4):
for j in range(3):
f.write("%s" % j0[item][i][j])
f.write("\n")
结果
原图未加工有点丑,不想看到直接略过吧。
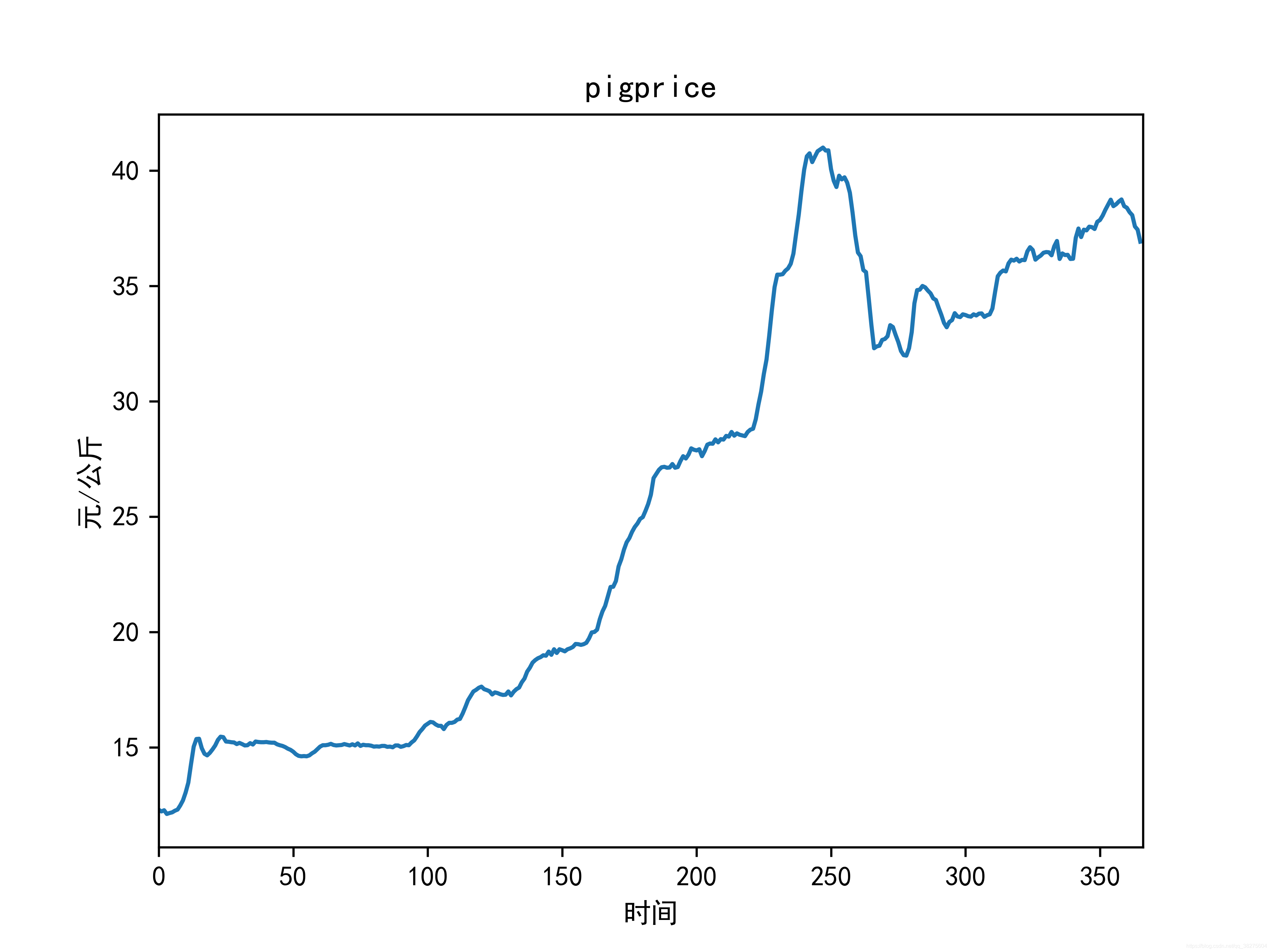
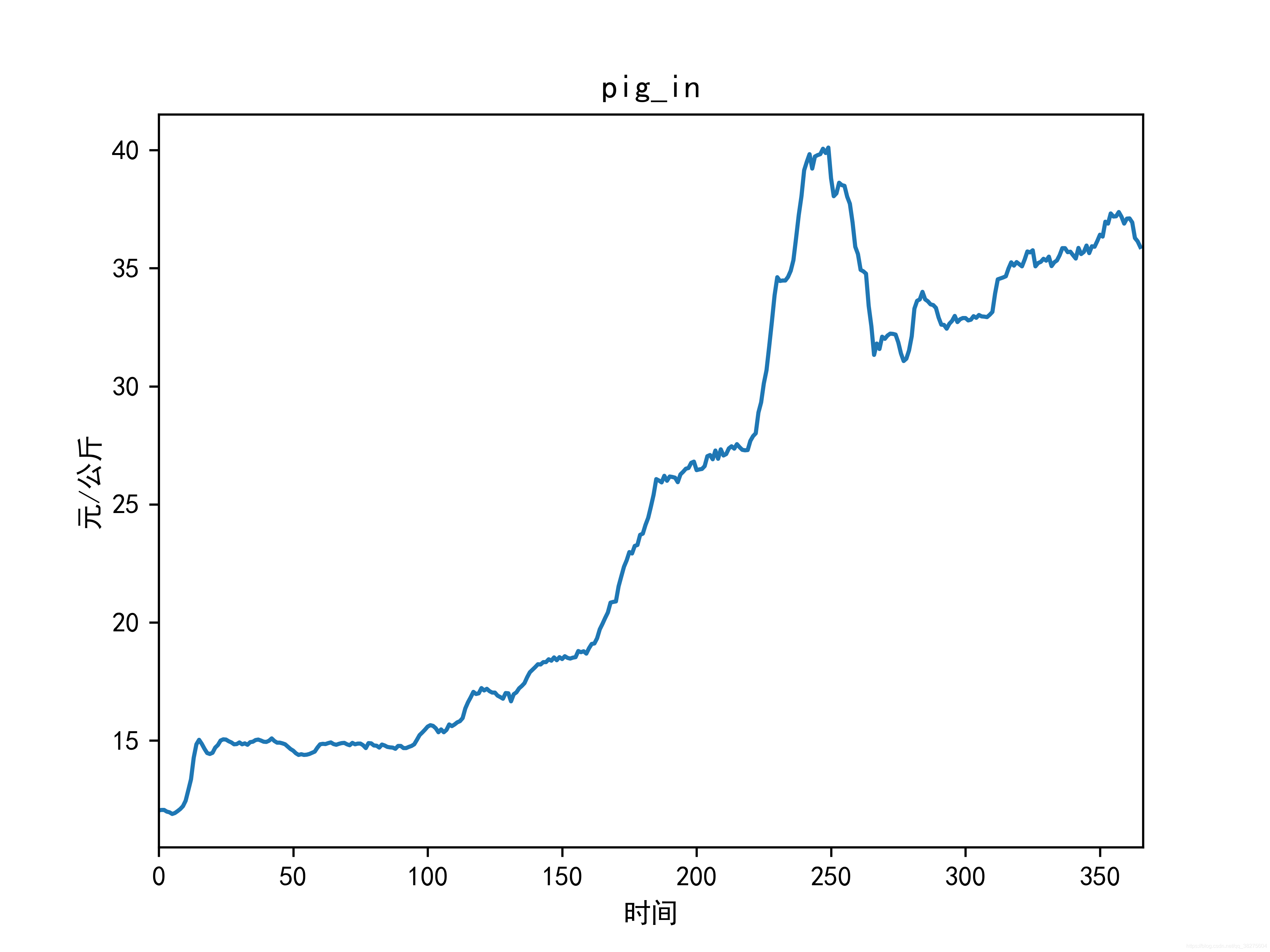
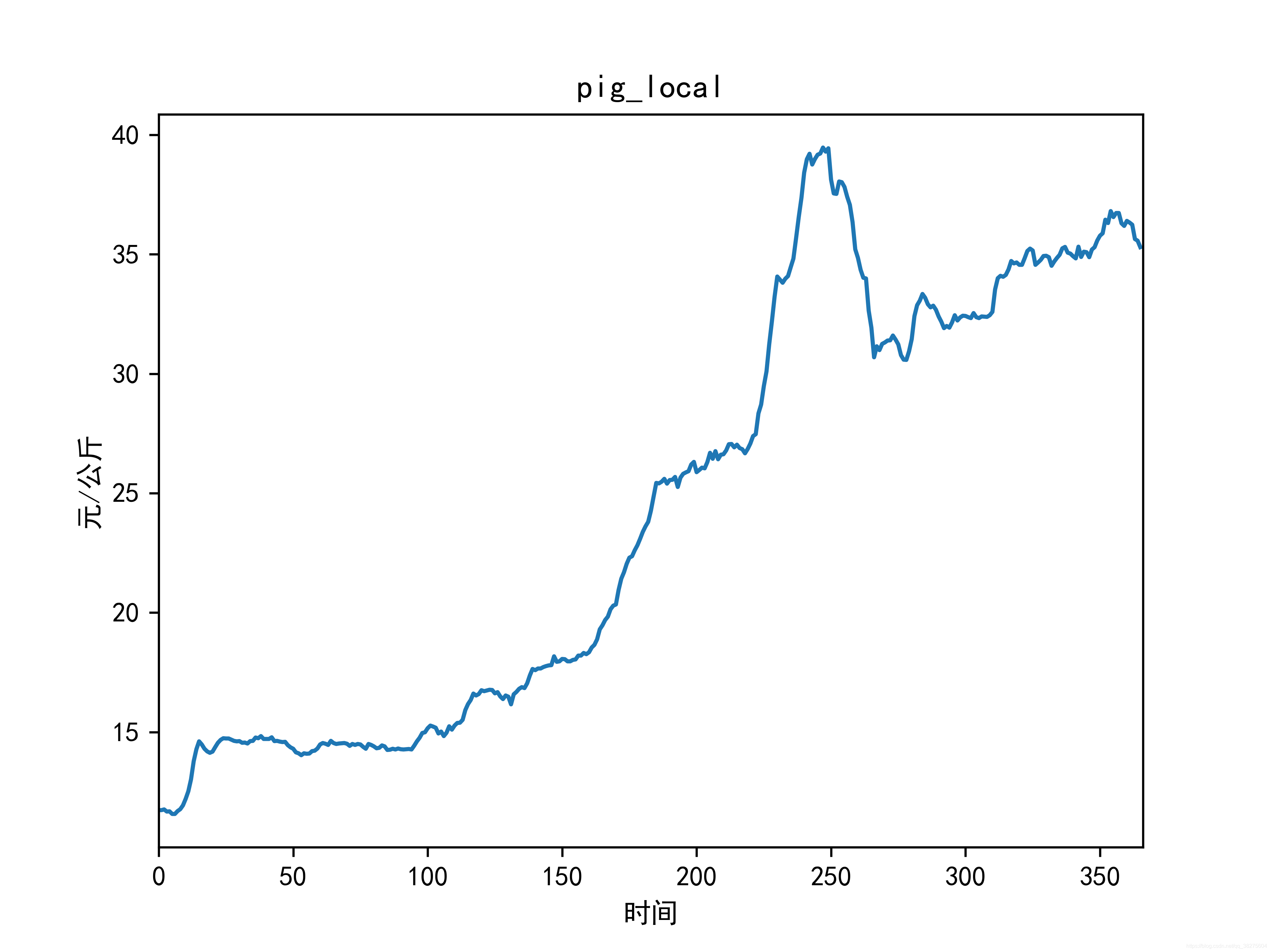
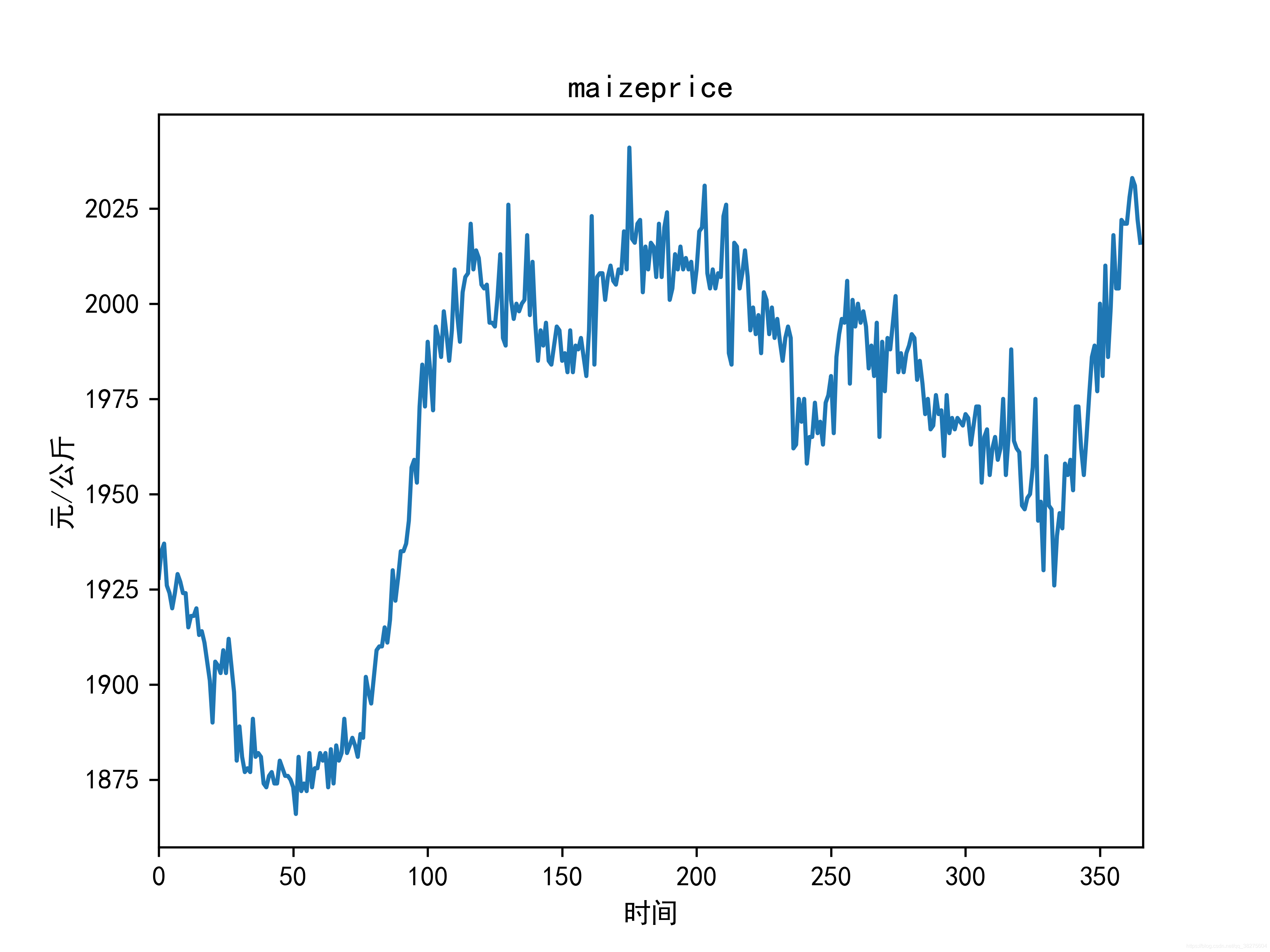
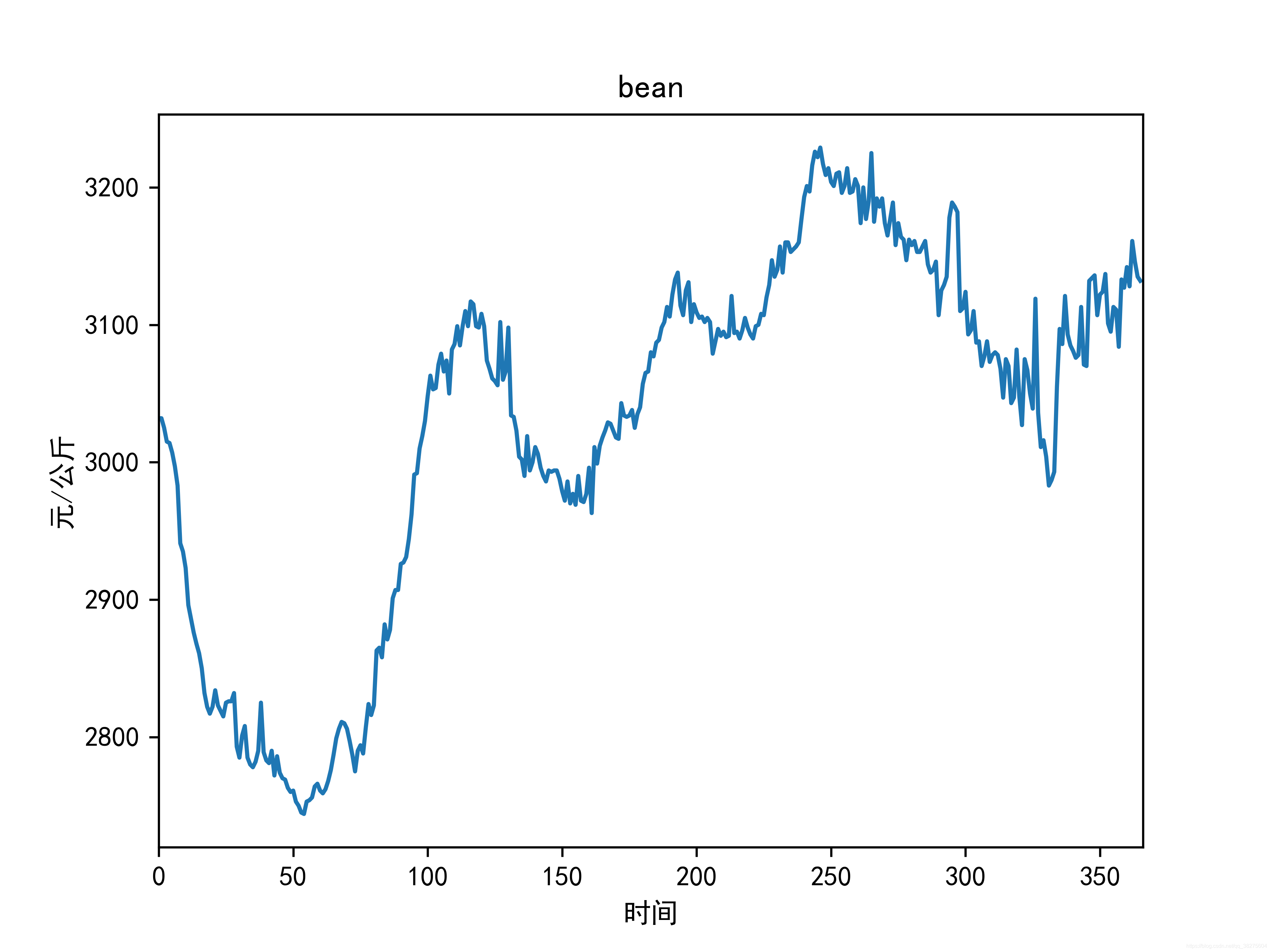 终于结束了,希望大家多多支持!!欢迎交流!!
终于结束了,希望大家多多支持!!欢迎交流!!


















 1204
1204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











